Research LineIn and near-memory computing |
Team
 | Ansaloni Giovanni |
 | Atienza Alonso David |
 | Levisse Alexandre Sébastien Julien |
 | Ponzina Flavio |
 | Rios Marco Antonio |
 | Simon William Andrew |
Sources of Funding
| Compusapien |  |
| RECIPE H2020 |  |
| WiPLASH H2020 |  |
In-Memory Computing (IMC) is a new computation paradigm that proposes to execute operations inside the memory, targeting to maximize the energy efficiency of systems by avoiding data transfers, a very energy-consuming operation. This statement becomes even more evident in data-intensive applications, as for the machine learning algorithm Convolution Neural Networks (CNNs). These applications have millions or even billions of parameters, that are constantly read during an inference.
In the Embedded Systems Laboratory (ESL), we have developed a new IMC architecture based on bit-line computing: Bitline Accelerator for Devices on the Edge (BLADE) [1]. We have presented variants of this architecture as well, as the non-volatile IMC architecture that employs Weight Data Mapping [2]. An innovative way to store and access data on the subarrays. More recently, we modified the architecture so the CNN kernel is streamed bit-by-bit to the memory and we have shown how different levels of CNN kernel quantization increase the performance and energy efficiency, without loss of accuracy.
However, as the IMC architectures present unique features to perform operations, as multiplications and convolutions, the algorithm must differ from what is commonly used in CPUs or GPUs. In fact, the solutions must be customized regarding both the architecture and the application, so the efficiency of such a system is maximized. Therefore, we developed a cycle-accurate simulator able to model the execution of entire CNN inferences (i.e. pooling, convolutional, and fully connected layers) using the BLADE architecture or its variants.
To this end, we assume a simple run-time behavior in which the inputs to each CNN layer are streamed to the memory. Then IMC operations are performed to compute the outputs and, finally, these are read back. Based on the geometry of the kernel and the subarray capacity, the simulator tiles the input data and distributes the tiles to different subarrays, as Fig. 1 shows. Moreover, if the number of tiles exceeds the number of subarrays (a common occurrence for large feature maps), multiple rounds are performed for a single layer. Similarly, large convolutions exceeding the available memory capacity are decomposed into partial ones.
The simulator allows the analysis of the impact on the performance and energy of the macro memory size and the internal parameters of each subarray. As the total IMC operation to complete a CNN inference depends on the number of subarrays on the system, while the size of each subarray impacts how the operation is distributed.
[1] https://infoscience.epfl.ch/record/274287
[2] https://infoscience.epfl.ch/record/281951
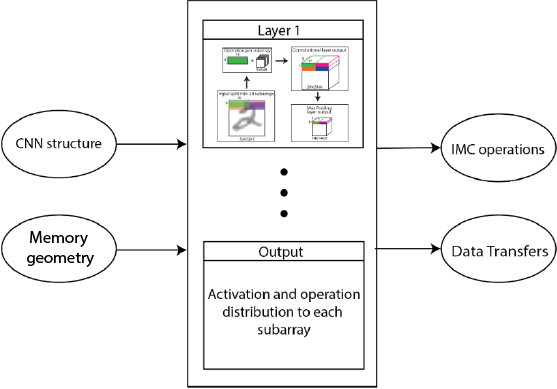
Example of simulator. For each layer, the software calculates the cycles required to perform the IMC operations.