Research LineThermal modelling |
Team
 | Atienza Alonso David |
 | Medina Morillas Rafael |
 | Zapater Sancho Marina |
Research Partners
 | ETHZ |
 | University of Bologna |
Sources of Funding
| Compusapien |  |
| Eurolab4HPC2 |  |
| Nano-Tera |  |
| RECIPE H2020 |  |
| WiPLASH H2020 |  |
| Fvllmonti |  |
Emergence of cloud computing as a dominant scalable computing platform has changed the computing requirements for global online services. This has led to new applications that broadly fall into two categories; scale-out workloads and latency-critical high-performance computing (HPC) applications. Both types of applications have their own computing characteristics, but they have some common characteristics as well. Both have very large operating data sets that cannot fit on the on-chip caches and usually require to access data from the memory frequently. Secondly, both should meet the quality-of-service (QoS) or latency requirements.
The push to integrate many-cores on single chip, made possible due to Dennard Scaling, to increase the computation power, has hit the power-wall. Heterogeneous multi-core architectures have helped to push back the power-wall and overcome the dark silicon problem, but to a limited extent. On the memory side, current trends in increasing the computational performance and efficiency cannot make significant levels of progress without overcoming the memory wall problem. State-of-the-art emerging memory technologies, like 3D stacked die memories and Non-Volatile-Memory (NVM) are being researched as an alternative to traditional memories with magnitudes of improvement in bandwidth.
Goal:
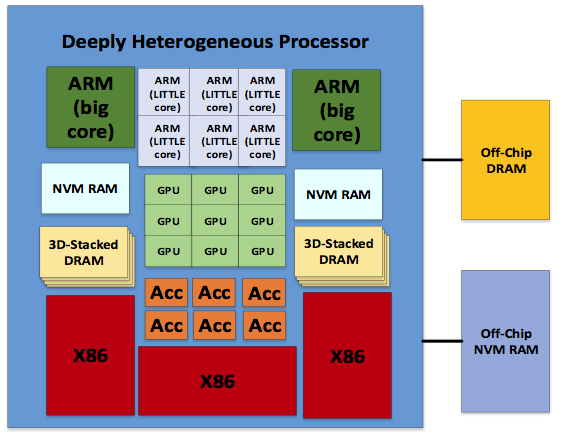
At ESL, we are exploring novel heterogeneous architectures, which are energy-efficient and high performance, for both scale-out and emerging HPC applications, as they share common computing characteristics. Our research work, explores heterogeneity at all levels of the computation. This includes micro-architectural heterogeneity (in-order core, out-of-order cores), ISA level heterogeneity (mix of x86, ARM and MIPS), functional heterogeneity comprising of a mix of CPU, GPU and accelerator cores and lastly a deeply heterogeneous architecture combining all the heterogeneous levels mentioned above. The design decisions for a particular architecture are guided by energy-efficiency and also performance per watt. In addition to heterogeneous computing architectures, we are also exploring heterogeneous memory architectures to attack the memory wall. This will include integrating emerging memory technologies like 3D stacked DRAM like Hybrid Memory Cube (HMC) and NVMs with existing SRAM and DRAMS. Industry and research communities have optimized compute cores and memory separately. We are also exploring processor-in-memory (PIM) and near-data-computing architectures to reduce the latency between compute and memory nodes. The challenges involved in the design for heterogeneous memory architectures include memory management and programming challenges. Heterogeneous computing architectures along with a heterogeneous memory architecture as shown in the Figure, will provide magnitude improvement in energy-efficiency and performance for new emerging latency-critical applications.
Methodology and software tools:
To perform architectural exploration, simulation framework based on GEM5 is used. GEM5 is a cycle accurate simulator which supports different ISAs (like x86, ARM, ALPHA, MIPS, POWER, SPARC) and has multiple CPU simulation models like the simple atomic model, in-order and out-of-order (OoO) CPU model. GEM5 supports multiple cache coherence protocols and interconnect models. It also has models for different memory devices including traditional memories (DDR) and emerging memories (HMC). GEM5 supports booting Linux in full system simulation mode for ARM, x86 and ALPHA ISAs.
To have a realistic view and confidence in our simulation framework, we validated ARM-based simulation in GEM5 against Cavium ThunderX, which is an ARM-based server.
Related Publications
| System-Level Exploration of In-Package Wireless Communication for Multi-Chiplet Platforms | |||||
| Medina Morillas, Rafael; Klein, Joshua Alexander Harrison; Ansaloni, Giovanni; Zapater Sancho, Marina; Abadal, Sergi; Alarcón, Eduard; Atienza Alonso, David | |||||
| 2023 | Conference Paper | | | ||
| Full System Exploration of On-Chip Wireless Communication on Many-Core Architectures | |||||
| Medina Morillas, Rafael; Klein, Joshua Alexander Harrison; Qureshi, Yasir Mahmood; Zapater Sancho, Marina; Ansaloni, Giovanni; Atienza Alonso, David | |||||
| 2022 | Conference Paper | | | | |
| Genome Sequence Alignment - Design Space Exploration for Optimal Performance and Energy Architectures | |||||
| Qureshi, Yasir Mahmood; Herruzo, Jose Manuel; Zapater, Marina; Olcoz, Katzalin; Gonzalez Navarro, Sonia; Plata, Oscar; Atienza Alonso, David | |||||
| 2020 | IEEE Transactions on Computers | | | | |
| Towards Near-Threshold Server Processors | |||||
| A. Pahlevan, J. Picorel Obando, A. Pourhabibi Zarandi, D. Rossi and M. Zapater Sancho et al. | |||||
| 2016 | Design, Automation and Test in Europe Conference (DATE), Dresden, Germany | | |||