Central Processing Units (CPUs) have been the core processing engine on platforms for embedded computing for decades, due to their low cost and high flexibility. However, CPUs are slower and less energy-efficient compared to more specialized options such as FPGAs or ASICs. Such downsides are particularly challenging for highly demanding workloads, such as the ones from Machine Learning (ML) and Digital Signal Processing (DSP) applications. Overcoming these limitations is key for the deployment of ML and DSP in energy constrained environments, including the generations of autonomous wearable and implantable medical devices.
The Embedded Systems Laboratory (ESL) of EPFL is committed to the design of novel open-source computing accelerator paradigms dedicated to the above-mentioned scenarios. In this context, the proposed project will focus on a novel family of ultra-efficient reconfigurable hardware architectures, termed Coarse Grained Reconfigurable Array (CGRA). CGRAs are composed of 2-dimensional arrays of processing elements (PE), tightly integrated with each other, each capable of performing arithmetic and logic operations.
One of the key challenges when employing CGRAs is that of scheduling: to decide which instructions are to be executed by each PE at each cycle in order to implement a desired functionality. CGRA scheduling is particularly demanding, as it combines spatial (where to map an operation) and temporal (when to execute it) considerations.
For this reason, ESL is developing a CGRA simulator to allow developers to rapidly iterate over their code. Recent advances in this regard have provided the simulator with a timing and energy characterization of the OpenEdgeCGRA.
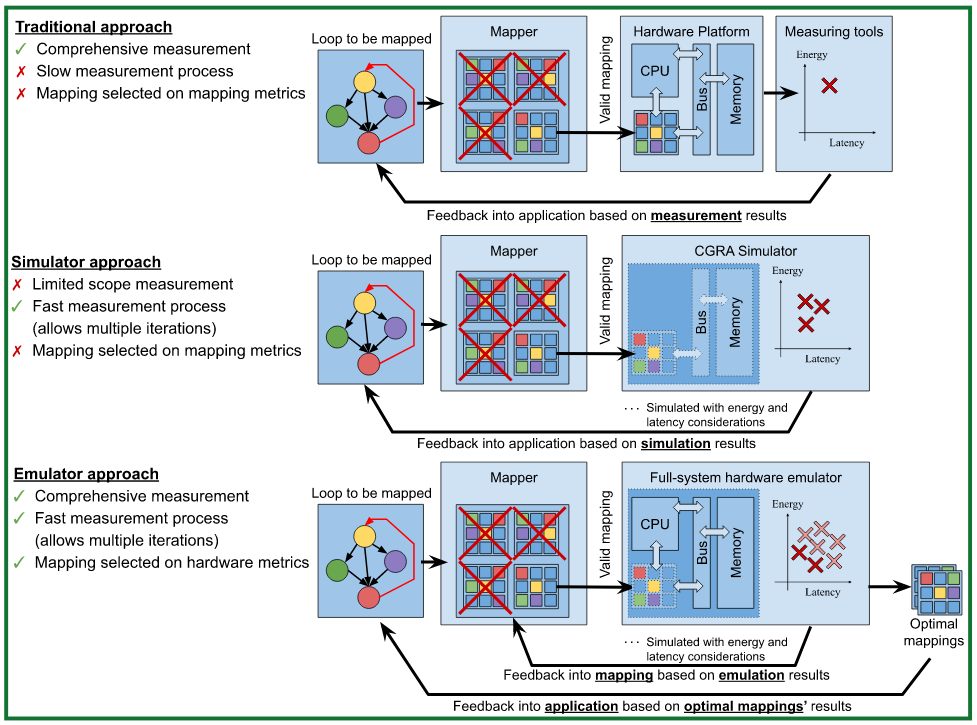
The traditional approach to accelerating applications on a CGRA involves extracting code initially intended to run on a host CPU, finding a valid mapping of the required operations into the CGRA resources, and measuring full-system performance in the hope that the overall energy and latency has decreased. Compilers embarking on this task usually employ compile-time metrics to drive the solution space. However, it has been shown that this does not necessarily reflect hardware results for a lack of architectural considerations. Furthermore, it has also been shown that the performance metrics of the CGRA need to span its interaction with the host system, as this interaction accounts for the major energy differences (e.g. the energy gains can be dominated by the reduction in memory loads and stores thanks to the CGRA’s data reuse).
This project aims to bridge the gap between the mapping algorithm and full-system metrics by introducing latency and energy estimations into the mapping loop. It will introduce a feedback step into the mapping exploration to drive the exploration through hardware metrics, resulting in mappings that are pareto-optimal.
This approach will offer better mappings in less time than the traditional approach by cutting the long measurement process and filtering out sub-optimal results. Additionally, it will provide a comprehensive estimation of energy that accounts for the full-system, in contrast to a solely CGRA simulation-based approach. In consequence, application-level exploration can be achieved with confidence that results are optimal and reliable.
Throughout the project, the student will:
- Understand the mapping and deployment process, from initial C-code to the measurement of hardware metrics through post-synthesis simulation.
- Modify existing tools to work together in a complete workflow.
- Validate their results against hardware measurements.
- Perform an example exploration showcasing the benefits of the resulting framework.
The project will be carried out at the ESL at EPFL. ESL is an active group (22 Ph.D. students among 45 members) involved in many research aspects. The student will be under the supervision of Mr. Juan Sapriza, Dr. Giovanni Ansaloni, and Prof. David Atienza.
Project objectives:
- Integrating the CGRA simulation (including the memory-associated costs) into the mapping loop
- Obtaining a full-system emulation to be integrated into the X-HEEP’s FEMU
- Integrating the full-system emulation into the mapping loop.
Required knowledge and skills:
- Understanding of time-multiplexed CGRA mapping
- Strong analytical skills
- Strong background in computer architecture and algorithms
- Python and git
Appreciated skills:
- Scientific curiosity, good communication skills,
Type of work:
40% research and theory analysis, 60% development and implementation
Contacts:
Juan Sapriza ([email protected]),
Dr. Giovanni Ansaloni ([email protected]),
Prof. David Atienza ([email protected])