Publishing
At EPFL, the Library Research Data Management team is at your disposal to provide you with expert advice, support, and solutions. This section introduces you to the various forms of data publication (data platforms and/or data journals) with some helpful tools and two useful tables for the most used platforms and journals at the EPFL.
To make your data or code visible and openly available, you should publish them in a citable form, which preserves and enables access to this type of research output.
Indeed, many funding agencies, including the SNSF, expect its funded researchers to deposit their data and metadata onto existing public repositories in formats anyone can find, access, and reuse without restriction.
Data publication
There are essentially two ways to publish your research data:
Data dissemination platforms
There exist various types of data (and code) dissemination platforms. You can find here below definitions and examples for the main types of platforms used to disseminate research data or code.
- In short: Commercial or institutional online platforms allowing to store, version, publish, retrieve and collaborate on active code
- Extended: Online platform that simplifies the version control of code, allowing developers to submit patches of code in an organized, collaborative manner. It can also be used for backup of the code. Sometimes it acts as a web hosting service where developers store their source code for web pages. Often, source code repository software services and websites support bug tracking, mailing lists, version control, documentation, and release management. Developers generally retain their copyright when software is posted to a code hosting facility and can make it publicly accessible.
- Some examples: GitHub, GitLab EPFL, etc.
- Not for: Code repositories are not usually designed for data/code preservation nor for data analysis purposes.
- In short: Institutional or commercial online platform allowing to aggregate, combine, analyze and visualize active datasets (data and/or code)
- Extended: Online platform used to perform analysis, retrieve, combine, interact with, explore, and visualize data. The underlying data can originate from various sources (e.g. data banks, user-provided, API, etc.), online or offline. The main scope of a data analysis platform is to turn every data into actionable insights, other than overcoming possible inadequacies of a relational database or table. As these platforms embed the tools for accomplishing meaningful data transformations, they are usually focused on specific research domains, and use consequent formats, algorithms, and processes. Others, especially the ones used for code scripts, can be more generic.
- Some examples: Renku, ELN EPFL, Open Data Cube, etc.
- Not for: Data analysis platforms are not usually designed for data preservation nor for data publication purposes.
- In short: Mostly institutional online platforms allowing to preserve and retrieve cold data
- Extended: Storage infrastructure enabling the long-term retention and reusability of data. Provides secure, redundant locations to securely store data for future (re)use. Once in the archived data management system, the data stays accessible and the system protects its integrity. A data archive is a place to store data that is deemed important, usually curated data, but that doesn’t need to be accessed or modified frequently (if at all). Most institutions use data archives for legacy data, or data of certain value, or to meet regulatory standards. Data are not usually findable by external users.
- Some examples: ACOUA, ETH Data Archive, OLOS, etc.
- Not for: Data archives are not usually designed for data publication nor for data analysis purposes.
- In short: Institutional or commercial online platforms allowing to store, aggregate, discover, and retrieve cold data
- Extended: Collection of datasets for secondary use in research that allows processing many continual queries over a long period of time. Not to be confused with the organizations concerned with the construction and maintenance of such databases. Services and tools can be built on top of such a database, for development, compilation, testing, verification, dissemination, analysis, and visualization of data. Normally part of a larger institution (academic, corporate, scientific, medical, governmental, etc.) is established to serve the data to users of that organization. A data bank may also maintain subscriptions to licensed data resources for its users to access the information.
- Some examples: DBnomics, Channelpedia, DataLakes, etc.
- Not for: Data banks are not usually designed for data preservation nor for data analysis purposes.
- In short: Institutional or commercial online platforms allowing to preserve, publish, discover and retrieve cold datasets (data and/or code)
- Extended: Online infrastructure where researchers can submit their data. Allows to manage, share, and access datasets for the long term. Can be generic (discipline-agnostic) or specialized (discipline-specific): specialized data repositories often integrate tools and services useful for a discipline. The main purpose is to preserve data to make it reusable for future research. Data repositories may have specific requirements concerning: research domain; data re-use and access; file format; data structure; types of metadata. They can also have restrictions on who can deposit data, based on: funding; academic qualification; quality of data. Institutional data repositories may collect a university or consortium of university researchers’ data.
- Some examples.: Zenodo, Materials Cloud, Dryad, etc.
- Not for: Data repositories are not usually designed for data analysis nor for code versioning purposes.
Data journals
If you want to highlight the importance of your data and make sure that they are cited, you might also consider writing a data paper, i.e. a peer-reviewed paper describing a dataset as research output.
Data journals allow focusing on the description of the data, its context, the acquisition methods, as well as its actual and potential use (rather than presenting new hypotheses or interpretations).
As data journals are always Open Access, an Article Processing Charge (APC) has to be paid by the author for the publication costs. It is possible to request the Library’s financial support to cover part of the APC.
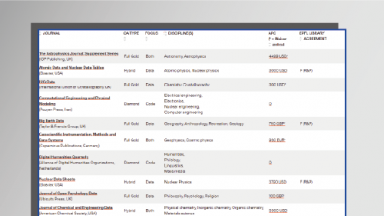
Some examples:
- Scientific Data (Springer Nature Group)
- Data in Brief (Elsevier)
- Journal of Physical and Chemical Research Data (AIP)
- Journal of Open Research Software (Ubiquity Press)
- GeoScience Data Journal (Wiley)
Finding the right one
When choosing the platform or journal that best fits your needs, consider the following elements:
- Check funders’ requirements and recommendations;
- Prefer platforms providing persistent IDs (DOI, for instance);
- Check compliance with your data protection and licensing requirements, if applicable(see also here);
- Look for certification as a trustworthy digital platform if possible: this ensures data preservation in the long term;
- Disciplinary repositories are generally a good choice, for directly reaching target communities and peers. However, they require a lot of resources (human, machine, time) and do not always meet interoperability standards;
- Multi-disciplinary repositories accept any type of data and enable broader visibility and interoperability. However, they do not target specific communities and therefore are not the reference in those fields.
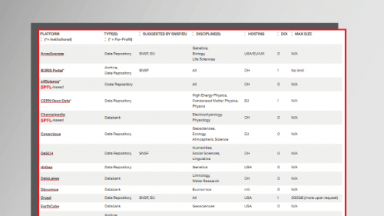
A great resource to identify the good repository is re3data (see also below).
Also check the list of FAIR repositories provided by the HES·SO.
Zenodo at EPFL
Zenodo is a general-purpose, free and open-access repository operated by the European Organization for Nuclear Research (CERN). It allows researchers in any subject area to deposit data sets, research software, reports, and any other research-related digital artifacts.
We encourage EPFL researchers to submit datasets, code and other outputs to the EPFL collection on Zenodo. We will review all submissions and send our feedback to the authors. When essential criteria are met, we will accept the submission and create an Infoscience record for EPFL web pages, annual reports, etc. Furthermore, if possible, we will archive the files in ACOUA for long-term preservation. Please note that it can be better to submit your dataset to the EPFL collection after you have made the record public, otherwise it might remain hidden until our curation is completed.

Zenodo and the EPFL community
Follow our complete guide here to upload your datasets to Zenodo in the EPFL community
Archiving
Long-term preservation should be planned from the beginning of the project.
The Data Management Plan is a useful tool to describe the preservation strategies that the researchers would like to put in place and to make monitoring during the project lifespan easier.
In order to preserve data correctly, appraisal and selection are needed to determine which data will be ultimately devoted to long-term conservation or eliminated, how long, in which format, and where.
This page focuses on the institutional archive made available at the EPFL, but other tools exist, depending on your needs.
ACOUA
For the long-term preservation of research data and code, the EPFL community benefits from ACOUA, the institutional archive managed by EPFL Library in partnership with the Information Systems (VPO-SI).
Data preservation does not only mean storing data safely, but it also implies that data will remain accessible and reusable in the long term (for several years or even forever) ensuring:
- Intellectual interpretability (by providing sufficient metadata and documentation)
- Technical readability (by using for example appropriate formats)
- Integrity (by replication of the data and checksum usage)
Why archiving research data
Why using ACOUA
There are many instances where you or your research group should use ACOUA to preserve your relevant research data:
- archive the entirety of a dataset underlying your publication
- archive datasets of a finished research project
- archive datasets of a collaborator leaving EPFL
- get space for large datasets that need preservation
- preserve reference raw data useful during your research
- get expert support for data curation
What you get
In addition to the proper digital infrastructure, we also offer professional and tailored support:
- trustworthy, safe and EPFL-backed environment
- free for EPFL researchers
- up to 10TB per archived dataset
- help in data curation prior to archival
- periodic integrity audits and curation actions of your datasets
- periodic reports on the state of your preserved datasets
- referral of your datasets on Infoscience
- possibility to publish your datasets for you on Zenodo (size limits)