This is a temporary outcome of the work on the WiRE-LES code before possible GPU acceleration.
Scientific relevance
Large-eddy simulation (LES) has become popular in the simulations of atmospheric boundary layers (ABLs) since it is able to reproduce the important turbulence motions with a relatively low computational cost compared with direct numerical simulation (DNS). In LES, the large-scale turbulence is explicitly resolved by solving the spatially filtered Navier-Stokes equations, while the effect of the subgrid-scale (SGS) motions is represented through the parameterization of the SGS stress using a SGS model. During the past years, the Wind Engineering and Renewable Energy (WIRE) laboratory at EPFL has made significant contributions to the development and application of LES. Examples include the development of advanced SGS models, the study of the interactions between large wind farms and ABLs, the characterization of coherent structures in the ABLs, and the investigation of the flow and scalar transports in the ABLs above urban surfaces. Recently, a framework of coupling the mesoscale weather prediction model with the microscale LES model is being developed to yield more accurate simulations of wind and turbulence over complex terrain, hence more reliable forecasts of power productions of wind farms. The LES framework has also been coupled with vegetation dynamics to study the long term impact of land cover changes on wind energy potential.
Technical aspects
The WIRE laboratory has developed the WIRE-LES code for various applications of LES. Characteristics of the code include the staggered grid arrangement and the spatial derivatives of flow variables in the horizontal directions are calculated based on the pseudo spectral method, while the second-order central difference method is used in the vertical direction. This arrangement allows the code to solve the pressure equation (for incompressible flow) efficiently in each time step without the need of iteration. All nonlinear terms in the spatially filtered Navier-Stokes equations are de-aliased in Fourier space by the 3/2 rule. The second-order Adams-Bashforth scheme is used for time marching.
The WIRE-LES code is highly portable and has previously been run on various clusters at the Minnesota Supercomputing Institute, the EPFL HPC Center, the National Center for Atmospheric Research (NCAR), and CSCS. The WIRE-LES code has been written in FORTRAN and parallelized using horizontal slab decomposition and MPI for inter-processor communication. The parallel pressure solver is based on a very efficient direct method which applies FFT in horizontal plans and solves the reduced tridiagonal linear system directly in parallel.
SCITAS support was required to
- Profile-optimize with OpenMP and/or GPU
Results
Performance analysis, profiling report and basic hotspot detection
The profile runs were done on a 512x512x16 regular grid, on a single cluster node. The profiling was performed using Intel VTune Amplifier 2017.
The code has been compiled with:
$ make </pre -mcmodel=large -O3 -xAVX -g -debug inline-debug-info -parallel-source-info=2 -convert little_endian
The modules loaded at compilation time are:
$ module list Currently Loaded Modules: 1) intel/17.0.2 2) intel-mpi/2017.2.174 3) fftw/3.3.6-pl2
The command line used to obtain the traces on a single node has been:
$ srun -n 8 amplxe-cl -quiet -collect hotspots -result-dir $PWD/hotspots -- ./LES2
The collector results are finalized and visualized in the GUI on the head node with:
$ amplxe-gui hotspots
The summary and bottom-up views are shown in the figures below:
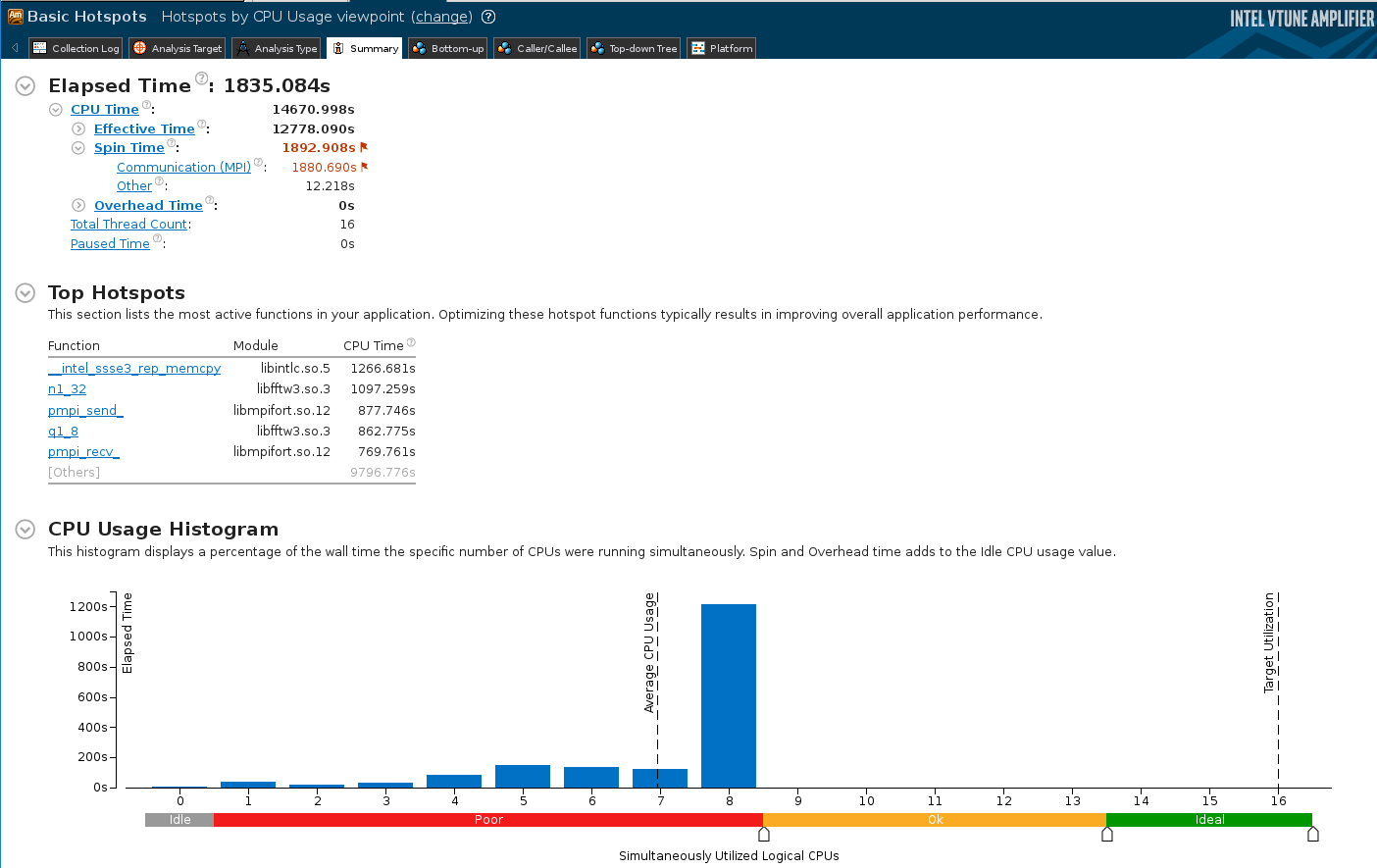
Summary
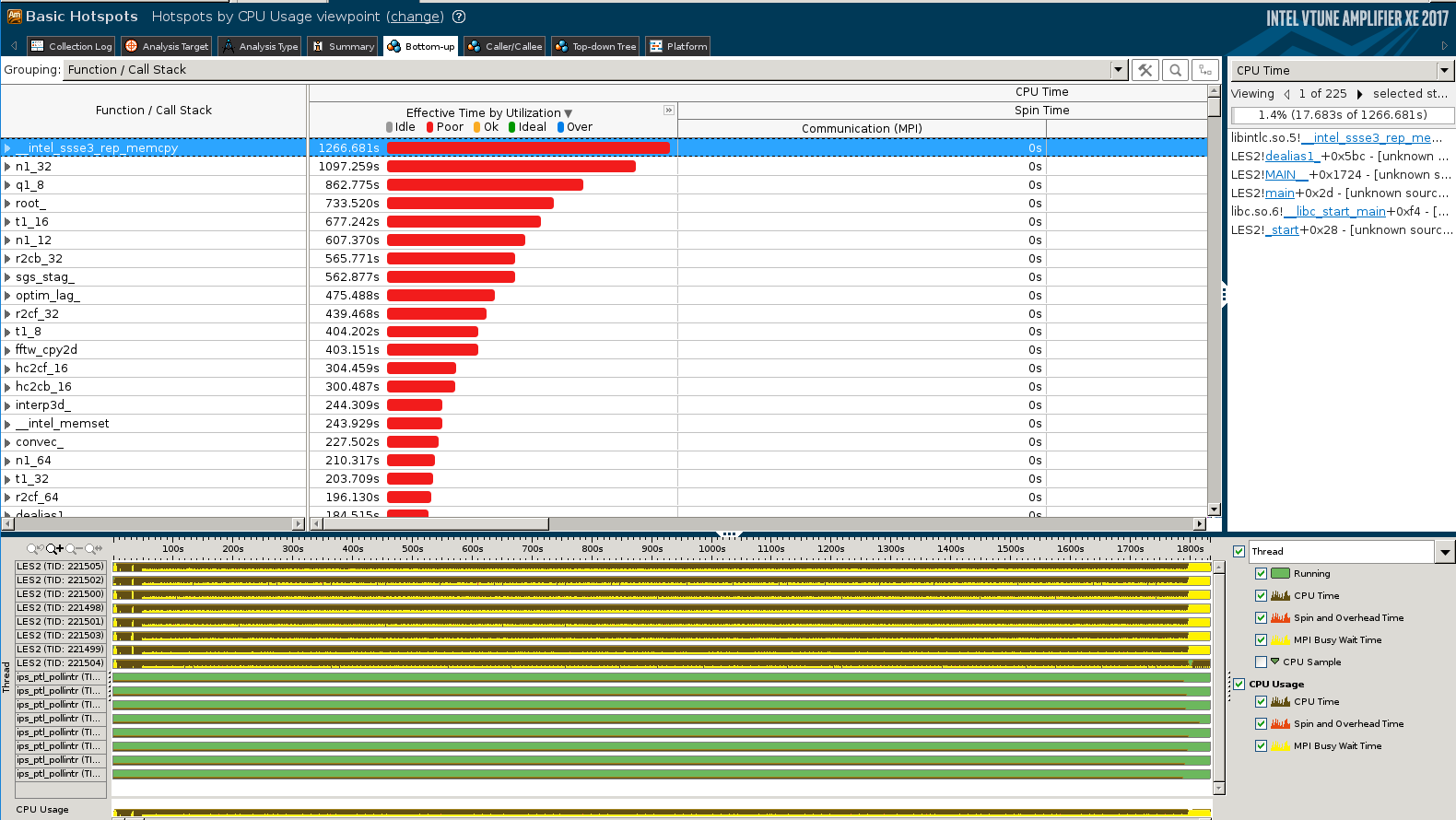
Bottom-up view
The analysis points to three distinct hotspots:
- memory copies (mainly due to copying a slice of 3D array to a temporary 2D array for calling FFT)
- computation of FFT
- computation in the sgs_stag subroutine
Based on the analysis, the following optimizations have been suggested:
- Algorithmic redesign: if possible, avoid the copies from a slice of 3D array to a temporary 2D array
- Use the OpenMP FFTW interface or the cuda’s FFTW interface to accelerate the local FFT computations
- Optimize the sgs_stag subroutine
Optimization
So far, the following optimizations have been performed
- Re-coding several subroutines (mainly dealias1 and dealias2) to avoid the copies from 3D array to intermediate 2D array.
- For the hotspot of FFT calculation, OpenMP has been implemented for all the calculations involving FFT through the OpenMP-enabled FFTW library.
- In the sgs_stag part, a bug of division by zero has been corrected and the re-initialization has been modified to be more robust and efficient.
- The IO part has been refactored to avoid the use of global arrays. This reduces the memory requirement considerably and allows to simulate bigger problems.
For the optimized code with 2 openmp threads per mpi task, the summary and bottom-up views are shown in the figures below:
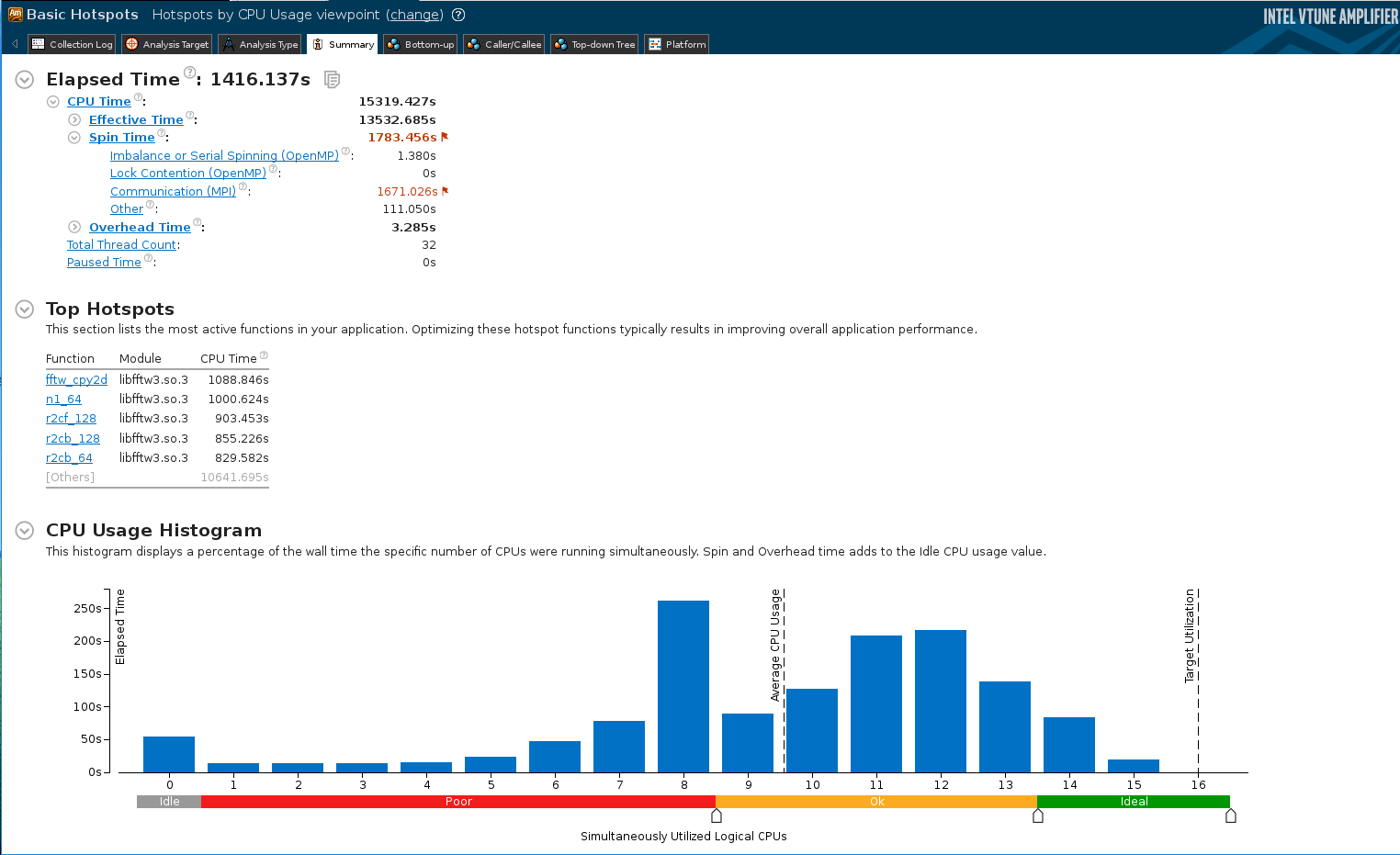
Summary
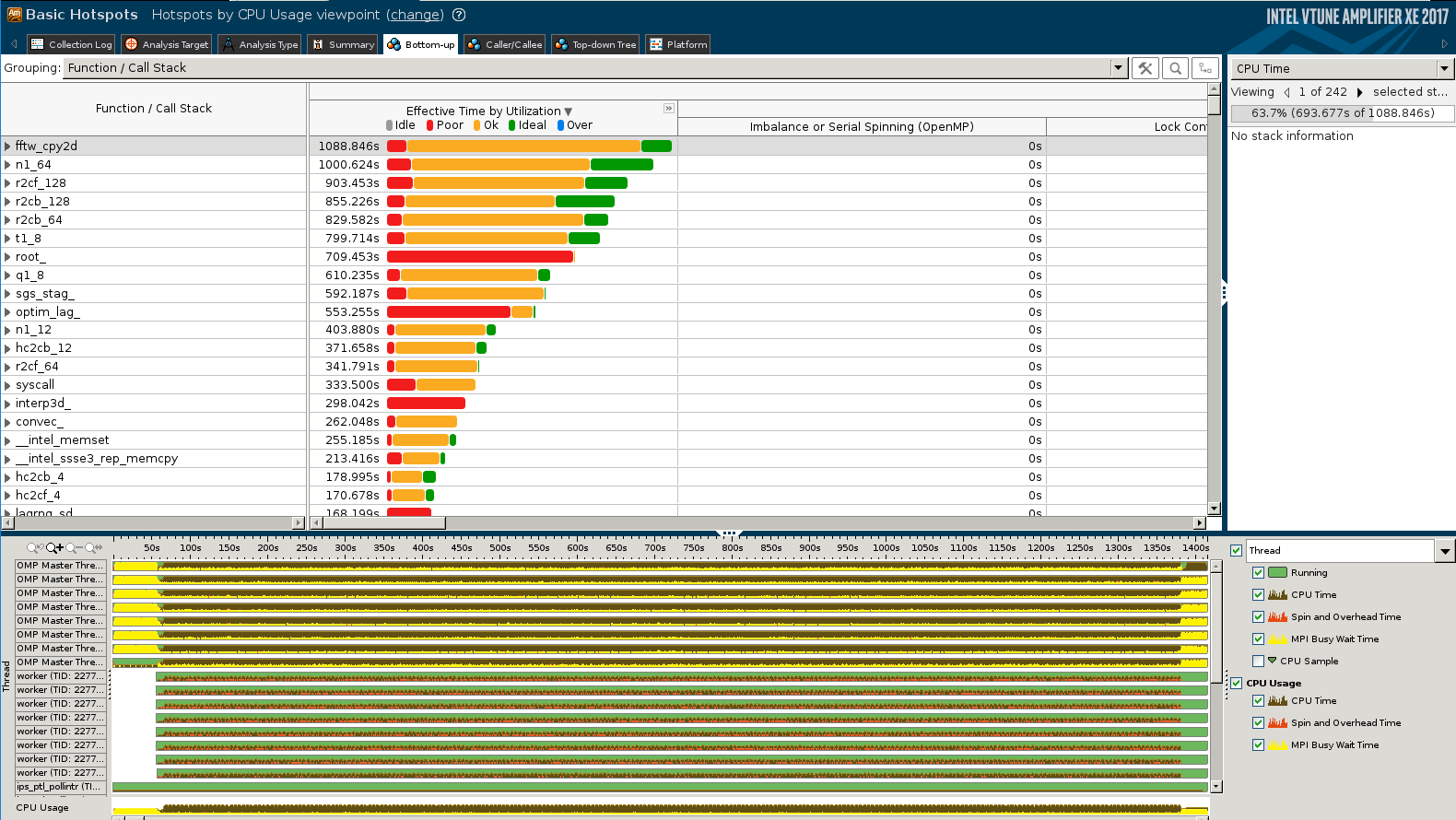
Bottom-up view
With 4 openmp threads per mpi task, the elapsed time was further reduced to 975 s. Temporary conclusions
- The memory copy is not among the top hotspots anymore.
- All the optimizations together lead to a 1.8x speed up (with 4 OpenMP threads)
- The optimized code can simulate problems of bigger size.
Next steps
- Use GPU with the CUDA FFT (?)
- Refactor the WIRE-LES code: from 1D slab domain decomposition to 2D pencil domain decomposition using the open-source library 2DECOMP&FFT
- Transfer sciences of WIRE-LES to the open-source code INCOMPACT3D (?)