Our libraries and archives contain large collections of non-transcribed historical manuscripts from different time periods. These manuscript contain valuable information about our cultural heritage and they are often unique and at the same time very fragile. For these reasons there has been a large interest in their digitization. However, their content is largely unexplored by researchers and the interested public, because after digitization, the content of the manuscript is not easily exploitable. What we create is only a digital image, therefore we need to transcribe the manuscript in order to put its content into machine readable form.
Our aim in this project is to develop methodologies to analyze historical manuscripts and retrieve re-occuring patterns, such that the subsequent transcription of these manuscript requires as little human assistance and interaction as possible. We plan to make use of recent advances in Machine Learning algorithms. These methods will help us learn, in an unsupervised way, text features and patterns specifically tuned to the problem of handwriting recognition.
The success of the above applied algorithms will heavily depend on our ability to define correct patterns to be analyzed in the manuscripts. This will depend on the original condition of the manuscript (faded ink, bleed-through) and also on the digitization parameters. For the above reason we plan, as a second step of our project, to jointly evaluate all the modules in a handwriting recognition system.
A handwriting recognition systems contains the following modules as can be seen in the following figure:
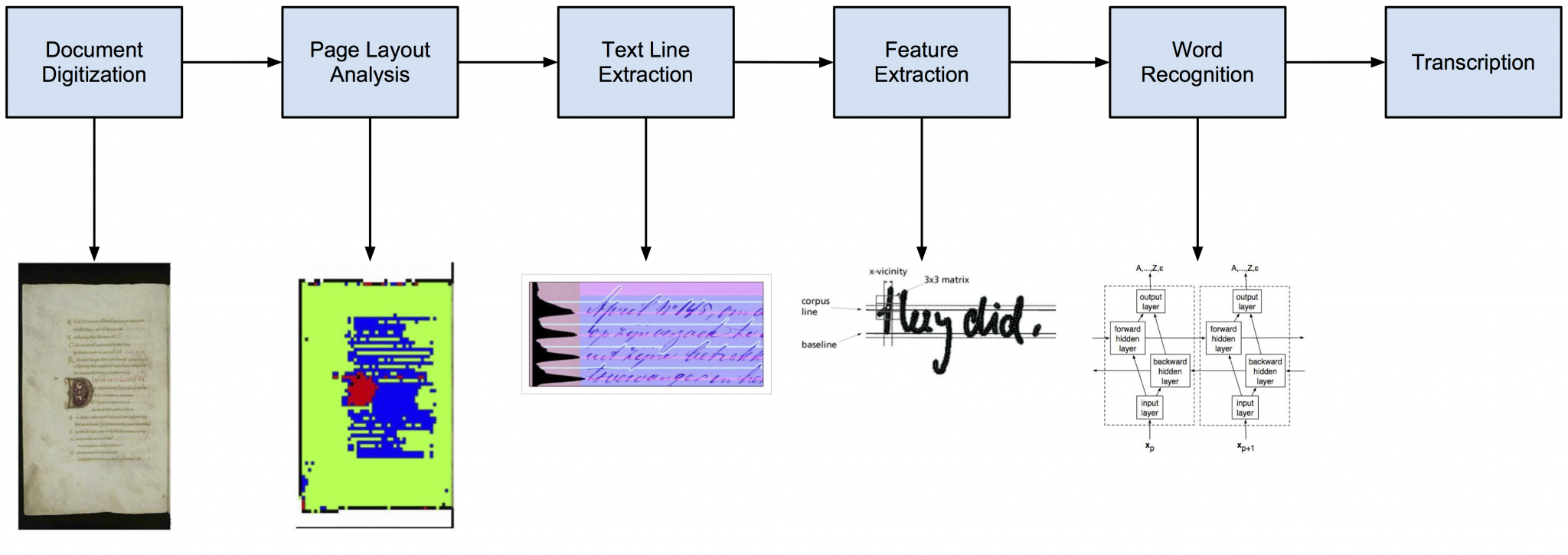
In this project we will deal with manuscripts that contain only text elements, therefore we focus our research in the text line extraction, feature extraction and word recognition modules.
Text line extraction research.
CFRAMUZ Dataset
For more information and download links for the CFRAMUZ dataset, the first historical dataset in French for word-spotting research, please see the dedicated page.