
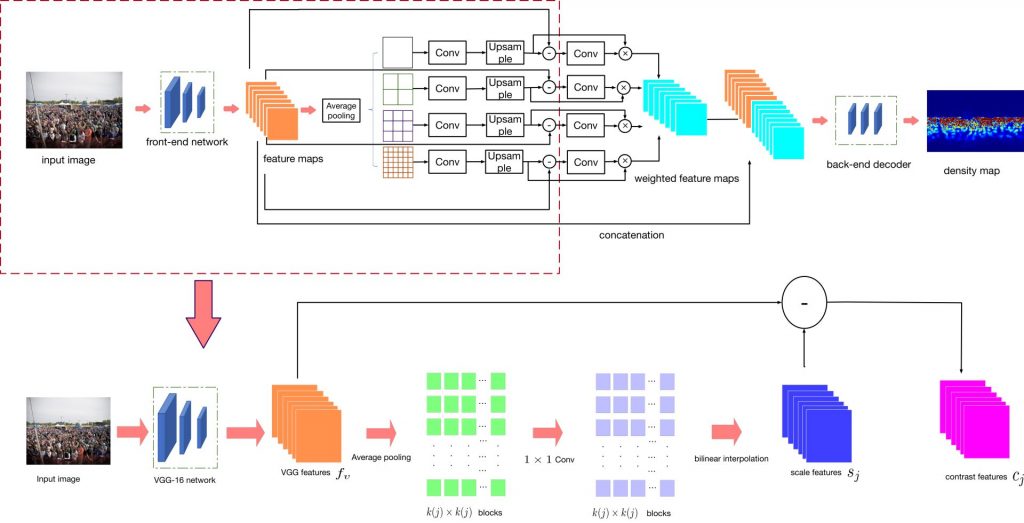
State-of-the-art methods for counting people in crowded scenes rely on deep networks to estimate crowd density. They typically use the same filters over the whole image or over large image patches. Only then do they estimate local scale to compensate for perspective distortion. This is typically achieved by training an auxiliary classifier to select, for predefined image patches, the best kernel size among a limited set of choices. As such, these methods are not endto-end trainable and restricted in the scope of context they can leverage.
In this paper, we introduce an end-to-end trainable deep architecture that combines features obtained using multiple receptive field sizes and learns the importance of each such feature at each image location. In other words, our approach adaptively encodes the scale of the contextual information required to accurately predict crowd density. This yields an algorithm that outperforms state-of-the-art crowd counting methods, especially when perspective effects are strong.
Model
Demo
Code and Dataset
Code and instructions for running it are available here.
The Venice dataset is available for download.
References
Context-Aware Crowd Counting
Conference On Computer Vision And Pattern Recognition (CVPR)
2019-06-20
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, June 16-20, 2019.p. 5094-5103
DOI : 10.1109/CVPR.2019.00524