On Monday, May 25 (Whit Monday), the Library will be open during regular hours, from 7 a.m. to midnight.
Swiss negotiations with publisher Springer Nature: No-deal situation as of January 2026
More information
More information
Located at the Rolex Learning Center, the EPFL Library is open 7/7, from 7am to midnight, and is accessible to everyone.


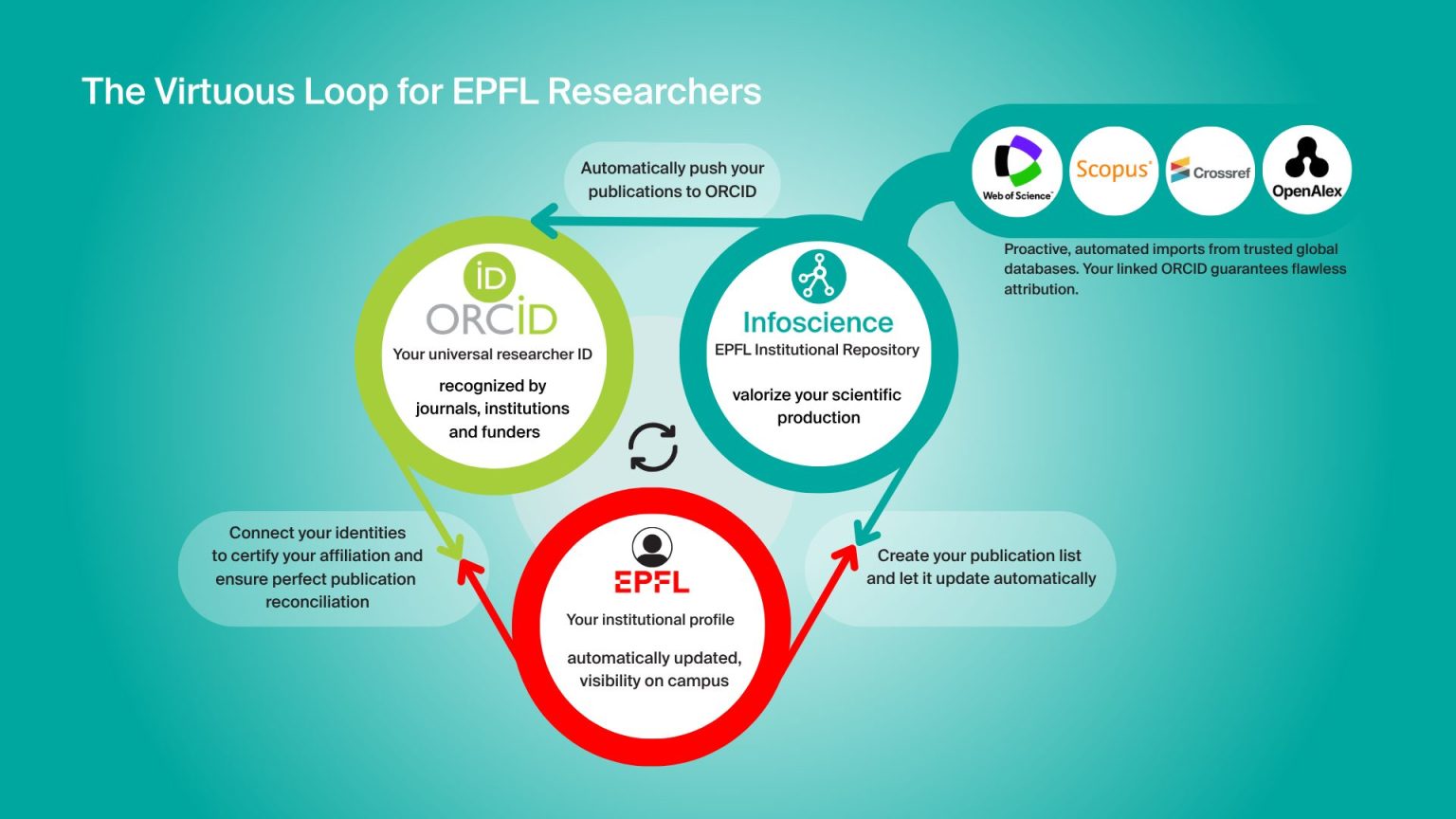
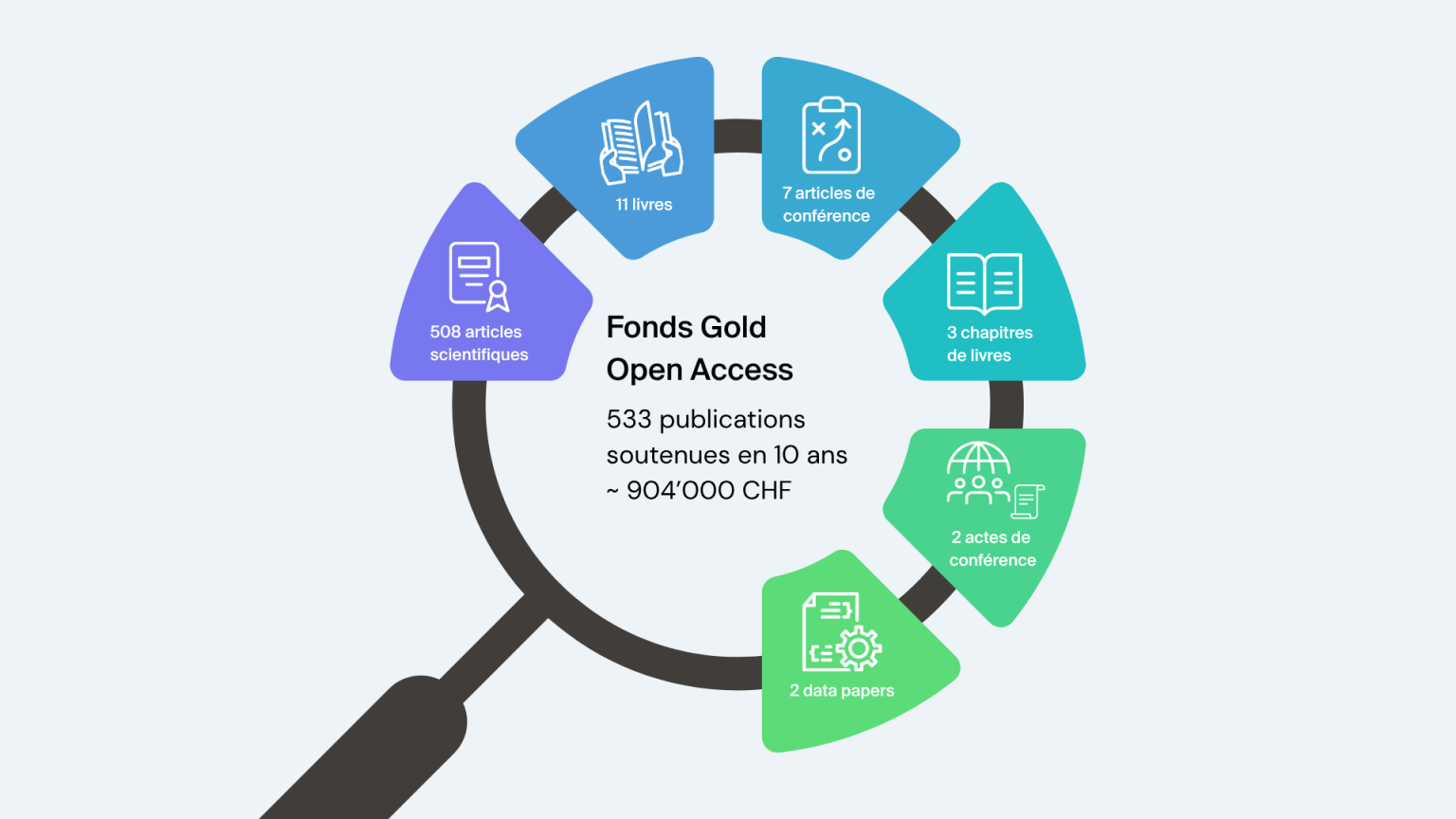
Next events and training programs


Lunch Talks "AI and Ethical Scientific Practices"
26.05.2026 12:1513:45
Speaker: Orr Paradise; Gaia Barazzetti; Valentin Conrad; Pablo Diaz; Cécile Hardebolle
Location: BM 5202
Category: Conferences – Seminars
Target audience: General public

Training "Reshaping Information Research with AI"
02.06.2026 10:0012:00
Speaker: EPFL Library Training Team
Location: GR A3 31
Category: Internal trainings
Target audience: General public

Training "Smart Publishing"
23.06.2026 10:0012:00
Speaker: EPFL Library Training Team
Location: MED 0 1418
Category: Internal trainings
Target audience: General public




















For researchers and PhD students

Our services

Publishing support

Research data management

Open Science

Associated campuses




Last news



Contact
Opening hours
7/7, 7am-midnight
Services at the desk
mon-fri: 8am-11:45pm
sat-sun: 9am-11:45pm
7/7, 7am-midnight
Services at the desk
mon-fri: 8am-11:45pm
sat-sun: 9am-11:45pm