Brian Sifringer – Robust Machine Learning Solution to Keyword Spotting in Speech
Recognition
 About : Logitech , Suisse
About : Logitech , Suisse
Description
My internship was done at Logitech from February 19th to August 17th 2018. Logitech is a well-known company for computer peripherals such as mice, keyboards and webcams. However, in the past years, they have expanded to video conference supply, smart home devices and also music with Ultimate Ears and Jaybird, or eSports with Astro and Logitech G. They pride themselves in offering some of the best products in their fields and aim for innovation in product design.
Our office, the CTO (Chief of Technology Office), are the first line of research at the innovation park to bring the company to the artificial intelligence era. The team contained the highest number of interns, approximatively 20, and their supervisors composed mainly of software engineers, data scientists and various engineering specialists. My work specifically was based on improving device’s speech command recognition in noisy and reverberated environments, i.e. far field audio. The goal was to use a machine learning framework to do end-to-end recognition, from audio to command, and keeping the model small for embedding purposes. Once my task was given, I was free to solve it however I seemed fit. This internship allowed me to make extensive use of literature, and solve the problem from A to Z. The supervisor followed my work closely on a weekly basis and we also reported monthly to other audio related companies or research institutes.
The project initially required the machine learning framework to be done with Convolutional Neural Networks (CNN). I had investigated and benchmarked many approaches including teacher/student models, distillation, multitasking and more. All of it was done with pyTorch as well as making use of a GPU farm with Docker and Kubernetes. These tools are very common in any company that work with machine learning. The path to solving the problem led to augmenting data with numerically simulated Room Impulse Responses (RIR) in C++ and suggesting a brand new model architecture. Working progressively as a team led us to realize weaknesses and drawbacks of CNNs and the original project, notably concerning keyword spotting in streaming audio. Before the internship was over, I was able to attend to this by implementing a bi-directional Long Short Term Memory (LSTM) neural network with Connectionist Temporal Classification (CTC) loss. The final result was in compliance with the requirements, as my colleague in the team, Vincent Pollet, was able to embed the model on a chip.

Figure 1: Based on the Teacher/Student approach, a regularizer is used during the student’s training. The different inputs allow the final model to act as a filter, while the size difference is intended for compression. With enough data, the smaller model is able to perform as well as it’s bigger counterpart.
——————————————————————————————————
Martino Milani – Data Science Internship (Topological Data Analysis, Machine and Statistical Learning)
 About : L2F, Suisse
About : L2F, Suisse
Description
I did my internship at Learn To Forecast (L2F), a startup based at the Innovation Park in Lausanne. L2F offers to its client companies consulting services, based on innovative and ad-hoc predictive analysis algorithms. The main areas where L2F is active are risk management, dynamic pricing, predictive maintenance, fraud detection, algorithmic trading. L2F also collaborates with the chair of Topology of EPFL to develop and improve predictive algorithms based on Topology, traditionally called Topological Data Analysis.
Due to the fact that the company is not very large in size, I was involved in almost every aspect of the company’s work. In March I joined a team of 4 people whose goal was to develop an automated trading system for a private client in Geneva. The first month I worked on data scraping, and in April I moved to code and backtest a new proposal that they gave me for a buy and sell strategy. When the system went online at the beginning of June, I helped a software developer at L2F to modify my code in order to adapt it from a backtesting system to a real-time system. The code that we modified was then implemented in the production code that went online in the beginning of June.
In June I joined another team working on a project for a multinational broker insurance company. I worked on this project for the rest of my internship until August. For this project I joined a different team, this time of 3 people. I was given the full responsibility of designing and the implementation of the algorithm whose aim was to estimate the market share of the client, while my two colleagues were working on producing a descriptive report on their data. I quickly learned a lot about Bayesian regression models and stochastic numerical algorithms (especially Markov Chain Monte Carlo algorithms), and successfully implemented ad-hoc Bayesian models in Python, plus working on some more traditional deep learning and machine learning algorithms.

On the left, the posterior probability distributions of 4 parameters of a Bayesian model I developed in L2F. On the right, the corresponding plots of the MCMC simulations used to obtain the such posterior distributions.
——————————————————————————————————–
Arnaud Pannatier – Développement d’un outil d’analyse de la capacité de prédiction du produit Caelum Cockpit
 About : Caelum Fintech, Suisse
About : Caelum Fintech, Suisse
Description
Caelum Fintech est une entreprise qui développe un produit qui aide les gestionnaires de fortunes à créer et adapter leur portefeuille en proposant une stratégie d’allocation d’actifs. Cet outil décrit à quel moment il faut changer la composition d’un portefeuille, passant par
exemple, d’un portefeuille composé principalement d’actions, à un portefeuille plus sûr, composé majoritairement d’obligations et de bons du gouvernement. Ces changements d’allocation du portefeuille ont pour but l’ « Absolute Return » c’est-à-dire d’essayer au mieux d’avoir toujours des performances positives.
Mon travail au sein de Caelum Fintech était de développer un outil d’analyse de la solution pour mettre en évidence sa capacité d’anticipation des mouvements du marché. Une des principales différences de la stratégie de Caelum Fintech avec la gestion « classique » est qu’elle utilise le risque comme un outil proactif de gestion. Les images qui suivent correspondent à l’outil que j’ai développé. Les données des trois graphiques du fond de la page sont générées aléatoirement pour des raisons de confidentialité. La performance du produit Caelum Fintech correspond par contre à la performance réelle.
La manière de le lire est la suivante : la ligne du bas de la page qui alterne les couleurs vertes, orange et rouge correspond à un indicateur de risque. Il est vert si la prime de risque est dilatée, c’est-à-dire que l’outil analyse que l’environnement est tel que prendre du risque rapporte suffisamment. Il est rouge si la prime de risque est compressée, c’est-à-dire que les positions risquées n’ont pas un rendement espéré suffisant par rapport à leur risque inhérent. À partir de cet indicateur de risque, l’outil va adapter les allocations du portefeuille, qui sont observables sur la graphique en barre au-dessus de la ligne du risque. Le graphique du centre décrit l’évolution du cumul de participation à la performance de chaque classe d’actif. Finalement mon outil permet de comparer la performance de la solution de Caelum Fintech à des courbes de références comme le S&P 500 (pour le cours du dollar). Cette comparaison est faite à la fois dans le graphique en ligne, mais également dans le tableau du sommet de la page. Ce tableau affiche la performance, la volatilité et le ratio de Sharpe. Les lignes sont organisées selon un classement particulier qui tient compte de ces trois facteurs.

Figure 1 : Outil de visualisation du produit qui montre tous les résultats de la solution.
————————————————————————————————————
Mariella Kast – Engineering Internship
![]() About : Akselos, Suisse
About : Akselos, Suisse
Description
I did my internship at the startup Akselos in the EPFL innovation park from the 1st of July to the 15th of September 2018. Founded in 2012, Akselos develops Digital Twin software and builds its own simulation platform for solid models. Thanks to their Reduced Basis (RB-FEA ) technology, Akselos Integra provides computational results significantly faster than other Finite Element solvers. While Akselos’ software can be used in a wide variety of applications, the current focus lies on offshore structures for the Wind energy and Oil & Gas industry.
As an intern, I was integrated with the development team and had the chance to see the whole workflow of implementing a new feature into the simulation software. Due to the flat hierarchy/startup atmosphere, I also gained insights in the daily business of startups and the kind of entrepreneurial concerns they face. It was particularly exciting to see how university research can be directly transformed into a product for industry.
During the course of my internship, I was involved in three different projects that contributed to Akselos software in different ways. At first, we parallelized a part of the solver workflow, that had previously been a linear procedure. This task required a mix of knowledge about algorithms, parallel computing and coding. Our end result achieved a significant reduction in computation time and is now part of the standard software.
The second task was part of a joint project with one of our engineering partners. During the course of the project, I worked with sensor measurements and investigated how we can leverage this additional data to provide even better predictions with our simulations.
The third task was about meshes and how we could best pre-process them for Akselos’ RB workflow: In order to leverage the power of the software, big models have to be split into smaller components.
In total, my internship was a great learning journey and I am grateful to everyone at Akselos who contributed to this experience.

————————————————————————————————————
Axel Séguin – Développement et implémentation du calcul de forme optimale de meule
 About : Rollomatic, Suisse
About : Rollomatic, Suisse
Description
Rollomatic is swiss company based next to Neuchatel, world leader in the field of cutting tool machines and cutting tool design softwares, which recently openened an office at the EPFL Innovation Park. The company main activity is to produce grinding machines, which are used to grind cutting tools of high precision in hard materials such as carbide (see picture).

The machine comes with a software, which objective is to transform the specification provided by the user into a set of grinding operations to actually produce the cutting tools on the machine. For each type of tool, there are several ways of giving it’s specifications and for each type of specification, there is a software functionality. My internship project consisted in devising a strategy for one of these functionalities and implementing it.
In my project, not only the trajectory but also the grinding wheel profile was unknown. Plus, the specification was not just a set of scalar parameters but also a cross cut profile (light blue curve in the below figure) defined by a continuous curve, which made the project an interesting challenge.
First, we needed to be able to simulate a grinding operation (red prints on the right) with a wheel of arbitrary profile. Then, to optimize the wheel shape, we put in place non-linear optimization strategies, in the particular case where no gradient can be computed exactly. The final algorithm were all written in C#.
From many point of view, my internship at Rollomatic was a successful and valuable experience, for which I am very thankful to the company. There always was a good balance between mathematical models and programming, which made of it a perfect CSE internship.

————————————————————————————————————
Andrea Scaglioni – Global Optimization in Simulation and Measurement of OLEDs and Solar Cells
 About, Fluxim, Suisse
About, Fluxim, Suisse
Description
My internship (six months) was carried out at Fluxim, Winterthur. Fluxim produces simulation software and measurement instruments for the semiconductors industry (e.g. photovoltaic cells and OLEDs). Between the products developed by the company there is the Setfos software, that can simulate light emission, absorption, charge transport and scattering using models that

Figure 1: Qualitative comparison of the three algorithms on the (simplifed) optimization of the layers thickness in a solar cell. Colours always refer to the objective function (in this case the photocurrent produced by the solar cell)
allow fast computations even on personal computers. The Setfos software also allows to carry out optimization tasks, for example maximizing the photocurrent produced by a solar cell or fit (in the least squares sense) measured IV curves of a device. The optimized parameters range from design parameters (e.g. thickness of the layers of a solar cell) to physical parameter (e.g. electrons mobility).
My job at Fluxim was to extend the optimization module of the software with some global optimization algorithms to reliably and eciently tackle non-convex optimization problems.
After extensive literature research and testing (in Python) three algorithms were selected: Simulated annealing, Bayesian Global Optimization and Lipschitz Optimization.
The final stage of the project consisted in coding a C++ library that grouped the three algorithm under a common interface to ease their integration in the Fluxim products.
Several other ancillary activities also had to be carried out, such as determining which features of the problems could be exploited or how to reformulate them to speed up convergence, choosing default parameters for the algorithms, choosing benchmark problems, finding effective and synthetic visualization techniques. Best practices for optimization were also documented to allow a user who is not informed about the specfic features of the algorithms to get the best
out of them.
————————————————————————————————————
Francesco Bardi – AeroSolved strategy and validation for the simulation of steady-state experiments
 About, Philp Morris, Suisse
About, Philp Morris, Suisse
Description
I conducted my internship from February 2017 to August 2018 in the Biomed-ical System Research department of Philip Morris International Research and Development based in Neuchâtel. Specically, I worked in the Computational Fluid Dynamics (CFD) team, part of the Aerosol Research and Dosimetry group.
The CFD team is at the core of the development of AeroSolved [1], a
free software (GPLv3) based on the OpenFOAM framework. AeroSolved is a CFD code to simulate the generation, transport, evolution and deposition of multispecies aerosol mixtures. The aerosol dynamics is described with an Eulerian-Eulerian approach with a possibility of characterizing the aerosolsize distribution with either a two-moment or a sectional method.
Detailed transient numerical simulations of complex ows like aerosol transport and evolution are computationally very expensive. This is due to a wide range of time scales that needs to be captured and resolved in order to achieve accurate results. On the contrary, when the experiments reach a steady state, only the nal, numerically converged solution matters. From this perspective, all of the integration time of the transient phenomena is an extra computational cost needed to obtain the nal relevant state. My role as an intern in Computational Physics was to carry out CFD simulations and to analyze and implement strategies to minimize the cost of steady-state
simulations.
I have implemented a steady steady-state solver based on the SIMPLE al-gorithm and relying on the existing libraries of AeroSolved. The new solver was validated with available experimental data from the literature [2] and tested in more complex geometries, such as the Vitrocell® 24/48 exposure system. Following the sectional method approach, the particles size distri-bution was discretized in a number of sections, and for each of which them, a transport equation was solved. In Figure 2, we show a snapshot of the vertical velocity eld component (UZ) and the ux of particles (M02) of a selected section (M02) in the Vitrocell® 24/48 well chamber. The deposition eciency (DE), dened as the ratio between the ux of particles at the tar-get surface and at the inlet, is shown in Figure 3, where the results of the steady-state solver are compared with the results from [3] obtained with a transient solver.

Figure 2: Vertical velocity eld component UZ on the symmetry plane and particle ux M02 on the deposition plate in a well chamber of the Vitrocell® 24/48.

Figure 3: Comparison of DE for two dierent simulation strategies.
————————————————————————————————————
Vincent Pollet – Speech processing models optimized for embedded platforms
About : Logitech, Suisse
Description
Logitech (Logitech International S.A.) is a Swiss company manufacturing personal computer accessories as pointer devices, keyboards, video communication, music and smart home devices. The company is consistently priced for its product designs and innovation. The CTO office team, where the internship was conducted, focuses on researching and implementing technologies that are common in the development of several products and services.
In the area of audio and speech processing, state of the art machine learning models outperforms conventional signal processing methods, however at the cost of a heavy memory footprint and high computational needs. These two drawbacks make the implementation of these models on embedded devices a real challenge, because memory and computational power has to be limited to save up battery and space. Moreover, the difference in hardware between what is available in these devices and in a computer can significantly change the models running time performances. The goal of the internship was to study different models architecture for keyword spotting and audio event detection, then to optimize and compress the selected models to be able to implement and benchmark them on a constrained platform (ARM Cortex M7 processor).
The audio is typically processed by computing features related to the magnitude spectrogram of the signal, like the Mel-scaled spectrogram or the Mel Frequency Cepstral Coefficients. The obtained “image” can then be analyzed by machine learning models designed for image recognition like convolutional neural networks or recurrent neural networks designed for time sequences analysis. The size of the audio features, the size of the models and their inference time can be optimized by techniques such as pruning and quantization, which allows to run them in real time on constrained platforms.

Audio “image” of a 1 second recording containing one word. The spectrogram of the audio signal is computed and projected to the Mel scale using 40 filters, before a logarithm transformation is applied.
————————————————————————————————————
Niccolò Discacciati – Implementation of Discontinuous Galerkin model problem for atmospheric dynamics on emerging architectures
 About : CSCS, Suisse
About : CSCS, Suisse
Description
The Swiss National Supercomputing Centre (CSCS) is the national high-performance computing centre of
Switzerland. Operated by ETH Zurich, it is located in Lugano, Canton Ticino.
My internship was built both on a theoretical (numerical) and a computational aspect. On one side, Discontinuous Galerkin (DG) methods constitute a class of solvers for partial differential equations which combine features from finite elements and finite volumes, adding a good parallelization potential. On the other hand, GridTools (GT) is an efficient C++ library developed at CSCS. In order to solve real-world problems, it triggers several architecture-based optimizations and extensive parallelism. Even though it is mainly designed for finite differences, the Galerkin4GridTools (G4GT) library provides the framework to support finite elements discretization inside GT.
The main goal of the project was the implementation and evaluation of a DG solver using G4GT, in view of possible applications in the domain of atmospheric dynamics and climate modeling. The solver is designed for advection equations and it was validated by means of different benchmark tests. Then, the support for a spatially variable discretization degree was added. Such a flexibility plays a key role both in terms of stability issues (given by the CFL condition) in case of spherical geometry and in order to save computational resources (the required time is approximately halved with respect to a constant degree). At the same time, an extensive performance analysis was carried out, using the Roofline model. For a CPU backend the results are coherent with the model, while for the GPU case the values are even above the hardware limit.
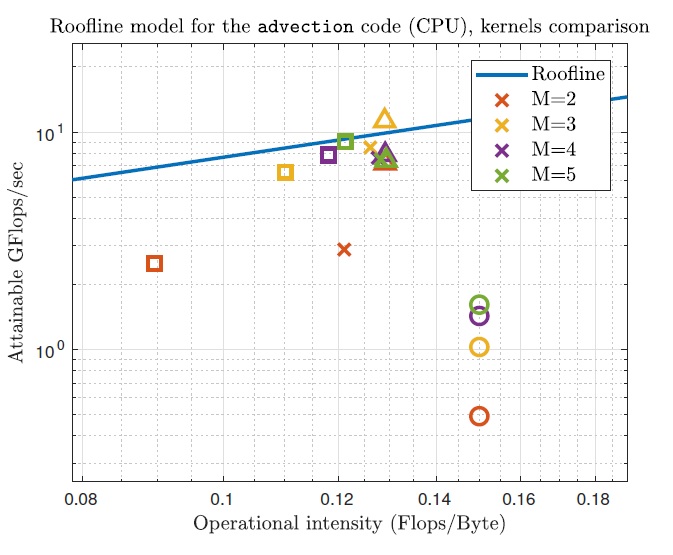
Figure 1: Performance analysis using a CPU backend, with different discretization degrees r = M − 1. The
triangles denote the dominant kernel, while the circles stand for the less-efficient one, since bad memory accesses are present. Finally, the blue line denotes the hardware limit and the crosses stand for the performances of the global program.
Guillermo Julián Moreno – Development of a mass spectrometry data analysis solution
 About : Nestlé, Lausanne
About : Nestlé, Lausanne
Description
My internship was conducted in the Nestlé Research Center (NRC) in Lausanne, more specifically in the Proteins/Peptides group in the Department of Analytical Science, from the 10th of July to the 22nd of December of 2017. Nestlé is a very well-known Swiss company and the NRC remains its flagship center for Research and Development. The project on which I worked was focused on the chemical analysis of proteins to improve milk-based products.
One of the analytical methods they use is intact protein analysis by Liquid Chromatography – High Resolution Mass Spectrometry (LC-HRMS). My role was to develop an application to analyze the data output from the machine and present the results to the user quickly and easily. The goal was to extract different information such as protein composition, protein ratios, protein modifications, protein quantification and impurities detection, among other things. This required understanding the data, modeling mathematically the problems and designing and implementing the algorithms needed.
This internship proved very enriching, as I was able to delve into a field that I did not know much of, working independently but with a valuable feedback loop on what was needed and how could we solve it, providing a solution that made easier the job of the analysts in the group, and all in a well-known and established company. All in all it was a great experience and an excellent preparation for the future.
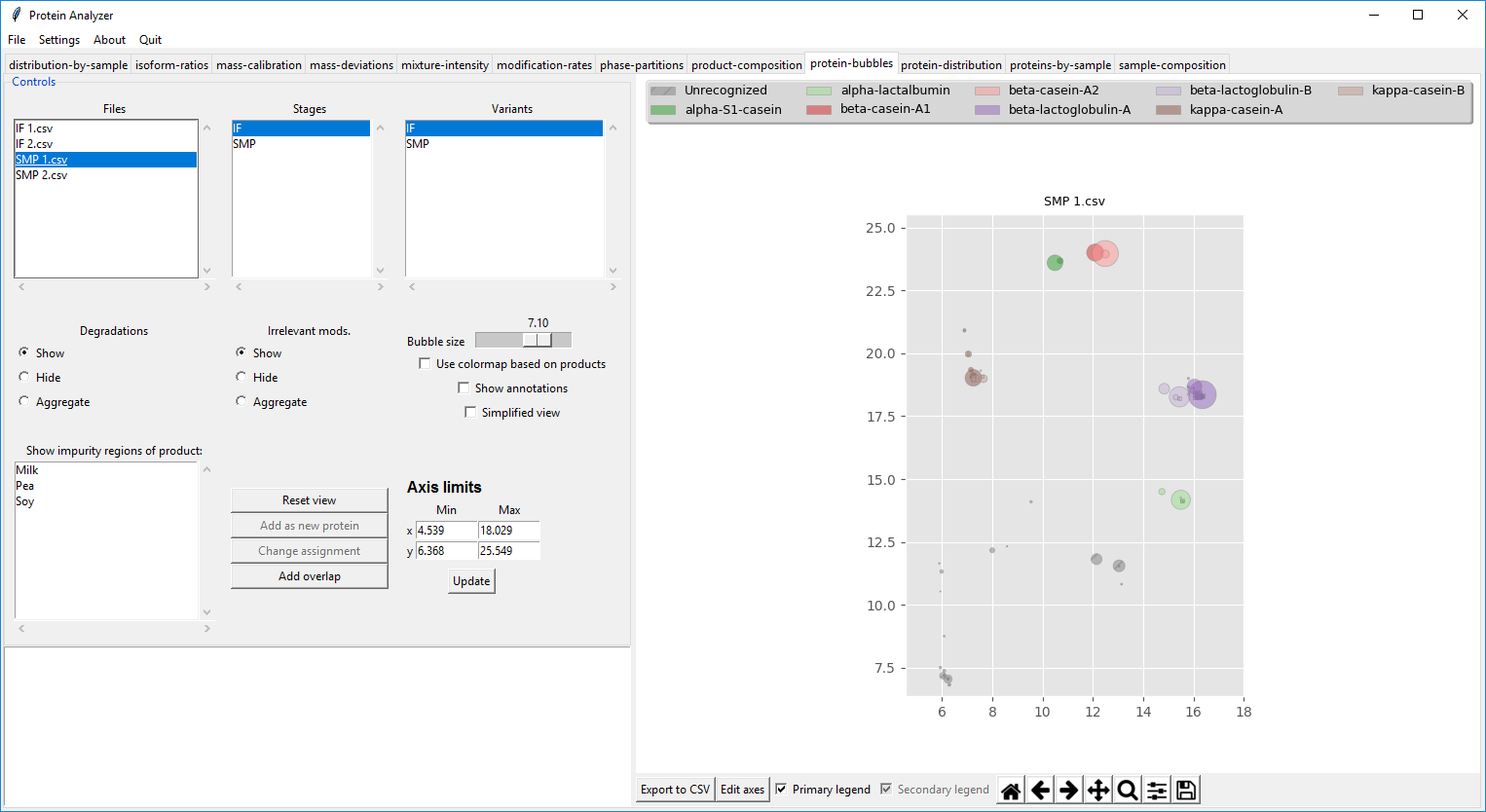
Figure 4.1: View of the detected signals in the sample and the detected proteins.
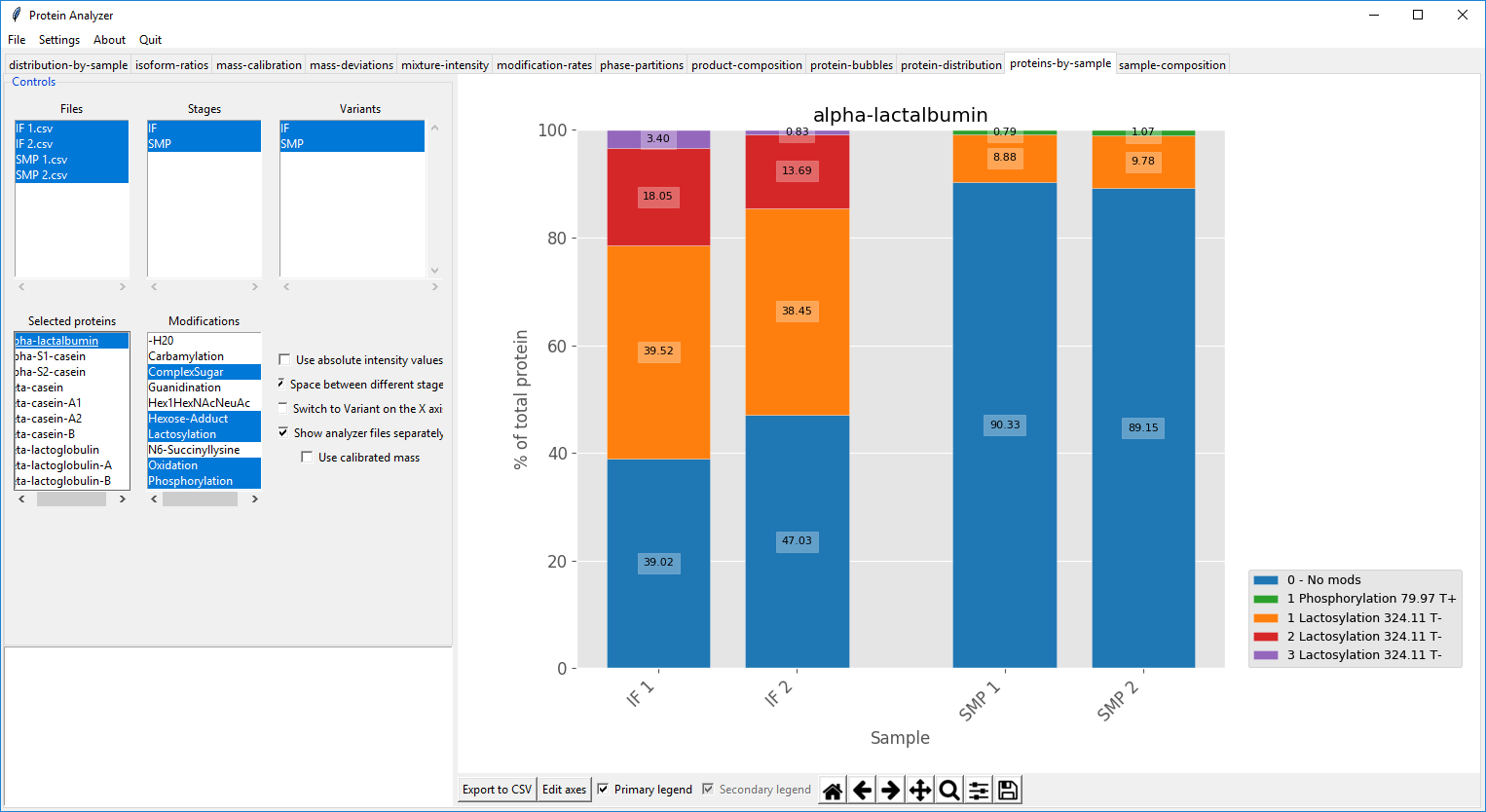
Figure 4.2: View of the modifications of a protein in different samples.
Lie He – Data Science Internship (Deep Learning/NLP)
Description
I did my internship at Deeption SA from July 1st of 2017 to December 31st of 2017. Deeption is a spin off from EPFL’s social media lab which specialize in data mining and discover insights from social media and deliver them to customer.
The first part of my internship was to develop natural language processing tools. One task is to link entities in text with pages in wikipedia. By using the internal links between anchor text and the associated wikipedia pages, one can build a labeled dataset and train machine learning model on it. Training entity embedding is a further improvement to resolve entity mention.
The second part of my internship is to improve performance of sentiment analysis task. Sentiment classification is a classical natural language processing task. The goal is to classify tweets containing cashtags into bullish/bearish ones. Several deep learning models and architectures were implemented and tuned to get good performance. After that, the tweet level sentiments are aggregated by cashtag and used to forecast stock market movement in the next day. Classical time series techniques and recurrent neural network based models are used in the forecasting part.
What I like about my internship in Deeption is that I have plenty of time to read papers and implement the methods from scratch. This internship has provided me an excellent opportunity to apply my acquired knowledge in the CSE program to a real application.
Julien Rüegg – Predictive maintenance for aeronautics
![]() About: Meggitt SA, Suisse
About: Meggitt SA, Suisse
Description
I did my internship at Meggitt SA (Fribourg) from the 1st August 2017 to the 31st January 2018. Meggitt is a world leading company in the sensing systems field, especially in the Energy and Aeronautics branches, they conceive sensors for the turbines, which are absolutely necessary for to the good functioning of power stations and aircraft engines.
My job by Meggitt was to develop an algorithm for predictive maintenance in aeronautics field. The latter should be able to predict when some specific parts of an aircraft are going to break. In this way, the airline should schedule the replacement of the piece more easily and the plane should stay grounded for less time. This research project belongs to a broader European project called AIRMES, which goal is to optimize end-to-end maintenance activities within an operator’s environment (http://www.airmes-project.eu).
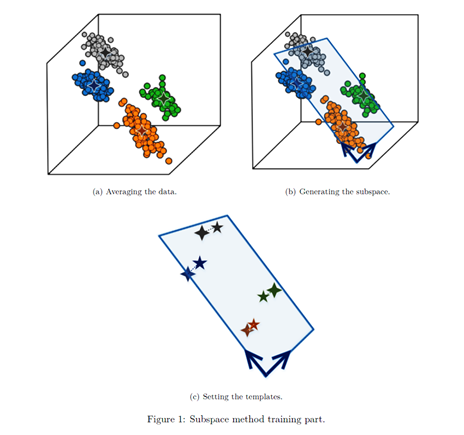
Most of the algorithms I implemented are based on pattern recognition. They belong to “subspace methods” and consist of extracting a subspace of dimension much smaller than the original space in which we start. This subspace should contain the essential information related to a part replacement and discard the useless part of the information. Once the subspace is generated, each piece replacement is represented by a template, which is a point of the subspace. This procedure can be seen in Figure 1. New data classification is performed by projecting it into the subspace and measuring the distances between this projection and the different templates.
I had a great pleasure working at Meggit. People were welcoming, my tasks were clear from the beginning and I could fully complete them using my knowledge acquired at EPFL. My supervisor totally trusted my work from the first day and was fully available and was open to discussions, which were very instructive for both of us.
Mehrdad Kiani – Performing Field Simulations for Foil-Type Medium-Frequency Transformers with COMSOL
 About : ABB, Suisse
About : ABB, Suisse
Description
I had a great opportunity to work as my internship in the research and development section of ABB from 1st of July 2017 until 31st of December in the department “Power Electronics Integration”. The goal of this internship was electromagnetic and thermal 2-d and 3-d simulation of foil windings of high-frequency transformers with COMSOL Multiphysics and validate the results based on Dowell’s equations as analytical solution. All of the simulations were done on the ABB server with accessing to 8 cores and 48 [GB] RAM. I recorded the problems and the challenges that may I got during the internship and the alternative ways which we used for solving these problems and challenges. Every a few weeks, we had a meeting to share the results to my supervisors and talk about the results and further works.
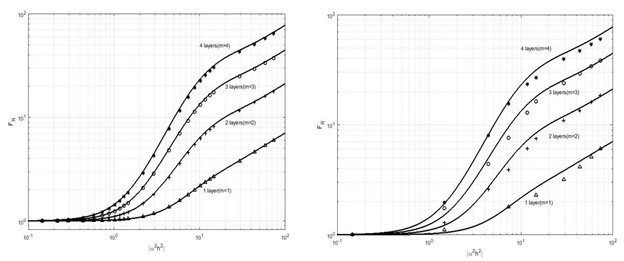
As one can see in Fig. 1, the alternating current resistance (R_w) and direct current resistance (R_w0) are calculated with the software and we had a comparison between F_R=R_w/R_w0(discrete signs) with Dowell’s equations as analytical solution (solid-lines). The left-side and right-side plots are correspond to two and three dimensional simulations, respectively which F_R parameter is versus a non-dimension number (|α^2 h^2 |). Some effects such as proximity and skin effects are more important rather than other effects in the medium and high-frequency domain in the transformers and were under consideration during the simulations. One of the biggest challenges during the simulation was about Meshing in 3-d that is described in the report in details. At the end of internship, a Python code was written in order to have an interpolation and extrapolation of data which are extracted from COMSOL in order to use in a complex code.
Figure 1: F_R as a function of |α^2 h^2 | for winding portions with integral numbers of layers according to Dowell’s equations and comparison with two (left side) and three dimensional (right side) simulations. Δ the simulation results for m=1, + the results simulation for m=2, ο the simulation results for m=3 and * the simulation results for m=4
Chiappa Alberto – Elevator context recognition
![]() About : Schindler, Suisse
About : Schindler, Suisse
Description
I was part of the New Technologies team of Schindler Aufzüge AG from July 17, 2017 to January 19, 2018. The office is located in Ebikon, in the canton of Lucerne. Schindler is one of the world leading manufacturers of escalators and elevators, founded in Lucerne in 1874.
The team’s mission is to investigate the latest technologies and to understand how they could bring benefit to Schindler’s products and services. Past projects were mainly focused on Mechanics and Electronics, but more recent ones also include an increasing presence in the data science area. I was involved in a project named “Internet of Passenger”, where the goal is to infer the operational health of the elevator from passenger mobile phones. In fact, we constantly carry in our pockets a set of sensors that includes an accelerometer, a gyroscope, a magnetometer, a light sensor and sometimes even a barometer. The project’s main task is to develop signal processing algorithms to extract certain trip characteristics of the elevator (e.g. maximum velocity, maximum acceleration).
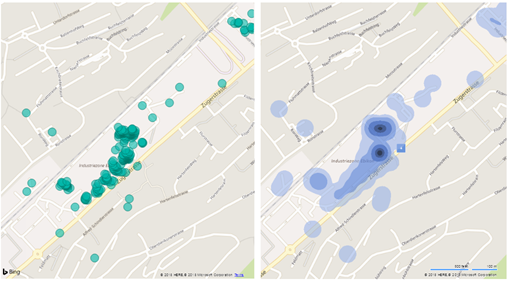
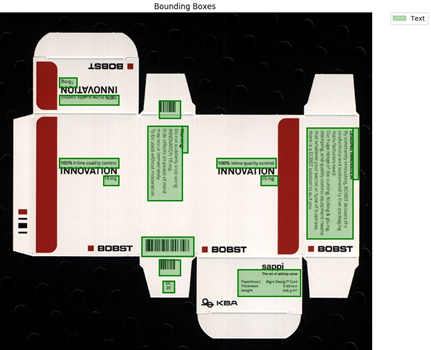
My initial duty for the project was to record the first set of real-world data and to study the feasibility of the approach against a predefined set of elevator trip characteristics to be inferred. Having collected 1025 trips from about 80 people, I proceeded to devise signal processing algorithms for two purposes: first, to segment sensor signals corresponding to an elevator trip, and second, to extract the mentioned characteristics of the trips.
The following picture shows the location of some of the recordings taken in Schindler’s campus, first as dots and then as a heatmap.
Cécile Le Sueur – How to deal with Missing Values in proteomics dataset ?
 About : EMBL, Germany
About : EMBL, Germany
Description
EMBL is an intergovernmental organisation present in 6 different countries, with more than 80 independent research groups covering the spectrum of molecular biology. I spent my 6-months internship in the Huber group, at EMBL Heidelberg (Germany).
The goal of the internship was to develop a statistical tool to study proteomics data, obtained using the tandem Mass Spectrometry technology. Using this technology, we detect the presence of proteins in tested samples and can measure their abundance using quantification methods.
We were especially interested in testing for differential expression, i.e we were searching for proteins present in different abundances between different conditions. To this aim, we estimate the \textbf{Log Fold Change}, which is the difference in abundance between the two conditions, and assess its significance. However, proteomic datasets contain numerous \textbf{Missing values}, i.e lacking observations. The goal was to handle these missing values to improve the estimation of the Log Fold Change and detect more true differentially expressed proteins.
My project was quite theoretical, but the computational aspect was important to test the developed mathematical models. I worked on Rstudio using real and simulated datasets to benchmark the performance of the models. The developed method is not finished yet and we will continue to work on the project.
I really enjoyed the research project I did, and appreciate all the people I met. My supervisors trusted me, were really supporting and gave me a lot of advices. The knowledges I acquired at EPFL were also very useful for my project. EMBL Heidelberg is a really nice place and people from the Huber group are kind, funny and stimulating. To conclude, this internship was a wonderful experience !
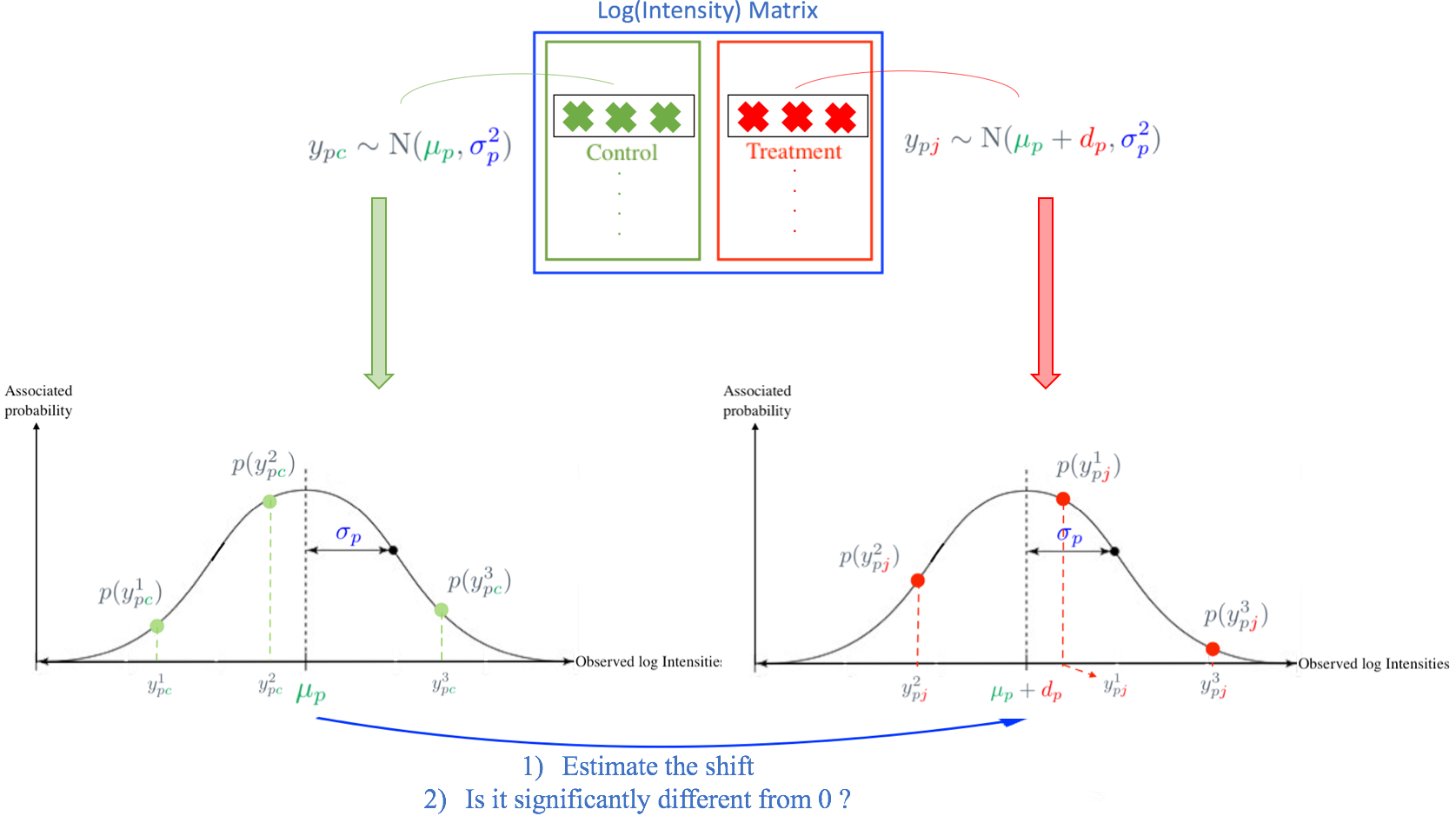
Simple model used in an hypothetical case where all data are observed. How should we model the missing observations present in real dataset ?
Peli Riccardo – Exploiting Deep Learning for Computer Vision Applications
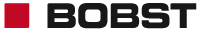 About : BOBST, Mex, Suisse
About : BOBST, Mex, Suisse
Description
I carried out my internship at BOBST SA, one of the world’s leading suppliers of machinery for packaging with folding carton, corrugated board and flexible materials. It has roughly 5000 employees worldwide and its headquarters is in Mex, close to Lausanne, where I have worked for six months. I joined the Quality Control development team in the CORES (COntrol and REgister Solutions) department. The main goal of the team is to build applications capable of detecting defects on printed boxes based on the analysis of acquired images and, thus, ensure a high quality of the final product. The whole pipeline from the image acquisition to the detection of defects is very fast, enabling a real-time quality control, without the supervision of an operator.
My role was to investigate deep learning capability in different problems that the team needs to solve. In particular, I have applied deep learning to facilitate the work of the operator who has to set the machine before the printing starts. For instance, nowadays, it is important to identify text regions, on which an expensive but very precise algorithm is run to ensure that even tiny defects are detected. Thus, I developed an algorithm for the generation of bounding boxes around small text and thin lines, as shown in the image below. This can save time and work to the operator, who can in any case modify the output to adapt it to his needs. Another algorithm was develop to find bar codes and data matrices. A deep learning network for the detection of objects in images was adapted to this task, leading to results as the one in the second image. This algorithm can be useful in the future if the reading of barcodes is needed during the printing process. I coded a third algorithm to find an alignment model for the box. An alignment model is a couple of regions which are used to estimate the shift and the rotation angle of the current box compared to a reference. The two regions should exhibit patterns with two independent directions and, in order to achieve an acceptable robustness, the patterns have to not be too subtle. A convolutional neural networks was trained to classify regions sampled from the image and the best two, in terms of contrast and distance, are kept as alignment model.

Jiaxi Gu – Algorithm design and data analysis of computational crowdsourcing urban design
 About : TalkingData, Chine
About : TalkingData, Chine
Description
I did my internship as a data scientist in the Human Data Lab (HLab) of TalkingData in Beijing, China from 1st August, 2017 to 31st January, 2018. TalkingData is China’s leading big data service platform and HLab is a business unit focused on data analytics in social science.
For the whole duration of my internship I focused on a computational crowdsourcing urban design project. The goals of the project were to i) set up a crowdsourcing urban design event at the Beijing International Design Week 2017, and ii) perform data analysis and design algorithms to decipher visitors’ designs.
For the first part, I set up a web application based on qua-kit, an urban analysis toolkit prototyped by ETH Zurich. The application allowed visitors to easily re-design the Beijing Hutong area while collecting data from each design action.
The data was used to full potential at the second part. With the help of machine learning models, visitors were clustered based on their design activities. I was able to find that for some specific social groups (i.e. local residents, people enjoying historic sites), visitors of the same social group tended to show identical design patterns, while some other social groups did not have such a feature. I also found some design patterns applicable for all visitors. For example, most visitors started their design with the buildings of large volume, regardless of their functionalities or exteriors.
Finally, I designed algorithms to calculate computational architectural metrics such as vicinity, visibility and set-back distance in visitors’ designs. Despite the fact that some visitors claimed they are simply making random movements of buildings instead of doing thoughtful design, they usually made improvements according to computational metrics.
The project is very satisfying to work on since it’s the first ever crowdsourcing urban design project powered by machine learning and computational science. The CSE study program allowed me to acquire a wide range of skills and I was really happy to apply them to full extent in this inter-disciplinary project.
Figure: The heatmap of the re-designed position of an old, large residential building
Santo Gioia – Facial Augmented Reality
![]() about : Kapanu AG, Suisse
about : Kapanu AG, Suisse
Description
I did my internship from 21.08.2017 to 20.02.2018 at Kapanu AG. Kapanu AG is a spin-off from the Institute of Visual Computing / Computer Graphics Laboratory of ETH Zurich. It is specialized in research and engineering on visual computing technologies, computer vision, computer graphics and machine learning.
During my internship, I had to study some papers about Deep Learning projects which could be useful for the company and to understand how the company could bene t from them. It was very interesting to me because I could learn many innovative Deep Learning based techniques related to computer vision tasks and have an insight on how to apply them to real life problems.
Using an open-source game engine, I also developed a test bed framework in Python which is helpful to visualise rendered scenes. I used this framework to display the facial landmarks and the head pose from an image displaying a face, derived using one of the papers I studied (see Figure 1).
I was introduced to Swift, a programming language which I had never used before. During my internship, many tasks I had to solve were related to app development, mainly UI development. Together with my colleagues, we considerably improved the UI of the iOS application the company is developing.
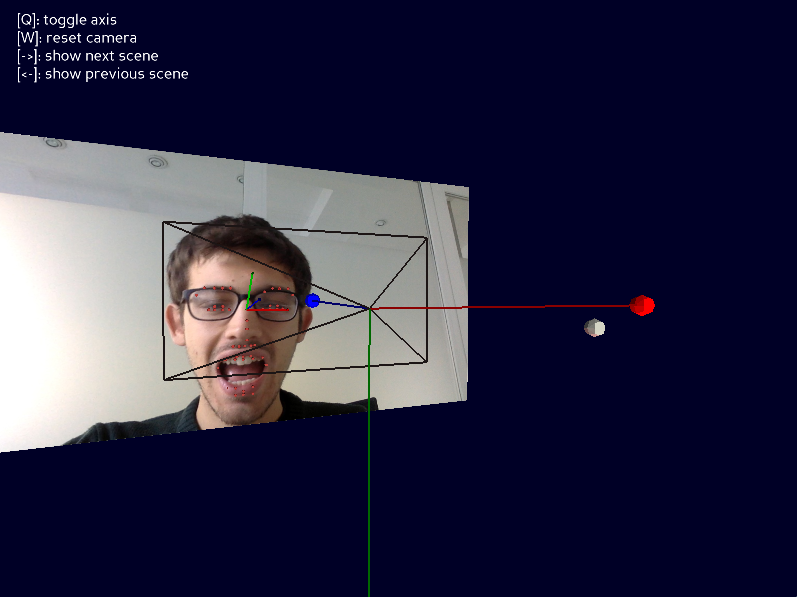
Figure 1: Scene with facial landmarks and head pose