Semester projects are open to EPFL students.
 Comics Projects
Comics Projects
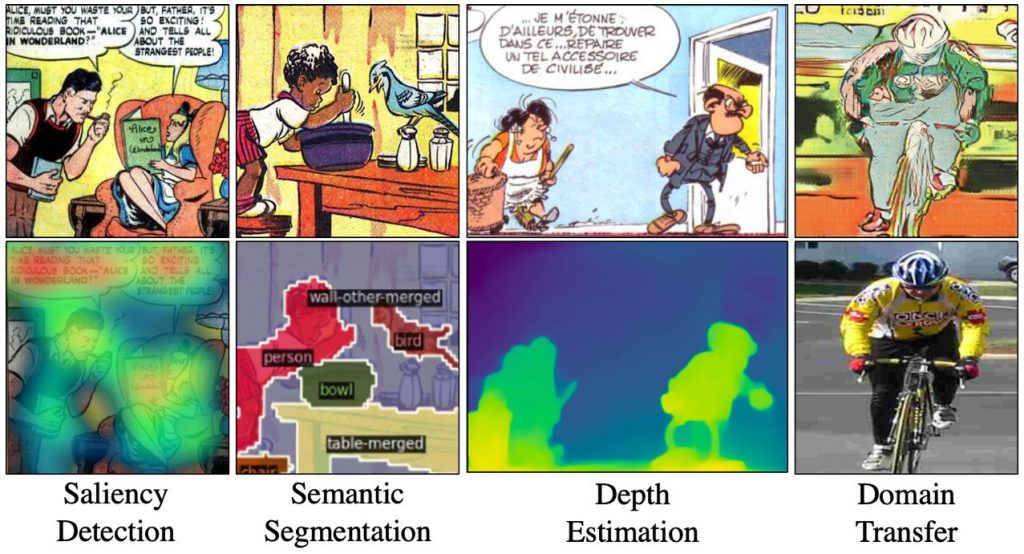
Visual computing on comics is a very exciting yet very challenging problem because of the lack of annotated data, domain shifts, and intra-domain variability. To tackle this problem, we aim to use segmentation, saliency detection, depth estimation along with style transfer. In the projects that follow you will broaden your skills by understanding how to use state-of-the-art computer vision algorithms on a customized comics dataset. We aim to publish the results in the upcoming venues.
Lack of annotated data
The lack of annotated data in the comics domain makes it difficult to train machine learning models for vision tasks such as image classification, segmentation, depth prediction, and saliency prediction. Without annotated data, it is challenging for the model to learn the essential features and patterns to perform the task accurately.
Domain gap
The comics domain has unique properties that are not present in the training data (natural images), resulting in a domain gap between the training data and the comics data. This leads to poor performance and difficulty to generalize when the model is applied to comics data.
Variability within the domain
Different artists and publishers often use unique visual styles and techniques while producing comics. For instance, one artist may represent a chair substantially differently than another, resulting in a variance in the object’s appearance. This type of discrepancy is uncommon in images of nature. Therefore, it is challenging for a model to accurately perform tasks such as image classification or segmentation by grouping objects that seem to belong to distinct categories.
It is well known that deep learning models need to be trained with a huge amount of data. To circumvent this limitation if only a small dataset is available, models are pre-trained on large datasets and then fine-tuned on the few available labels from the target domain. The models are usually trained on ImageNet or even larger datasets with labeled or in a self-supervised manner. Although those models provide strong baselines, the performance of different training schemas varies in different scenarios and there is no guideline for choosing the model to use.
In our project, we will investigate this problem with a novel comic dataset. We explore a large array of differently pre-trained models with different datasets, such as supervised and diverse self-supervised models, to then fine-tune them with our own labeled comic data. Through thorough analysis of the results, we will provide insights into finding the best model for transfer learning. At the end of the semester, you should therefore be able to give an overview of the existing transfer-learning methods, how these work applied on our comic dataset, and theorize on their applicability beyond a single domain
Task:
– Evaluate differently pre-trained models on comic data.
– Pre-train the model in a self-supervised learning manner on comic data directly.
– Establish the possibilities and limitations of transfer learning on comic data and other domains.
Prerequisites:
Having knowledge on python, deep learning framework (tensorflow or pytorch), and linear algebra is required.
Level:
MS project
Type of work:
20% literature review, 40% research, 40% development and test.
References:
[1] Rankme: Assessing the downstream performance of pretrained self-supervised representations by their trank , Quentin Garrido, Randall Balestriero, Laurent Najman, Yann LeCun
[2]. Dive into Self-Supervised Learning for Medical Image Analysis: Data, Models and Tasks , Chuyan Zhanga, Yun Gua
[3]. Rethinking ImageNet Pre-training, Kaiming He, Ross Girshick, Piotr Dollár
[4]. Masked Autoencoders are Scalable Vision Learner, Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick
Supervisors: Peter Grönquist ([email protected]) , Tong Zhang([email protected])
Description:
Salient regions are the areas that stand out compared to their surroundings. Saliency prediction aims to predict which areas attract the most attention. However, unlike image classification, the saliency prediction task lacks large-scale annotated datasets. Current approaches for saliency estimation use eye tracking data on natural images for constructing ground truth. However, in our project we will perform saliency detection on comics pages instead of natural images.
In this project, you will explore the existing saliency prediction methods on comics stimuli. You will test and improve a method proposed for saliency prediction using inter-object relationships. Then, you will evaluate your model by comparing to the state-of-the-art saliency detection models.
Tasks:
– Understand the literature and state-of-art
– Test existing methods for saliency prediction on comics
– Improve a saliency prediction method proposed by using object-character interactions
– Evaluate state-of-the-art saliency detection models on comics data
Prerequisites:
Experience in machine learning and computer vision, experience in Python, experience in deep learning frameworks
Deliverables:
Reproducible code and a written report
Level:
MS semester or thesis project
Type of work:
60% research, 40% development and testing
References:
“DeepComics: Saliency estimation for comics”, Kevin Bannier, Eakta Jain, Olivier Le Meur
Khetarpal and E. Jain, “A preliminary benchmark of four saliency algorithms on comic art,” 2016 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Seattle, WA.
Daniel V. Ruiz and Bruno A. Krinski and Eduardo Todt, IDA: Improved Data Augmentation Applied to Salient Object Detection, 2020 SIBGRAPI
Supervisor:
Bahar Aydemir ([email protected])
Description:
Dense semantic correspondence relates pixels belonging to similar objects in two different images to each other. Unlike segmentation task, semantic correspondence requires fine grained recognition of the object parts. However, most datasets include only the segmentation masks instead of pixel-wise correspondence labels. Our aim is to improve semantic correspondence task without the ground truth correspondence labels. You will be learning core concepts from self- and weakly-supervised learning and have a complete understanding about the features extracted by deep learning models.
References:
[1] Wang, Xinlong, et al. “Dense contrastive learning for self-supervised visual pre-training.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
[2] B. Zhou, A. Khosla, L. A., A. Oliva, and A. Torralba, “Learning Deep Features for Discriminative Localization.” CVPR, 2016.
[3] Liu, Yanbin, et al. “Semantic correspondence as an optimal transport problem.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
Deliverables: Report and reproducable implementations
Prerequisites: Experience with deep learning, Pytorch, computer vision, probability and statistics
Level: MS semester project
Type of work: 60% research, 40% implementation
Supervisors: Baran Ozaydin ([email protected])
Description:
Visual saliency refers to a part in a scene that captures our attention. Current approaches for saliency estimation use eye tracking data on natural images for constructing ground truth. However, in our project we will perform eye tracking on comics pages instead of natural images. Later, we will use the collected data to estimate saliency in comics domain. In this project, you will work on an eye tracking experiment with mobile eye tracking glasses.
Tasks:
– Understand the key points of an eye tracking experiment and our setup.
– Conduct an eye tracking experiment according to given instructions.
Deliverables: At the end of the semester, the student should provide the collected data and a report of the work.
Type of work: 20% research, 80% development and testing
References:
[1] A. Borji and L. Itti, “Cat2000: A large scale fixation dataset for boosting saliency research,” CVPR 2015 workshop on ”Future of Datasets”, 2015.
[2] Kai Kunze , Yuzuko Utsumi , Yuki Shiga , Koichi Kise , Andreas Bulling, I know what you are reading: recognition of document types using mobile eye tracking, Proceedings of the 2013 International Symposium on Wearable Computers, September 08-12, 2013, Zurich, Switzerland.
[3] K. Khetarpal and E. Jain, “A preliminary benchmark of four saliency algorithms on comic art,” 2016 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Seattle, WA.
Level: BS semester project
Supervisor: Bahar Aydemir ([email protected])
Description (Master Semester Project open to EPFL students)
In this project, you will do a comparative analysis on the existing literature for monocular depth estimation while applying them on comics images. The state-of-the-art monocular depth estimation methods [1] [2] [3] are applied to natural photographs but when they are applied to comics images they severely underperform. In this project you would a] apply all the existing depth methods directly on the comics images and b] use an existing translation method to translate the comics images to real ones, and then apply all the existing depth baselines [4]. Following this, you will analyse the results qualitatively and quantitatively.
You may contact the supervisor at any time should you want to discuss the idea further.
References
[1] Monocular Depth Estimation: A Survey https://arxiv.org/abs/1901.09402
[2] Monocular Depth Estimation Based On Deep Learning: An Overview https://arxiv.org/abs/2003.06620
[3] Monocular Depth Estimation Using Deep Learning: A Review https://www.mdpi.com/1424-8220/22/14/5353/pdf
[3] Estimating Image Depth in the Comics Domain https://arxiv.org/abs/2110.03575
Type of Work (e.g., theory, programming)
30% research, 70% implementation and testing
Prerequisites
Good experience in deep learning, experience in Python, Pytorch. Experience in statistical analysis (finding absolute errors or RMSE between the prediction and the ground-truth) to report the performance evaluations of the models.
Models will run on RunAI. (We will guide you how to use RunAI- no prior knowledge required).
Supervisor
Deblina BHATTACHARJEE ([email protected])
Description (Master Semester Project or Master Thesis Project open to EPFL students)
In this project, you will research the existing literature on multi-task learning and self-supervised approaches [refer to 1]. Further you will read literature about how to use these two in conjunction, and then implement the method [refer to 2]. You will have to think of a novel idea to improve on this method for which you will receive guidance from your supervisor. Thereafter you will evaluate your method against the existing baselines. In doing so, you will learn about the various approaches to improve joint-training on dense vision tasks.
Bonus (applicable to Master thesis students only): We will work with transformer frameworks and working on the explainability/ interpretability of transformers will fetch you extra points.
You may contact the supervisor at any time should you want to discuss the idea further.
Reference
[1] Multi-Task Learning for Dense Prediction Tasks: A Survey, Simon Vandenhende et.al.
[2] Multi-task Self-Supervised Visual Learning, Doersch and Zisserman.
Type of Work (e.g., theory, programming)
50% research, 50% development and testing
Prerequisites
Experience in deep learning, experience in Python, Pytorch. Experience in statistical analysis to report the performance evaluations of the models.
Models will run on RunAI. (We will guide you how to use RunAI- no prior knowledge required).
Supervisor(s)
Deblina BHATTACHARJEE ([email protected])
Available Projects – Spring 2023
Description:
Startup company Innoview Sàrl has developed software to recover by smartphone a watermark hidden into a grayscale image that uses halftones to display simple graphical elements such as a logo. The watermark hiding algorithm can be tuned according to a variety of parameters. Explore the variations of the parameters and derive hiding and recognition metrics.
Deliverables: Report and running prototype (Matlab and/or Android).
Prerequisites:
– knowledge of image processing / computer vision
– basic coding skills in Matlab and Java Android
Level: BS or MS semester project
Supervisors:
Dr Romain Rossier, Innoview Sàrl, [email protected], , tel 078 664 36 44
Prof. Roger D. Hersch, INM034, [email protected], cell: 077 406 27 09
Description:
Maybe you’ve seen the images generated by latest Deep Learning Models (Stability AI or Novel AI), which has amazed the public considering its realism, diversity, and even aesthetics. This is definitely one giant step towards applying AI in the real world. The technology behind these images is called Diffusion Models (DMs).
DMs follow a surprisingly simple idea of sequentially denoisering the image from random noise. On the contrast to Generative Adversarial Nets (GANs), DMs does not need an adversarial training process, which is notoriously unstable. Combining DMs with visual-text model, e.g., CLIP, we have image generator conditioned on text caption.
Considering DM is relatively new topic, in this project, you will explore some critical aspects of DMs, e.g., efficiency, controlability, and coherence. To give you an example, DMs generate images by reversing the noisy process (denoising) that have many steps (e.g., 20), speeding up one step or reducing number of denoising step requires would be desirable. As for controlability, current text-conditioned DMs builds on CLIP, which uses a Transformer to create sentence embedding. It would be helpful to consider more sophistic language model to understand text condition better.
As we expect to hire ~two students for this project, and you would mainly focus on one aspect.
Level
MS Level: semester project / master project
Prerequisite:
Knowledge in deep learning frameworks (e.g., PyTorch), image processing, and Computer Vision.
Supervisors:
- Yufan Ren: [email protected]
Type of work:
- 60% research, 40% development
References:
- High-Resolution Image Synthesis with Latent Diffusion Models
- DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
- https://github.com/heejkoo/Awesome-Diffusion-Models
Startup company Innoview Sàrl has developed software to recover by smartphone a watermark hidden into a grayscale image. In order to prevent counterfeiting, this watermark should be better hidden. Contribute to the development of a new method providing additional hiding capabilites.
Deliverables: Report and running prototype (Matlab).
Prerequisites:
– knowledge of image processing / computer vision
– basic coding skills in Matlab
Level: BS or MS semester project
Supervisors:
Dr Romain Rossier, Innoview Sàrl, [email protected], , tel 078 664 36 44
Prof. Roger D. Hersch, BC110, [email protected], cell: 077 406 27 09
Description:
1D moirés enable creating interesting dynamically moving shapes and symbols. The project aims at creating such moirés as 3D graphical objects defined by meshes. The resulting moirés are to be simulated by Blender. They can be fabricated with a 3D printer.
Deliverables: Report and running prototype (Matlab).
Prerequisites:
– knowledge of image processing / computer vision
– basic coding skills in Matlab
Level: BS or MS semester project
Supervisor:
Prof. Roger D. Hersch, BC110, [email protected], cell: 077 406 27 09
Reference
R.D. Hersch, S. Chosson, Band Moiré Images,
Proc. SIGGRAPH 2004, ACM Trans. on Graphics, Vol. 23, No.3, 239-248
https://infoscience.epfl.ch/record/99904
Introduction:
Recent work on text to 2D models such as Stable Diffusion trained on billions of text-image pairs have achieved stunning image synthesis quality. However, the model requires large scale datasets and industrial sized training models, a process that can be hard to be taken to 3D scenes generation.
To deal with this problem DreamFusion as the first work taking Diffusion models to 3D generation with facilitation of NeRF is able to accelerate this process and create view-consistent scene objects with mesh models for generalised forward rendering pipeline. See https://dreamfusion3d.github.io/ for a collection of generated results.
This project will focus on text-driven 3D content generation, looking at possibilities of exploiting pretrained 2D diffusion models or other similar architecture with 3D vision as priors to accomplish the following tasks 1. Create larger scaled scenes with realistic environment surroundings; 2. Generate specific materials with particular viewing effects that require 3D understanding of scene intrinsics such as transparent objects; 3. Editable texture / stylization for scene meshes controlled via text-input . We will be looking at CLIP and diffusion based models. A work close to this project can be found in Text2Mesh in the reference section.
Type of Work:
- MS Level: semester project / master project
- 60% research, 40% development
- We encourage collaboration / teamwork so this project can take 2 students working on different aspects of the research problem.
Supervisor:
- Dongqing Wang, [email protected]
- Yufan Ren, [email protected]
Prerequisite:
- Have taken a Machine Learning course and a Computer Vision course.
- Have sufficient Pytorch knowledge.
- Students will be working extensively with 3D scene generation and possibly editing, therefore prior experience with 3D vision and / or computer graphics knowledge will be a plus.
- Experience with diffusion models and / or CLIP will be a plus.
Reference Literature:
- Poole, Ben, et al. “Dreamfusion: Text-to-3d using 2d diffusion.” arXiv preprint arXiv:2209.14988 (2022).
- Chen, Yongwei, et al. “TANGO: Text-driven Photorealistic and Robust 3D Stylization via Lighting Decomposition.” arXiv preprint arXiv:2210.11277 (2022).
- Rombach, Robin, et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
- Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International Conference on Machine Learning. PMLR, 2021.
- Michel, Oscar, et al. “Text2mesh: Text-driven neural stylization for meshes.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
- https://github.com/ashawkey/stable-dreamfusion
- https://github.com/CompVis/stable-diffusion
Description:
A typeface for alphabet-based script system, such as English and French, contains type face for each character in the alphabet (~50) with cap and punctuations. On the contrary, Asian characters, including Chinese charaters Hanzi and Japanses Kanji contains more than 3000 characters. Consequently, designing typeface for asian characters is much more time, effort, and budget demanding.
Can we automate this process with Deep Learning? Typeface design could be viewed as a style transfer problem, where the content (meaning) remains the same while style changes. Previous works have shown promising result using conditional GANs on Pixels and Transformers on Scalable Vector Graphics. Scalable Vector Graphics has smaller storage and more compatible with daily use where font sizes changes. On the other hand, pixels could be readily processed by the well-researched image processing models. However, only a few works attempt to combine these two modality and combine the strength of both.
In this project, you will explore combining these two modalities and train a model. The ideal use case is that we could generate a type set with only few samples as reference.
Level
MS Level: semester project / master project
Prerequisite:
Knowledge in deep learning frameworks (e.g., PyTorch), image processing, and Computer Vision.
Supervisors:
Type of work:
60% research, 40% development
References:
[1] DeepSVG: A Hierarchical Generative Network for Vector Graphics Animation
[2] SVG Vector Font Generation for Chinese Characters with Transformer
[3] Deepvecfont: Synthesizing high-quality vector fonts via dual-modality learning
Description :
Neural Rendering is a branch of rendering technique that replaces one or more parts of the rendering pipeline with neural networks. The inductive bias of neural networks has been proven helpful in many Neural Rendering tasks, such as novel view synthesis (NeRF), surface reconstruction (volSDF), and material acquisition (NeRD).
In this project, we are interested in the generalization ability of Neural Rendering, e.g., given a set of images, infer novel views directly. There are several benefits of using generalizable features. Firstly, we skip the long training procedure with a fast-forward inference. Secondly, learnable features are beneficial in sparse input cases. Thirdly, the framework enables further optimization to improve quality.
Level
MS Level: semester project / master project
Prerequisite:
Knowledge in deep learning frameworks (e.g., PyTorch), image processing, and Computer Vision.
Supervisors:
Type of work:
40% research, 60% development
References:
[1] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Introduction:
Having established research paperwork at hand, how far are we from taking it to real life? Models presented on top conferences such as CVPR or SIGGRAPH have fancy teasy images as well as appealing performance. However such experiments are performed within a restricted lab setting with higher amount of computational power and sanitised data collection. To realise a research idea such that it can be of use for people in real life on mobile devices, certain adaptations have to be made for research models, such as making it lighter-weighted, loosen camera setting for data capture, perform better interpretation on user input, etc.
Such levels of adaptations are often ignored in research settings, although they can be relatively important in the evolution of technology, and they have potential to be published as research work as well. Some examples can be found in the reference section in which neural rendering techniques can be adapted into a lighter setup for users.
In this project, we are looking to adapt a research oriented sketch to a 3D model in which we interpret hand-drawn sketches as 3D models with generated authentic RGB values. Such a model can facilitate the design pipeline in which designers provide coarse 2D pencil sketches in hope of inspiration on the real 3D model. Currently the model pipeline consists of training several different modules, and inference can be too heavy a computation to perform on mobile devices. We are also looking for faster data acquisition methods. The end goal for this project would be an mobile-based application on with client-server communication protocols.
Type of Work:
- BS/MS Level: semester project / master project
- 20% research, 80% development
Supervisor:
- Dongqing Wang, dongqing.[email protected]
- Yufan Ren, yufan.[email protected]
Prerequisite:
- Have sufficient Andriod/IOS development experience.
- Rapid prototyping: can running research code and understand ideas quickly
- Industrial experience on adapting research papers to light-weight models on mobile devices is a plus.
Reference Literature:
Boss, Mark, et al. “SAMURAI: Shape And Material from Unconstrained Real-world Arbitrary Image collections.” arXiv preprint arXiv:2205.15768 (2022)
Chen, Zhiqin, et al. “Mobilenerf: Exploiting the polygon rasterization pipeline for efficient neural field rendering on mobile architectures.” arXiv preprint arXiv:2208.00277 (2022).
Level
M.S Semester Project
Description
Vision Transformers have been shown effective on many tasks. Recently, it has been shown that global appearance of a scene can be encoded in the classification token whereas content is mainly represented by the quadratic self-attention matrix in self-supervised vision transformers. Our aim is the exploit these representations to edit images and extract semantic information. Specifically, we will keep the content/semantics unchanged while editing the style/appearance. Our models will be evaluated with segmentation and image quality metrics.Deliverables
Code, acquired dataset and written report
Type of Work (e.g., theory, programming)
%30 research, %70 implementation.
Prerequisites
Knowledge in Python and PyTorch, experience in image processing and computer vision. Experience with Transformers is a preference.
Supervisors
Baran Ozaydin ([email protected])
Tasks:
– Understand the literature and state-of-art
– Test existing image classification data augmentation methods for saliency prediction
– Test and improve a data augmentation method proposed for saliency prediction
– Evaluate state-of-the-art saliency detection models on new data
Prerequisites:
Experience in machine learning and computer vision, experience in Python, experience in deep learning frameworks
Deliverables:
Reproducible code and a written report
Level:
MS semester or thesis project
Type of work:
60% research, 40% development and testing
References:
Supervisor:
Bahar Aydemir ([email protected])
Image-based rendering can date back to the 1990s. Unlike traditional Computer Graphics rendering, which requires explicit scene geometry and scene texture, image-based rendering renders a scene based on observations of the scene, i.e., photographs taken in the real/synthesised scene.
Given an image collection of a scene under different viewing directions, the method of NeRF can faithfully synthesise novel views that are 3D-consistent. However, it is still an open question of how to render the scene under a novel lighting condition.
There are a few works about relighting a NeRF-like implicit scene representation. There are two steps for this process: scene decomposition and 3D scene extraction from the decomposition. Afterwards, we can relight the 3D representation easily.
In this project, we explore various 3D scene representations, either implicit or explicit, and develop corresponding scene decomposition strategies which would then enable scene novel view inquires and relighting.
Type of work
- MS Level: semester project / master project
- 60% research, 40% development
Prerequisite:
- Knowledge in deep learning frameworks (e.g., PyTorch or Tensorflow), image processing and Computer Vision.
- Experience with 3D vision is required.
Supervisor:
- Dongqing Wang, [email protected]
Reference Literature:
- NeRF: Neural Radiance Field https://www.matthewtancik.com/nerf
- NeRV: Neural Reflectance and Visibility Fields for Relighting and View Synthesis https://pratulsrinivasan.github.io/nerv/
- Neural Radiance Fields for Outdoor Scene Relighting https://4dqv.mpi-inf.mpg.de/NeRF-OSR/
- NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination https://arxiv.org/abs/2106.01970
Description
Alan Turing introduced his famous Turing patterns back in 1952 suggesting how reaction-diffusion systems can be a valid model for generating the resulting morphogenesis patterns. A particularly inspiring reaction-diffusion model that stood the test of time is the Gray-Scott model, which shows an extreme variety of behaviors controlled by just a few variables.
On the other hand, Ever since von Neumann introduced Cellular Automata (CA) as models for self-replication, they have captivated researchers’ minds, who observed extremely complex behaviors emerging from very simple rules, such as Conway’s Game of Life.
In this project, we will use Neural Cellular Automata (NCA), a differentiable extension of the original CA, to generate images and patterns. We will guide and supervise the NCA using various pretrained models such as OpenAI CLIP, VGG19, and Optical Flow Prediction networks.
Deliverables
-
Code, well cleaned up and easily reproducible.
-
Written Report, explaining the literature and steps taken for the project.
Prerequisites
-
Python and PyTorch.
-
Experience with Deep Learning methods and Convolutional Networks
Level: Master Student
Type of work
50% research, 50% implementation.
References
Reaction-Diffusion models: https://www.karlsims.com/rd.html
|
Illustrated tutorial of the Gray-Scott Reaction-Diffusion model.
|
Self-Organizing Textures: https://distill.pub/selforg/2021/textures/
 |
distill.pub
Neural Cellular Automata learn to generate textures, exhibiting surprising properties.
|
|
Growing Neural Cellular Automata: https://distill.pub/2020/growing-ca/
 |
distill.pub
Training an end-to-end differentiable, self-organising cellular automata model of morphogenesis, able to both grow and regenerate specific patterns.
|
|
OpenAI CLIP: https://openai.com/blog/clip/
 |
We’re introducing a neural network called CLIP which efficiently learns visual concepts from natural language supervision.
|
|
Supervisor: Ehsan Pajouheshgar (ehsan.pajouheshgar [at] epfl [dot] ch)
Description:
Startup company Innoview Sàrl has developed software for recovering by smartphone a watermark hidden into an image.The watermark hiding algorithm can be tuned according to a variety of parameters. Develop machine learning methods to distinguish between the watermark of an original and the watermark of a counterfeited document. Propose appropriate parameters.
Deliverables: Report and running prototype (preferably Matlab).
Prerequisites:
– knowledge of machine learning
– basic coding skills in Matlab
Level: BS or MS semester project
Supervisors:
Dr Romain Rossier, Innoview Sàrl, [email protected], , tel
078 664 36 44
Prof. Roger D. Hersch, BC 110, [email protected], cell: 077 406 27 09
Description:
The aim of this project is to train models that generate engaging stories from keywords.
You may for instance start by using a text-generation model (e.g. GPT2-large, GPT-Neo, etc) with a prefix-prompt such as “Keywords: [list of input keywords] Story: ___________ ”. Then you may perform automatic prefix-prompt search or prefix-prompt tuning to improve the performance. You may also fine-tune a part of the text-generation model on datasets of stories, which you first preprocessed to extract keywords.
Tasks:
· Literature review on text generation and datasets, with a focus on story generation works.
· Implementation and evaluation of your own ideas and models.
· Comparison with existing models of text generation
References (examples):
· Yao, Lili, et al. “Plan-and-write: Towards better automatic storytelling.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. No. 01. 2019. https://arxiv.org/pdf/1811.05701.pdf
· Fan, Angela, Mike Lewis, and Yann Dauphin. “Hierarchical neural story generation.” arXiv preprint arXiv:1805.04833 (2018). https://arxiv.org/pdf/1805.04833.pdf
· Akoury, Nader, et al. “STORIUM: A Dataset and evaluation platform for machine-in-the-loop story generation.” arXiv preprint arXiv:2010.01717 (2020). https://arxiv.org/pdf/2010.01717.pdf
· Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
· Li, X. L., & Liang, P. (2021). Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190. https://arxiv.org/pdf/2101.00190.pdf
Deliverables:
Code, well cleaned up and easily reproducible.
Written Report, explaining the literature and steps taken for the project and the performances of the models.
Prerequisites: Python and Pytorch. Knowledge and/or interest into natural language processing.
Level: BS or MS semester project
Supervisor: Martin Nicolas Everaert (martin.everaert [at] epfl.ch)
Description:
DeepFakes are subsets of fake images (especially face images) synthesized with Machine Learning algorithms. First appearing only four years ago, DeepFake generation technology has been evolving in several aspects: quality, speed, and data efficiency. As facial expression and identity are the central parts of social interaction and trust for media, there is a persistent interest in developing robust and efficient DeepFake detection algorithms.
DeepFake videos are DeepFake images’ video counterparts. Moving from images to videos opens up several new possibilities (as what we witnessed in image understanding to video understanding). For instance, video as a time series data offers consistency between frames, but faces in DeepFake videos might not move as usual as in real videos.
In this project, you will first briefly review the state-of-the-art DeepFake video detection methods. Then based on your review, you will reproduce/re-implement a representative subset of them and test them on the FaceForensic++ dataset. Finally, your result should come with quantitative and qualitative comparisons.
For inquiries, feel free to drop an email : )
Level of work
- Senior Bachelor / MS Level, semester project / master project
Prerequisite:
- Knowledge in deep learning frameworks (e.g., PyTorch), image processing and Computer Vision
Supervisor:
- Yufan Ren, [email protected]
Type of work:
- 40% research, 60% development
Deliverables:
- Code, well cleaned up and easily reproducible
- Written Report, explaining the literature and steps taken for the project
References:
[1] FaceForensics++: Learning to Detect Manipulated Facial Images
[2] Deepfake Video Detection through Optical Flow Based CNN
[3] Countering Malicious DeepFakes: Survey, Battleground, and Horizon
Description (Master Semester Project open to EPFL students)
In this project, you will research the existing literature on learning task dependencies in multi-task learning [refer to 1] and focus on the encoder representation of the work. A good reference to work with is [2], however this has to be in the vision domain. Disentangling the task embedding space and learning the task dependencies in a joint-fashion, will be the main aim of the project.
To visualise the task embedding space, you will work with transformer interpretability functions as in [3]. Thereafter you will evaluate the said method against the existing baselines. In doing so, you will learn about the various approaches to improve joint-training on dense vision tasks.
You may contact the supervisor at any time should you want to discuss the idea further.
Reference
[1] http://taskgrouping.stanford.edu/
[2] https://openreview.net/pdf?id=de11dbHzAMF, Pilaut et. al
[3] https://keras.io/examples/vision/probing_vits/
Type of Work (e.g., theory, programming)
40% research, 60% development and testing
Prerequisites
Experience in deep learning, experience in Python, Pytorch. Experience in statistical analysis to report the performance evaluations of the models.
Models will run on RunAI. (We will guide you how to use RunAI- no prior knowledge required).
Supervisor(s)
Deblina BHATTACHARJEE ([email protected])
Description:
Coreference resolution aims at identifying in-text expressions that refer to the same entities.
We are interested in coreference resolution for the downstream task of story visualization. Suppose you are given a story and that one aims to illustrate this story. Can you tell which expressions of the story need to be illustrated similarly? Those expressions may for instance refer to characters/objects or to the scenes where the actions are happening.
Example of what we aim to achieve:
Input story:
- Alice is sitting on a bench. Her friend Bob comes to talk with her. The two characters then go together for a walk in the forest.
A valid output from your model:
- Obj1: A bench ; Character1: A 20-year-old girl ; Character2: A 20-year-old boy ; Scene1: A place with Obj1 ; Scene2: A forest
- In ‘Scene1’, ‘Character1’ is sitting on ‘Obj1’. In ‘Scene1’, ‘Character2’ comes to talk with ‘Character1’. ‘Character1’ and ‘Character2’ then go together for a walk in ‘Scene2’.
Tasks:
- Literature review on coreference resolution and datasets. Ideally focusing on coreference resolution for story visualization if you can find such works.
- Implementation and evaluation of your own ideas and models.
- Comparison with state-of-the-art models for coreference resolution.
References (examples):
- Christopher Manning. “Natural Language Processing with Deep Learning. Lecture 13: Coreference Resolution.”https://web.stanford.edu/class/cs224n/slides/cs224n-2022-lecture18-coref.pdf
- Han, Sooyoun, et al. “FantasyCoref: Coreference Resolution on Fantasy Literature Through Omniscient Writer’s Point of View.” Proceedings of the Fourth Workshop on Computational Models of Reference, Anaphora and Coreference. 2021. https://aclanthology.org/2021.crac-1.3.pdf
- Do Thi, Ngoc Quynh, Steven Bethard, and Marie-Francine Moens. “Adapting coreference resolution for narrative processing.” Proceedings of the 2015 conference on empirical methods in natural language processing. The Association for Computational Linguistics, 2015.https://lirias.kuleuven.be/retrieve/339335
Deliverables:
- Code, well cleaned up and easily reproducible.
- Written Report, explaining the literature and steps taken for the project and the performances of the models.
Prerequisites: Python and Pytorch. Knowledge and/or interest in natural language processing.
Level: MS semester project or MS thesis
Supervisor: Martin Nicolas Everaert (martin.everaert [at] epfl.ch)