Using Big Data on HPC clusters to trace innovations in the marketplace
Scientific relevance
Owing to the importance of innovation in the knowledge economy, a large number of scholars across the social sciences have engaged in the study of the process, diffusion, and incentives of innovation. However, a fundamental issue hampers our understanding of these phenomena: due to its intangible nature, innovation is difficult to observe and, hence, to measure.
This project takes a crucial step towards solving this issue. It proposes a radically new way of tracing innovations in the marketplace. It involves the creation of a large-scale database, the first of its kind, that links commercial products to the patents upon which they are based. Specifically, it develops software capable of harvesting data on products from the web, which can be directly traced to identifiable patents. On many accounts, the data put together represent the holy grail of innovation research. The project offers the most comprehensive attempt at tracing innovations in the marketplace and represents a major leap forward for our understanding of the impact of innovation on society. It will create many opportunities for downstream research, spanning several disciplines in the social sciences.
Assistant Prof. Gaétan de Rassenfosse, Chair of Innovation and Intellectual Property Policy at the College of Management of Technology, leads the project. He has received funding from the U.S. NSF for developing a proof-of-concept.
Technical aspects
The technical challenges associated with building the database are on a par with the research opportunities that it will create. There are two generic challenges: development and execution of the web crawler on the one hand, and extraction and structuring of the data on the other. First, developing and deploying a crawler is no easy task and requires massive computing power. We will develop our crawler on a random sample of the World Wide Web, known as Common Crawl, of which a mirror is hosted by the EPFL high-performance computing center. This will allow us to experiment and refine the search algorithm efficiently and cheaply. We will then deploy the crawler across the whole U.S. and English-language European web.
The second challenge relates to data extraction and structuring. Casual observation suggests that companies present information on product-patent correspondence in highly idiosyncratic ways, and in a format that makes data identification and structuring challenging. Some of the challenges that we foresee include heterogeneous presentation web layouts, information listed in tables in non-OCR PDF files, information buried in soft versions of the deep web such as dynamic pages and publicly accessible forms, and information reported for product lines rather than actual products.
David Portabella is the engineer behind the project. He proposes to automatically learn a page-specific context-free grammar that can parse the web page. The learning algorithm will use heuristic rules based on natural language processing techniques. An alternative approach will rely on Markov logic networks (MLN) by redefining the previous set of NLP rules as formulas and executing a single integrated inference process, which can achieve better results by exploiting so-called belief propagation. In other words, while the first approach consists on heuristics rules applied one after the other (patent numbers identification, segmentation, article title identification and then patent-article correspondence), the second approach applies our equivalent formulas at the same time in an iterative process.
The first step consists in filtering candidate pages from the Common Crawl archive based on regular expressions. The Common Crawl archive is split in 20’000 files of 1GB each, and so the process is easy to parallelize. We will execute it on the HPC cluster at SCITAS. The tables and graphs in this document summarize the first tests run by Gilles Fourestey. Later, we will also apply a Bayesian classifier in this step.
The second step involves the machine learning techniques discussed above to find the match between products and patents. This will be applied in three contexts: (1) in isolation for each candidate web page, (2) in all candidate pages grouped by domain site, and (3) across all candidate pages from all domain sites. This step requires a high-level computational capacity. The SCITAS clusters being historically designed around HPC are a very good fit for this task, with their grand total of 1022 compute nodes, 17536 cores and 500 TFLOPs peak.
Results
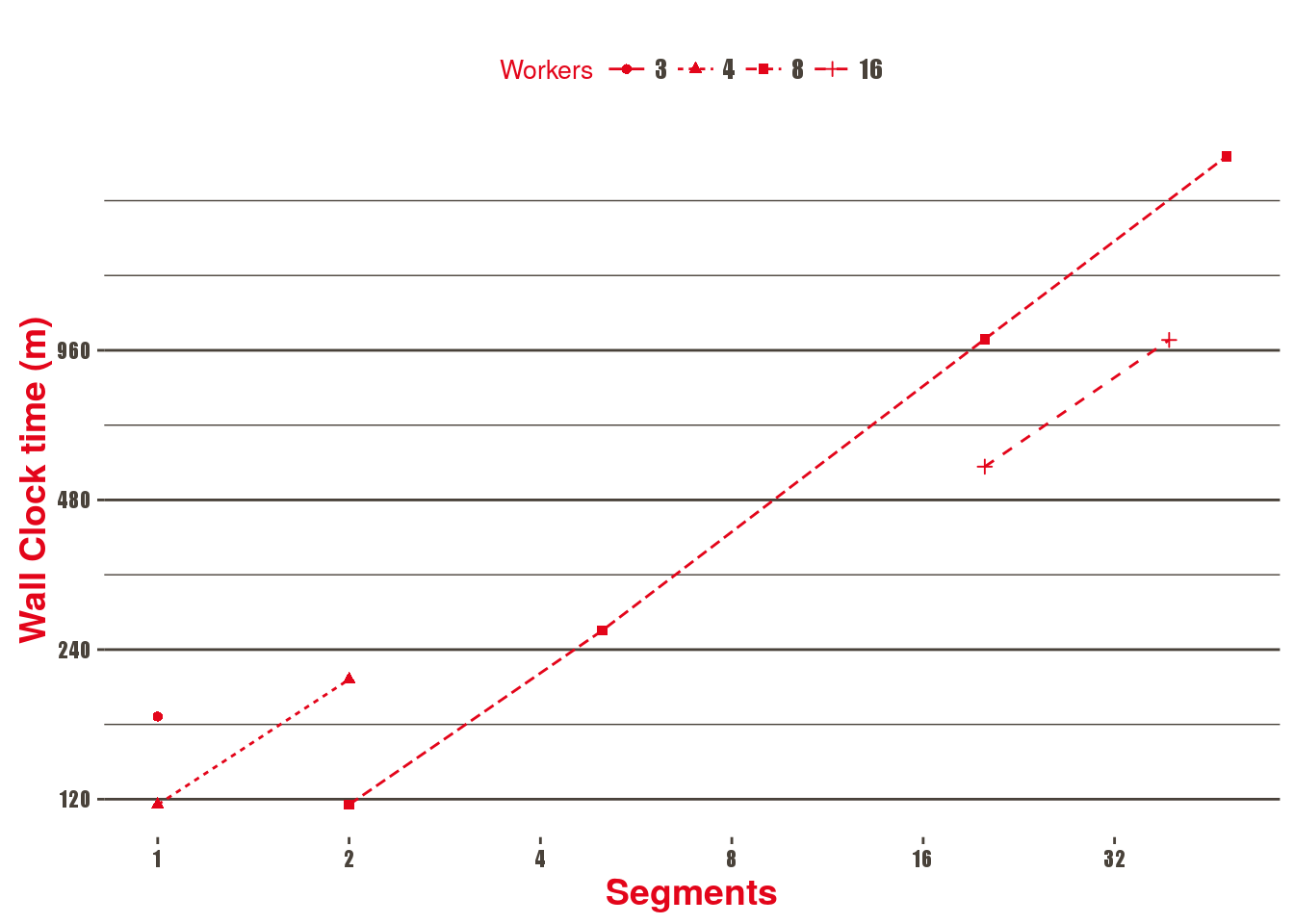
Here, we present scalability results based on different spark node configurations and data sizes as well as an estimation of the total Time To Solution (TTS) for the whole dataset. Data given by Common Crawl is divided into 100 segments that are composed of roughly 300 files of 1GB each.
| Segments | Nodes (workers) | Total Cores | Wall Clock time (m) | Overall GB/s | TTS (days, estimated) |
|---|---|---|---|---|---|
| 1 | 3 | 72 | 176 | 0.03 | 12.20 |
| 1 | 4 | 96 | 117 | 0.04 | 8.12 |
| 2 | 4 | 96 | 209 | 0.05 | 7.25 |
| 2 | 8 | 192 | 117 | 0.09 | 4.06 |
| 5 | 8 | 192 | 262 | 0.10 | 3.63 |
| 20 | 8 | 192 | 1011 | 0.10 | 3.50 |
| 20 | 16 | 384 | 560 | 0.18 | 1.94 |
| 39 | 16 | 384 | 1007 | 0.19 | 1.79 |
| 48 | 8 | 192 | 2358 | 0.10 | 3.28 |
Used software
The HPC clusters at SCITAS use the Slurm workload manager in order to dispatch jobs. Spark is used on the cluster in standalone mode. The following software was used:
Scala programming language combining functional and object-oriented programming. It is scalable, concise and has a static type system. Big companies such as Twitter, LinkedIn and FourSquare use it for big data problems.
Apache Spark: Fast and general engine for large-scale data processing. Spark is installed as a module on SCITAS clusters.
Alchemy2 is a software package providing a series of algorithms based on the Markov logic representation to develop a wide range of AI applications. It is written in C++ and uses Flex and Bison.
Common Crawl is a public archive of the web updated monthly currently hosted at Amazon S3, free to download. The last snapshot contains 1.7 billion pages, 22 TB of data.
Warcbase is a library to read WARC archives (such as CommonCrawl) in Spark.