Estimating Beauty Ratings of Videos using Supervoxels
Proceedings of the 21st ACM international conference on Multimedia
2013
21st ACM International Conference on Multimedia, Barcelona, Spain, October 21-25, 2013.p. 385-388
DOI : 10.1145/2502081.2508125
Supervoxel and Trajectories
We summarize the visual and motion features of a video with supervoxels. As different parts of a video can have different contents or viewpoints, we need to detect the individual shots that are visually consistent for proper supervoxel extraction.
 |
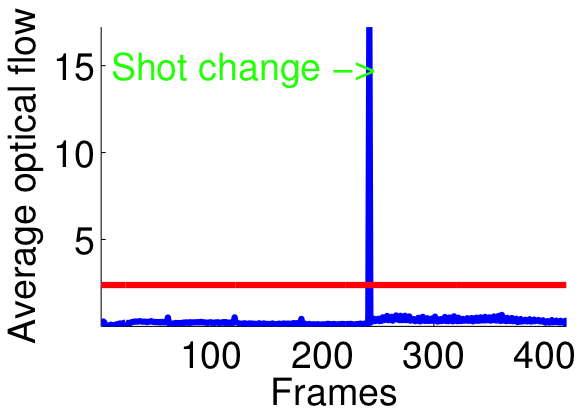 |
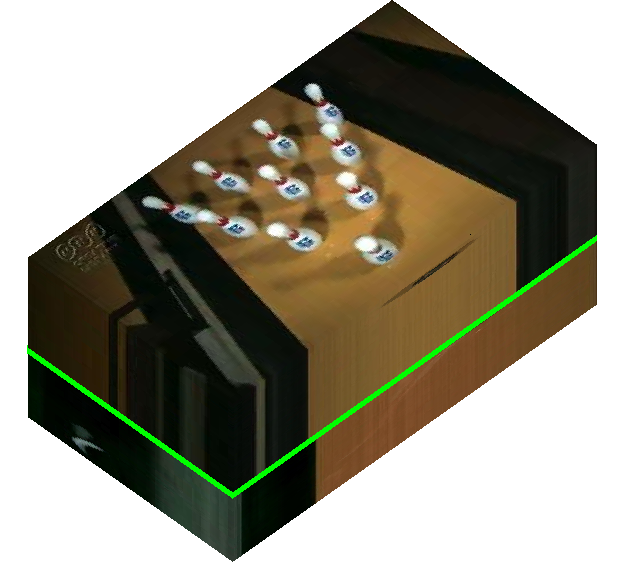
| Figure 1: Shot detection on a video with two shots. Shot change is depicted with a green line (right) | |
We use Achanta et al.’s method [1] to compute the supervoxels of every video shot. We select a spatial size for supervoxels by assuming that the minimum size for an object of interest is equal to 20 pixels. We choose the longest possible temporal size to capture the motion of an object throughout the video shot. We can see an example of supervoxel extraction in Figure 2. We represent each supervoxel with their average color (averaged in L*a*b* space) in Figure 2(b).
 |
 |
| Figure 2: Supervoxel extraction. | |
In order to learn the relationship between video features and beauty, we use the visual and motion features of the supervoxels and their trajectories. We employ visual features similar to the ones in the stateof- the-art methods that judge video beauty [3, 8, 9, 10], with one important difference: we compute them from the supervoxels.In order to express the motion inside a supervoxel, we calculate the supervoxel trajectories through a video shot by computing the center of mass of a supervoxel on each frame.
 |
 |
 |
 |
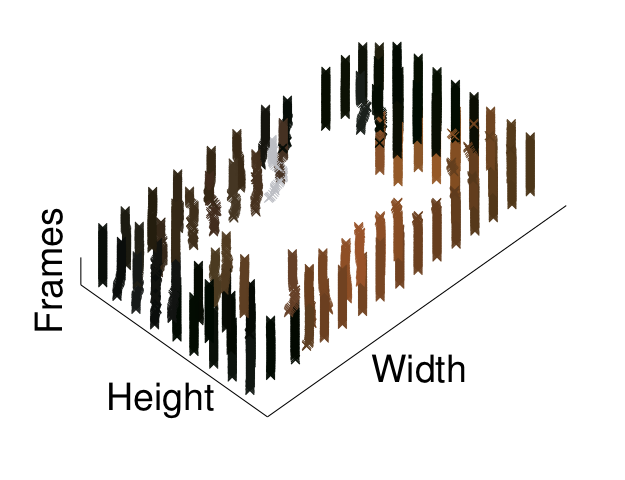
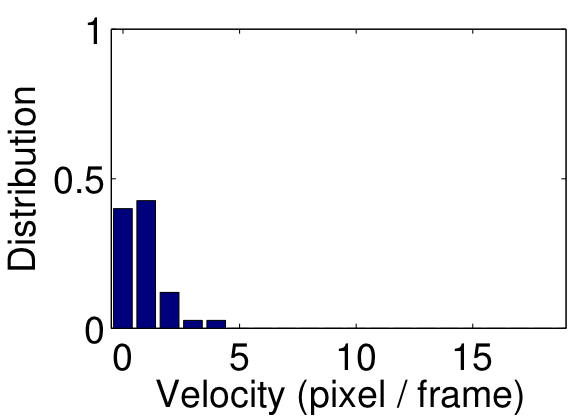
| Figure 3: Supervoxel trajectories (first row). Velocity histograms of two supervoxel trajectories in the bowling video (second row). | |
Video Ranking Results
It is possible to define heuristic rules to estimate the beauty of a video. For example, people might consider colorful videos with high contrast and smooth movements as beautiful. However, we choose to discover those rules, if they exist, by regressing our features over video ratings. We select 60 videos from the NHK dataset, half of which can be considered as collectively “beautiful” (with rating = 1) and the rest as “not beautiful” (with rating = 0). Instead of having a continuous rating, we create a binary ground truth to properly learn the separation between good and bad videos. We then train a neural network-based regressor (with one hidden layer of 10 neurons) for rating estimation. As video beauty is a subjective concept, parametrizing the joint distribution of the input features and the beauty is prone to errors. Thus, we choose a discriminative regression model instead of a generative model. The input of the network is the supervoxel feature vector of all supervoxels in all of the training videos and the ground truth is the binary beauty ratings. In order to estimate the rating of a video, we extract its supervoxel features and pass them through the neural network. The rating of a video is calculated by averaging the ratings of its supervoxels.
We rank the videos in the NHK dataset with respect to their estimated final ratings. The correlation coefficients of our ranking and the user study-based ranking obtained by the NHK challenge is given in Table 2.
| Feature Type | Spearman’s Correlation |
| Motion Only | 0.052 |
| Visual Only | 0.387 |
| Both | 0.424 |
References
[1] R. Achanta, A. Shaji, K. Smith, A. Lucchi, P. Fua, and S. Süsstrunk. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Transactions on PAMI, 34(11):2274–2282, 2012.
[3] S. Bhattacharya, R. Sukthankar, and M. Shah. A framework for photo-quality assessment and enhancement based on visual aesthetics. In Proc. of the International Conference on Multimedia, pages 271–280, 2010.
[8] Y. Luo and X. Tang. Photo and video quality evaluation: Focusing on the subject. In Proc. of ECCV, volume 3, pages 386–399, 2008.
[9] A. Moorthy, P. Obrador, and N. Oliver. Towards computational models of the visual aesthetic appeal of consumer videos. In Proc. of ECCV, volume 6315, pages 1–14, 2010.
[10] Y. Niu and F. Liu. What makes a professional video? a computational aesthetics approach. IEEE Transactions on Circuits and Systems for Video Technology, 22(7):1037–1049, 2012.