Scientific relevance
When shear flows such as the flow between two parallel plates but also the flow over an airfoil transition to turbulence, the system shows spatio-temporal intermittency: localized regions of turbulent flow coexist with laminar flow giving rise to evolving laminar-turbulent patterns. These patterns have been studied for more than 70 years yet the mechanisms underlying their emergence and dynamics remain not fully understood.
In the past decade ideas from nonlinear dynamics in combination with advances in numerical simulation techniques have laid the foundation for a new approach to study this phenomenon. This approach is based on constructing exact invariant solutions of the Navier-Stokes equations. These solutions in the form of equilibria, traveling waves and periodic orbits are dynamically unstable, fully 3D and fully nonlinear. Together with their entangled stable and unstable manifolds they form a dynamical network that supports chaotic dynamics. Hence, turbulence can be viewed as a walk between unstable solutions serving as ‘building blocks’ of the dynamics.
We construct those invariant solutions, follow their bifurcation structure and study dynamical connections. To uncover the mechanisms underlying spatio-temporal patterns, large domains need to be studied. In addition to flow of a Newtonian fluid, we recently began to look at viscoelastic fluid models. The aim of this new direction is to understand how tiny amounts of long-chained polymers added to the flow manage to significantly reduce energy dissipation and drag.
Technical aspects
A brief summary of a few relevant aspects of Channelflow is given in the table below:
| Loc | Dependencies | Language | Build system | Operation modes | VCS |
| ~63.000 |
|
C++ | CMake |
|
Git |
The code has no unit tests, but ships with a few full-application tests that need to be configured properly before running. The objective of the initial proposal was to:
- prepare the code for GPU accelerated clusters
- work on general optimizations of the code during the porting process
SCITAS support was required to:
- profile the code and determine major bottlenecks on representative benchmarks
- help with the porting process and determine its feasibility
Results
Performance analysis, profiling report and hotspot detection
As a first step, the code was profiled on Fidis (EPFL) and Greina (CSCS) over a representative benchmark. The outcome was documented in a report that has been delivered to ECPS. A sample of the profiling report is also provided below:
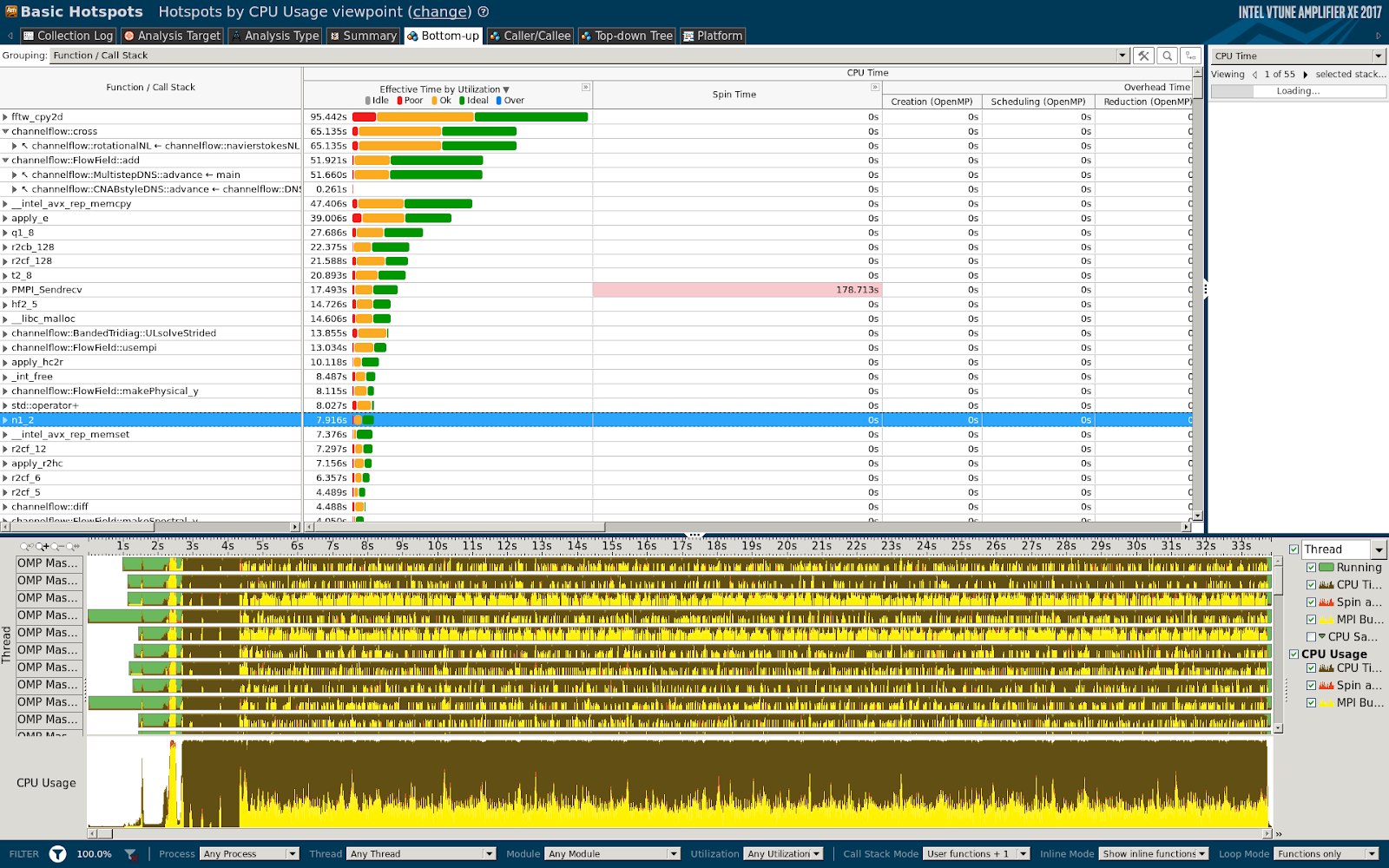
Bottom-up report
Briefly, the profiling showed three major bottlenecks:
- communication imbalance within the calls to FFTW
- computation of the cross product between vectors
- vector addition and multiplication
Vector addition and Multiplication
The vector addition and multiplication resulted to be already fully optimized (i.e. the compiler was already emitting vectorized instructions), and left no further space for improvements.
Cross product optimization
The optimization of the cross product function was identified as the easiest target for optimization, as it was part of Channelflow’s code-base and was a very localized portion of code. A more in depth analysis revealed that the assembly generated for the cross product was suboptimal:
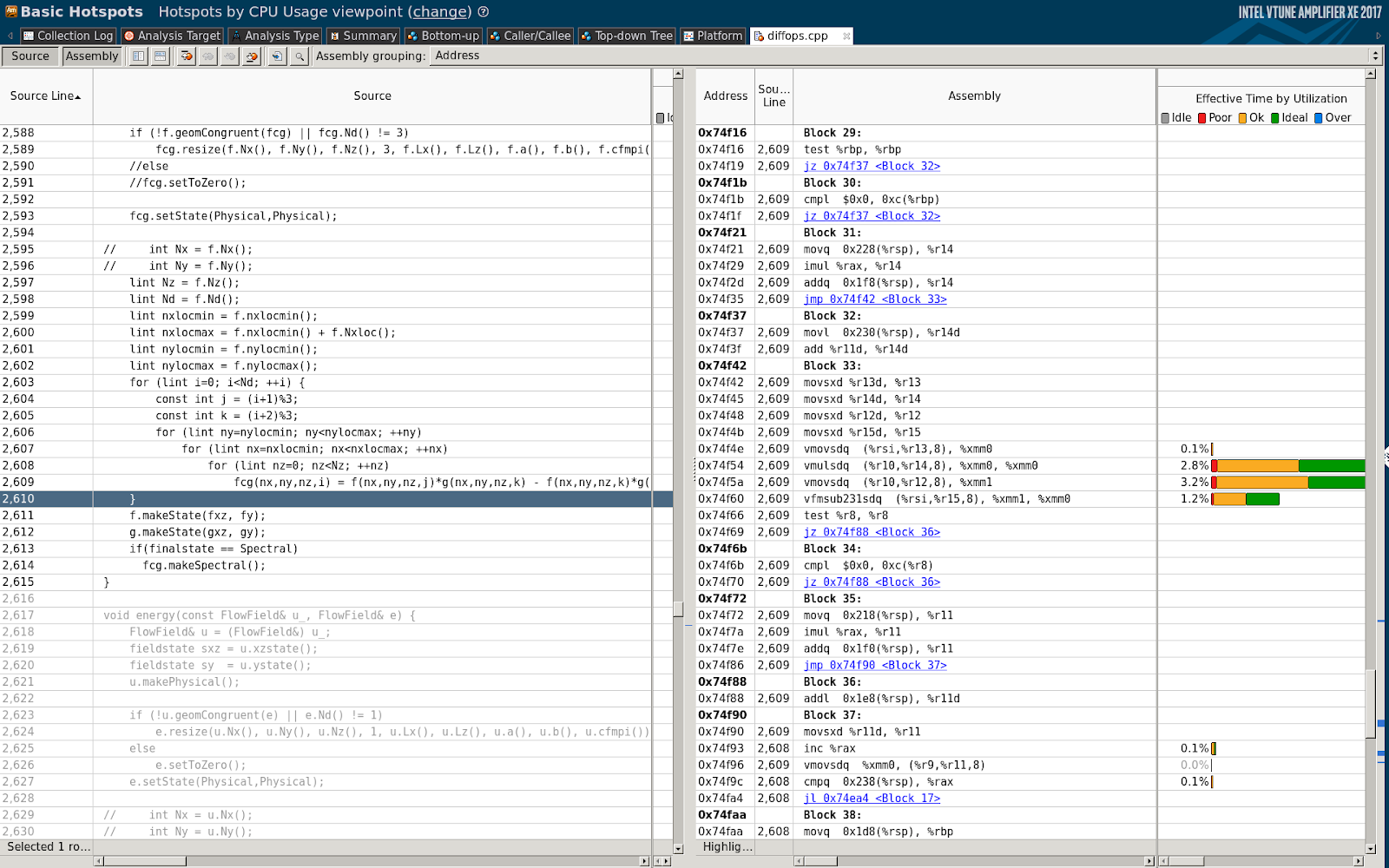
Cross product
Looking at the source files the cause of that was located in a conditional evaluated on every access to a vector element, that very likely prevented speculations at compile time on the memory layout of the underlying array. We decided to unroll this logic (code committed in a branch of the Channelflow repository) and obtained a ~10% improvement in performance on a single node.
Communication imbalance within the calls to FFTW
The communication imbalance within the calls to FFTW constitutes instead a more difficult problem to tackle. The main issues here are that:
- The bottleneck occurs in a call to a 3rd party library function (which can’t be optimized directly)
- It is probably due to algorithmic choices (partition the data by “pencils”, with a very specific data layout) that require an extensive refactor of the entire code base to be changed
This extensive refactor (in particular of the FlowField class) is also needed to port the code to GPU.
Future work: porting the code to GPUs. Analysis.
Porting Channelflow to GPUs entails:
- finding a substitute for FFTW that works on multiple GPUs, possibly distributed over several nodes
- devise a design for the application that permits the selection of the FFT strategy at run-time
The two subtasks are orthogonal, and the second one can also be of interest to try different data layouts that could mitigate the communication bottleneck discussed in the previous section.
AccFFT: a library for distributed memory FFT on CPU and GPU architectures
After an extensive literature search, the only open-source library found that was able to perform distributed FFTs on multiple GPUs was AccFFT. This library uses a pencil distribution with an optimized communication pattern and relies on:
- The serial FFTW libraries to run on CPUs
- cuFFT to run on GPUs
More detailed information on its architecture can be found in this paper. There are a few notable differences with FFTW, that may impact on its use within Channelflow:
- AccFFT doesn’t provide optimized r2r algorithms (like the real even dft of FFTW)
- AccFFT requires a different data layout, and leaves no handles to customize it
In particular AccFFT requires the “fastest” dimension to be local to a process in physical space, and leaves the “slowest” dimension local in spectral space. This probably requires some care as Channelflow currently has no abstraction layer over the layout of data, which is always assumed to be that of the unique pencil decomposition that is currently implemented.
To quickly deploy and benchmark the library over different architectures, we packaged it within Spack:
During the packaging we encountered a couple of major flaws in the code, that required manual intervention to have a succesfull installation. The fix we employed have been merged upstream to AccFFT:
To benchmark the different FFT implemetations, we wrote a few small applications:
and run them on our clusters. The following bar plot shows how two V100 GPUs compare against a node with 28 Intel(R) Xeon(R) Gold 6132 CPU @ 2.60GHz cores, for different modes of operation:
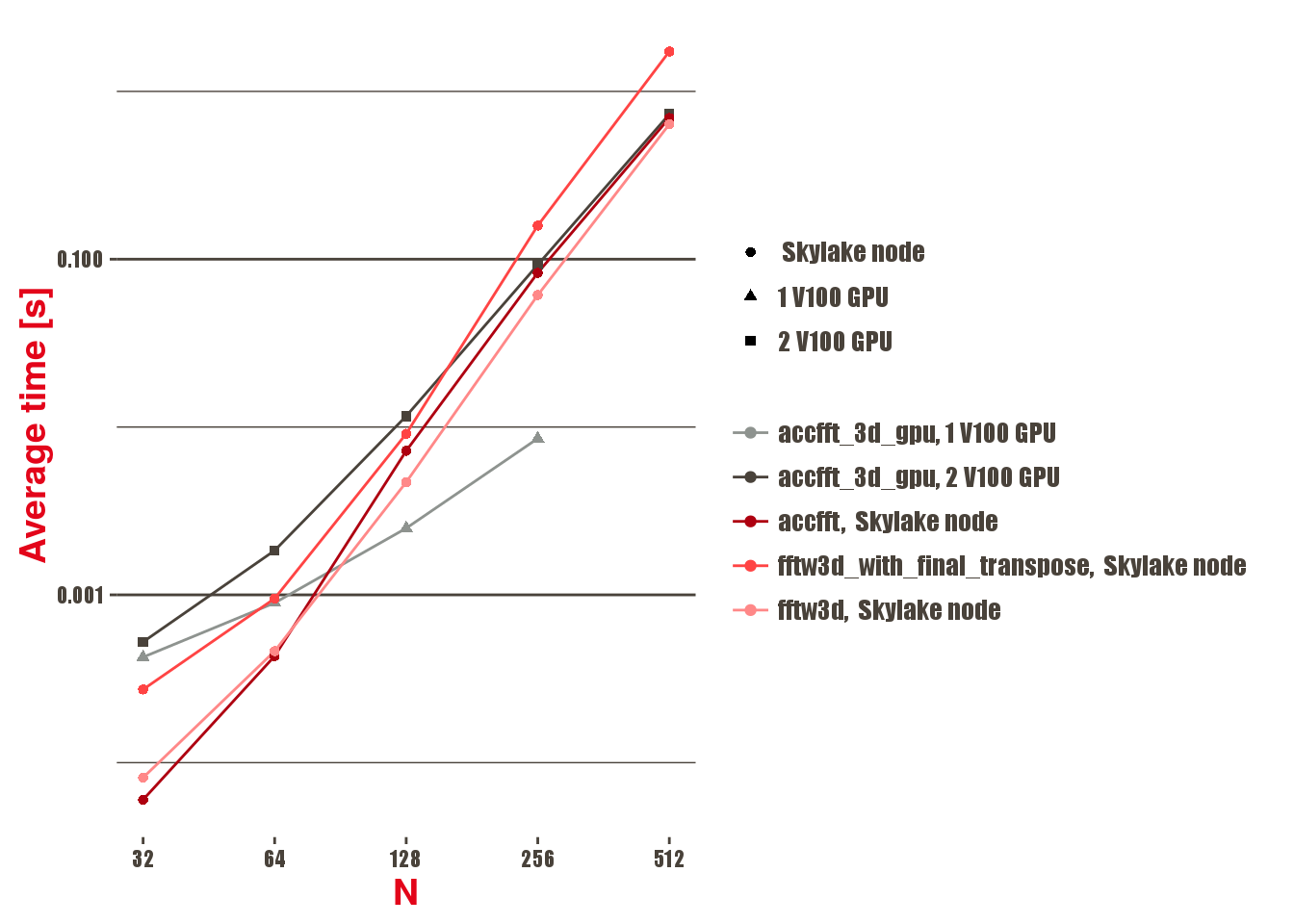
The different sizes of the grids have been chosen to represent sizes that could be of physical interest within the application. What we can see is that, on a single node, CPUs are faster than GPUs for small problem sizes and comparable for the two largest ones.
Used software
- HDF5 + NetCDF + FFTW + MPI + OpenMP (current dependencies of the application)
- AccFFT + cuFFT (library evaluated for inclusion)
- Intel parallel studio (compilers + performance tools, e.g. VTune Amplifier)