Text Recognition in Natural Images Using Multiclass Hough Forests
Proceedings of the 8th International Conference on Computer Vision Theory and Applications
2013
8th International Conference on Computer Vision Theory and Applications (VISAPP), Barcelona, Spain, February 21-24, 2013.p. 737-741
Hough Forests
Generalized Hough transform is a technique for finding the position and parameters of arbitrary shaped objects using local information in a voting scheme. In this paper, we use multiclass Hough forests (Gall et al., 2011), which is an efficient method to compute the generalized Hough transform for multiple types of objects by adopting random forests.
Figure 1: Generalized Hough transform of character small “a” by using Hough forests (image is taken from ICDAR 2003 dataset)
Cross-Scale Binary Features
In our work, we modify the binary features in (Gall et al., 2011) by allowing the comparison between two scales. Every feature effectively compares the mean values of two randomly positioned rectangles with random dimensions.
Word Formation
Letters can resemble each other either locally or globally. For example, the upper part of the letter “P” could be detected as a letter “D” within a smaller scale. Depending on the font style, the letter “W” can be confused with two successive “V”s or “U”s and vice versa. Therefore, instead of recognizing characters individually, we use a pictorial structure model and produce lexicon priors with the help of an English word list.

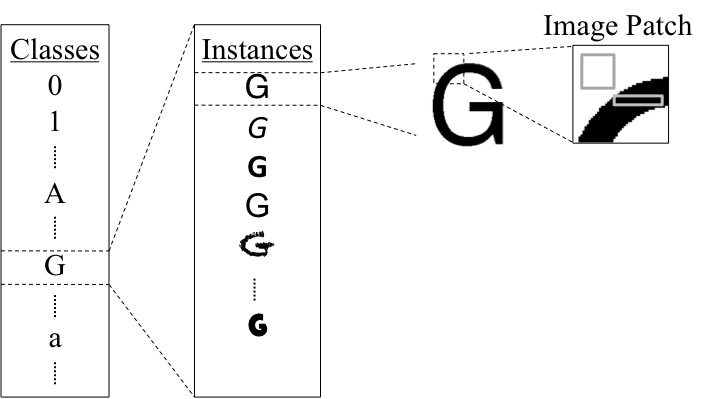
Training Dataset
We create a dataset by using a subset of 200 computer fonts under random affine transformations. In addition, we put other characters around the main character using the probabilities of occurrence in an English word. Finally, we blend these images with random non-text background to simulate a character in a natural scene. The MATLAB code and other necessary files to generate a dataset can be downloaded here.

Results
We also test our algorithm on cropped words in the ICDAR 2003 database. As in (Wang et al., 2011) and (Mishra et al., 2012), we ignore words with nonalphanumeric characters and words that are shorter than three letters, giving us a total of 827 words. Note that the proper nouns and brand names that appear in the dataset are also in our search space.
| Method | ICDAR2003 | Time |
| Hough Forest | 85.7 | 3 minutes |
| Mishra et al. | 81.78 | – |
| Wang et al. | 76 | 15 seconds |
Table 1: Cropped word recognition results (in %) from the ICDAR 2003 database.








References
Gall, J., Yao, A., Razavi, N., Gool, L. V., and Lempitsky, V. (2011). Hough forests for object detection, tracking, and action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(11):2188–2202.
Mishra, A., Alahari, K., and Jawahar, C. V. (2012). Top-down and bottom-up cues for scene text recognition. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2687–2694.
Wang, K., Babenko, B., and Belongie, S. (2011). End-to-end scene text recognition. In Proc. of the International Conference on Computer Vision, pages 1457–1464.