Research LineIn and near-memory computing |
Keywords
| In-memory computing, near-memory computing. | ||
Team
 | Ansaloni Giovanni |
 | Choné Clément Renaud Jean |
 | Eggermann Grégoire Axel |
 | Rios Marco Antonio |
Machine learning algorithms like Deep Neural Networks have dramatically improved tasks such as speech/visual recognition, object detection and many other tasks. Although the network training phase requires very powerful Graphics Processing Units (GPU), the inference process can be performed with a much smaller energy budget and computation complexity, making edge devices attractive to deploy such workloads. In fact, 90% of the DNN inference operations are convolutions, which requires word-level multiplications. Thanks to the regularity of their data-access and instructions, these operations benefit from fine-grain parallelism.
However, in conventional Von-Neumann computer architectures, performances of such data-intensive applications are limited due to the disparity of speed between the memory access and the processing units. Additionally, memory access uses orders of magnitude more energy than a bit-wise multiplication. Therefore, to break the memory wall, provide huge parallelism, and reduce energy consumption, In-Memory Computing (IMC) architectures are considered as one of the ultimate solutions.
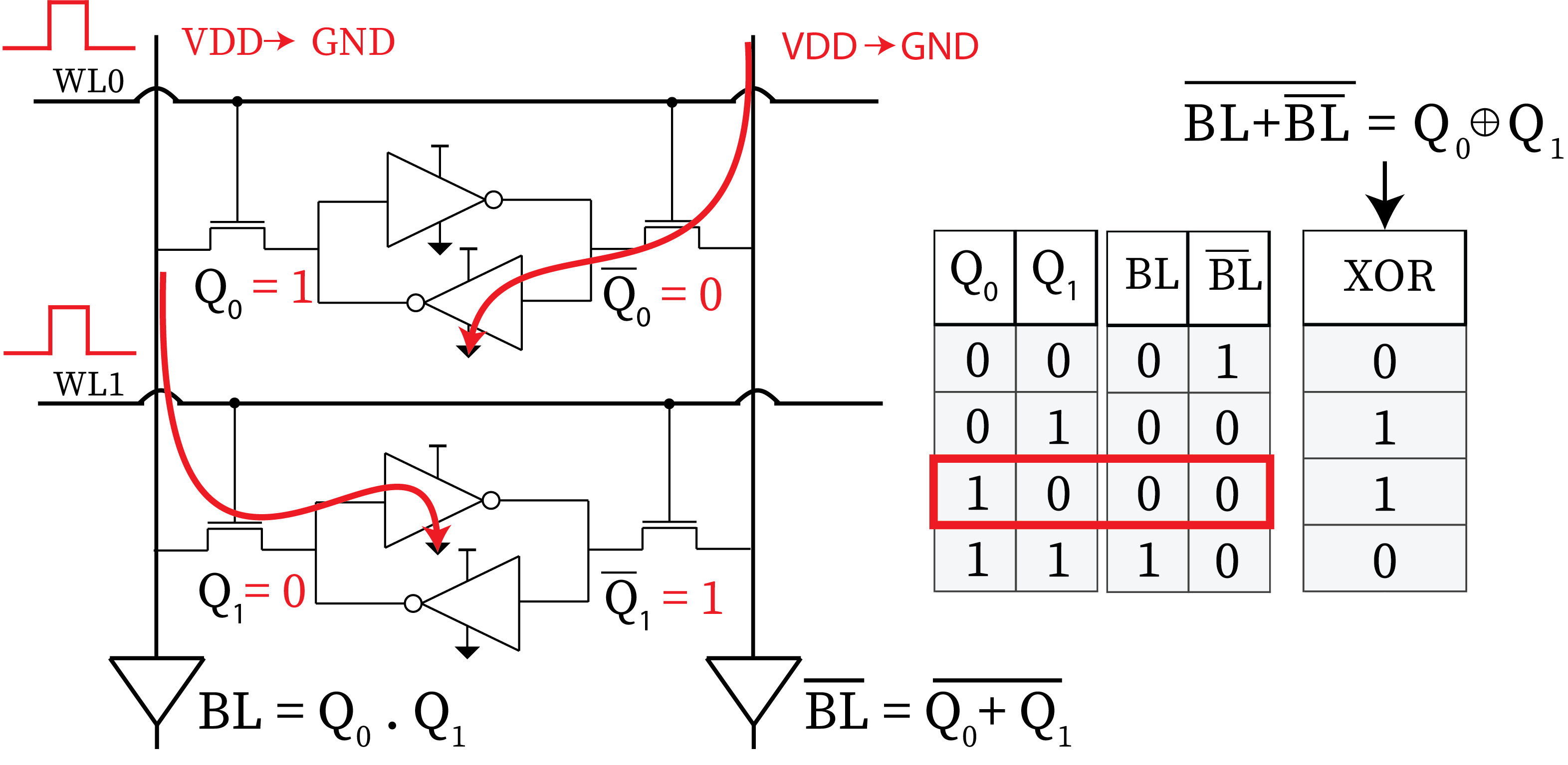
In-SRAM computing is particularly interesting, since it enables seamless integration of SRAM-based IMC architectures with the most advanced standard architectures. Moreover, they are closer to commercial availability thanks to their maturity. In-SRAM can be performed trough bit-line computing: cycle by activating multiple word-lines in an SRAM memory array. This not trivial operation results in bitwise logic operations (AND and NOR) between the accessed words, directly on the bit-lines. It enables SIMD operations on the memory hierarchy while maintaining the inherent geometry of cache memory or other SRAM arrays.
In ESL, we have proposed several architectures based on bit-line computing and several methods of co-design to extract the most in terms of efficiency of these architectures.
Videos
Bit-line computing between two bits
Related Publications
| Keep All in Memory with Maxwell: a Near-SRAM Computing Architecture for Edge AI Applications | |||||
| Eggermann, Grégoire Axel; Ansaloni, Giovanni; Atienza Alonso, David | |||||
| 2025-04-25 | International Symposium on Quality Electronic Design |  |  | ||
| Bit-Line Computing for CNN Accelerators Co-Design in Edge AI Inference | |||||
| Rios, Marco; Ponzina, Flavio; Levisse, Alexandre Sébastien Julien; Ansaloni, Giovanni; Atienza Alonso, David | |||||
| 2023 | IEEE Transactions on Emerging Topics in Computing |  |  |  | |
| Overflow-free compute memories for edge AI acceleration | |||||
| Ponzina, Flavio; Rios, Marco Antonio; Levisse, Alexandre Sébastien Julien; Ansaloni, Giovanni; Atienza Alonso, David | |||||
| 2023 | ACM Transactions on Embedded Computing Systems (TECS) | | |  | |
| A hardware/software co-design vision for deep learning at the edge | |||||
| Ponzina, Flavio; Machetti, Simone; Rios, Marco Antonio; Denkinger, Benoît Walter; Levisse, Alexandre Sébastien Julien; Ansaloni, Giovanni; Peon Quiros, Miguel; Atienza Alonso, David | |||||
| 2022 | IEEE Micro - Special Issue on Artificial Intelligence at the Edge | |  | | |
| Running Efficiently CNNs on the Edge Thanks to Hybrid SRAM-RRAM In-Memory Computing | |||||
| Rios, Marco Antonio; Ponzina, Flavio; Ansaloni, Giovanni; Levisse, Alexandre Sébastien Julien; Atienza Alonso, David | |||||
| 2021-02-01 | DATE 2021 Design, Automation and Test in Europe Conference, Virtual Conference and Exhibition, February 1-5, 2021 | | | | |
| BLADE: An in-Cache Computing Architecture for Edge Devices | |||||
| William Simon, Yasir Qureshi, Marco Rios, Alexandre Levisse, Marina Zapater, David Atienza | |||||
| 2020 | Transactions on Computers 2020 |  | | | |
| An Associativity-Agnostic in-Cache Computing Architecture Optimized for Multiplication | |||||
| Marco Rios, William Simon, Alexandre Levisse, Marina Zapater, David Atienza | |||||
| 2019-10-06 | IFIP/IEEE 27th International Conference on Very Large Scale Integration (VLSI-SoC) 2019 | | |||
| A fast, reliable and wide-voltage-range in-memory computing architecture | |||||
| William Simon, Juan Galicia, Alexandre Levisse, Marina Zapater, David Atienza | |||||
| 2019-06-02 | IEEE/ACM Design Automation Conference (DAC) 2019 | | |||
| BLADE: A BitLine Accelerator for Devices on the Edge | |||||
| W. A. Simon; Y. M. Qureshi; A. Levisse; M. Zapater Sancho; D. Atienza Alonso | |||||
| 2019-05-09 | ACM Great Lakes Symposium on VLSI (GLSVLSI 2019) | | | ||