3-D Facial Reconstruction From Uncalibrated Image Sequences
In recent years, the movie industry has produced such realistic 3–D face models from images that we have come to take them for granted. However, a quick look at the credits at the end of a movie such as “The Matrix Reloaded” and at the budgets that are involved, should alert the careful scientist to the fact that this is a misperception. The extraordinary quality of the models shown in that movie required the use of a studio with five calibrated high resolution cameras, carefully controlled lighting, and an untold number of hours of work. Furthermore the 3–D shapes are often obtained not directly from the images but by laser-scanning a plaster cast of the actors’ faces.
We therefore address the structure-from-motion problem in the context of head modeling from video sequences for which calibration data is not available. This task is made challenging by the fact that correspondences are difficult to establish due to lack of texture and that a quasi-euclidean representation is required for realism. We have developed two distinct approaches based on bundle-adjustment:
- Regularized bundle-adjustment. It takes advantage of our rough knowledge of the head’s shape, in the form of a generic face model. It allows us to recover relative head-motion and epipolar geometry accurately and consistently enough to exploit a previously-developed stereo-based approach to head modeling. In this way, complete and realistic head models can be acquired with a cheap and entirely passive sensor, such as an ordinary video camera with minimal manual intervention.
- Using PCA face models. A few years ago, Blanz & Vetter proposed an impressive appearance-based approach that addresses this issue using a sophisticated statistical head model. It includes shape and texture components that have been learned from a large database of human heads. It allows reconstruction from a single image and uses the Phong illumination model to handle illumination effects, but the shape and texture recovery may be perturbed by large cast shadows or specularities. In our own, work we proposed a technique that reduces the sensitivity to illumination by replacing the texture component of the model by information provided by 2–D point correspondences in all pairs of consecutive images. This helps because such correspondences tend to be affected comparatively little by illumination changes given proper normalization. Furthermore, this approach has the potential for increased automation by eliminating the need for 3–D feature points whose projections are known.
Results
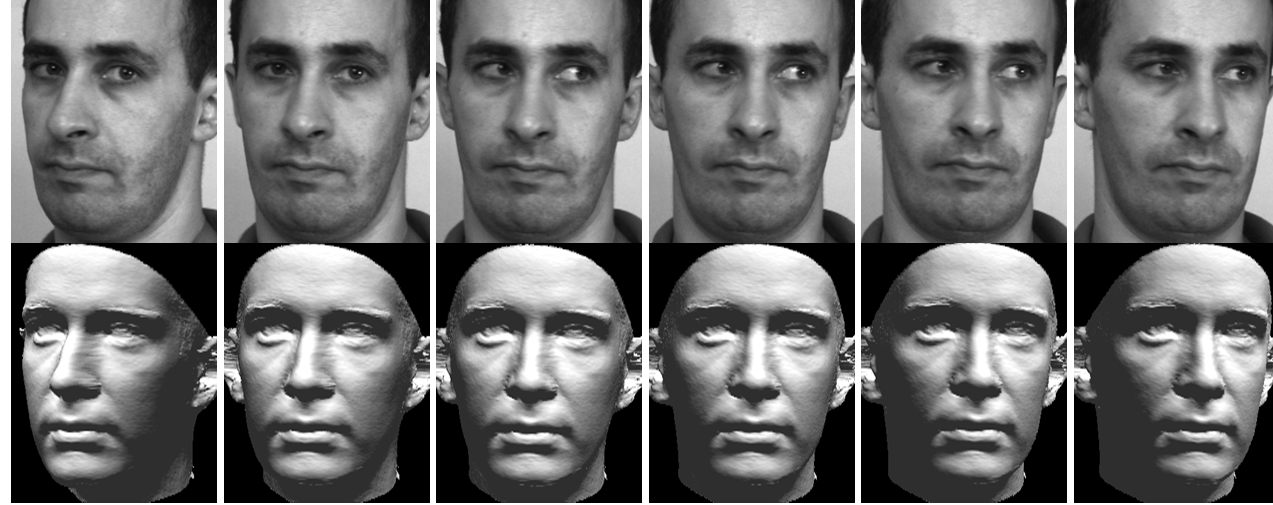
Top row: 6 images of a short sequence. Bottom row: Corresponding reconstruction