Project proposal
The Tamedia Image Conciege project has two important and complementary objectives:
- Operationalization of Tamedia’s photo archives. So far images are stored with heterogeneous and non-interconnected management tools.
- Evaluating the various existing tools which allow to search for content with efficiency, speed and comfort in Tamedia’s photo archives. It should be noted that the archived photos, property of Tamedia, have often been incompletely documented when they were integrated into the archive database.
Several outcomes are expected from this project:
- Mobilizing and using a very important visual archive heritage (more than 4.6 million photos in the archives of the various Tamedia titles).
- Enriching the visual content of the editorial production on current events with references to past editorial and visual coverage.
- Reducing the use and costs associated with individual purchases from specialized photo databases, such as Keystone.
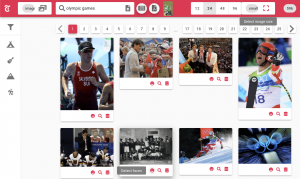
Project outcomes
Four algorithms based on deep-learning models have been developped to enhance the retrieval of images from the Tamedia’s photo archive.
The main motivations were that many images do not have metadata attached, or metadata could be written in multiple languages (French, German or English). As the image search is based on text query, photo editors or journalists from Tamedia are thus not able to retrieve images without metadata or with a metadata in a language different from the query.
The proposed solution was to enable visual search, which means that the search is done at pixel-level instead of metadata-level. The following models have been developed during this project:
- Search by image — Image-to-image retrieval based on image feature vector similarity.
- Search by face — Face-to-image retrieval using face recognition model.
- Search by article — Multi-lingual and multi-modal text-to-image retrieval based on transformer networks.
- Search by key-phrases — Multi-lingual keyphrase-to-image retrieval using aligned word embeddings techniques.
A demonstrator of the search by article is available here.
The operationalization of those four models has been done in 2020 based on the pilot application made by LSIR lab.