In which coordinate frame are objects coded in the human brain? Intuition may suggest a Euclidean, external-world based coordinate system, such as Lausanne is on latitude 46°30′57″ N and longitude 6°37′58″ E. However, this is for obvious reasons not the case (or do you know Lausanne’s coordinates?). Most models of neuroscience rely on a retinotopic coordinate system because neighboring points in the visual field are mapped onto neighboring photoreceptors in the retina and this retinotopic coding principle is maintained in the early visual areas. However, with every eye and head movement, the retinotopic representation of the world is displaced, necessitating non-retinotopic representations to achieve stability. Without these representations, we would be dizzy as it is the case when we move our heads very quickly. Almost nothing is known about how the human brain transforms retinotopic representations into a non-retinotopic coordinate frame. We have developed two behavioral paradigms to pit retinotopic directly against non-retinotopic processing.
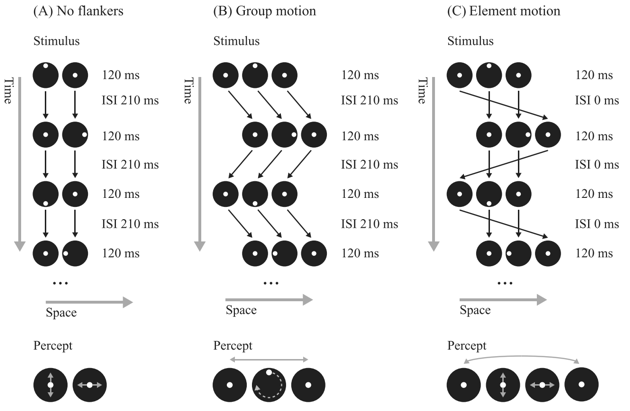
Figure 1: Ternus-Pikler display. (A) In the ‘‘no-flankers’’ condition, two black disks are presented at the same locations separated by an inter-stimulus interval (ISI). A white dot is perceived to be moving up-down in the left disk, and left-right in the right disk. (B) In the group motion condition, a third disk is added either to the left or right of the center disks. When the ISI is sufficiently long, e.g., 100 ms, three disks are perceived to move back and forth as a group. The group-motion creates a non-retinotopic reference frame (see arrows that were not shown in the actual display). Features are integrated according to this non-retinotopic reference frame. A rotating dot is perceived in the center disk which results from the non-retinotopic integration of the retinotopic dot motions of the two center-most disks. The only differences between A and B lie in the outer disks. The percept of rotation is illusory in the sense that, retinotopically, only up-down and left-right motions are present. It is nearly impossible to attend to the retinotopic up-down or left-right motions in the group motion condition. (C) The ‘‘illusory’’ dot motion disappears when the ISI is reduced to 0 ms. Contrary to the group motion condition, the disks now are perceived at four positions: the two center disks at the center positions and the outer disk jumping from the far left to the far right position. As in the no-flankers condition, up-down motion is perceived in the center-left disk and right-left motion in the center-right disk. Figure and Legend adapted from Clarke AM, Repnow M, Öğmen H, Herzog MH (2013).
To this end, we have first modified a demonstration of the Gestaltists Ternus and Pikler, which is shown on the LPSY website and in Figure 1. In the No-Motion condition, motion is perceived according to integration within a retinotopic reference frame. This reference frame and perception strongly change when we added an «uninformative» additional disk alternating either to the left or right. Now, three disks are perceived moving back and forth horizontally. The horizontal motion creates a new, non-retinotopic reference frame, in which a dot rotates within the central disk. However, this rotation is illusory and is the product of the non-retinotopic integration of the up-down and left-right retinotopic motions. It is surprising that the retinotopic motion trajectories are almost invisible (Boi et al., 2009; Lauffs et al., 2018, 2019).
The Ternus-Pikler is, in general, a versatile test of whether a certain paradigm is processed retino- or non-retinotopically. It is like a pizza party. One can just put the stimuli of interest on the disk and pit directly retinotopic against non-retinotopic processing as in the case of the motion example shown above. We found that surprisingly all visual paradigms we tested, except for adaptation, were processed non-retinotopically (Key publications: Boi et al., 2009; Ogmen et al., 2006; Boi et al., 2011; Lauffs et al., 2017).
Neurophysiology and Modelling. At which neural level does non-retinotopic processing occur? We conducted an fMRI study, which showed that the early visual areas encode motion information in a retinotopic fashion, i.e., neurons were activated in a similar fashion for both reference frames (No-Motion and Group Motion condition). The first area that showed non-retinotopic encoding was hMT+ (Thunell et al., 2016a). We propose that the motion of the reference frame is immediately discounted from the motion of the dots at the hMT+ stage. This might be a reason why it is impossible to see the «true» retinotopic motion trajectories. A subsequent EEG study provided further evidence for this hypothesis (Thunell et al., 2016b), which we put into a mathematical framework of vector fields (Ogmen et al., 2010; Clarke et al., 2016; Agaoglu et al., 2016). This model can easily be linked with visual short-term memory (Ogmen & Herzog, 2016).
In a second paradigm, we expanded a classical metacontrast paradigm as shown in Figure 2. Interestingly, observers cannot consciously perceive the preceding vernier. Still, the offset of the invisible vernier is visible at the non-offset flanking lines. Hence, as with the Ternus-Pikler Display, features are integrated within an object based dynamic reference frame (Key publication: Otto et al., 2006). Within this reference frame vernier offsets are unconsciously integrated in an almost linear fashion (Otto et al., 2006). Changes in motion grouping lead to changes in integration (Otto et al., 2008). These results have provoked us to propose a new theory of consciousness. Invisibility of features does not occur because temporal or spatial limitations of the human brain but because the brain does not «want» to see certain interpretations of the external world. Invisibility is interpretation (Herzog et al., 2014).
Other experiments use anorthoscopic perception and are not further described here.
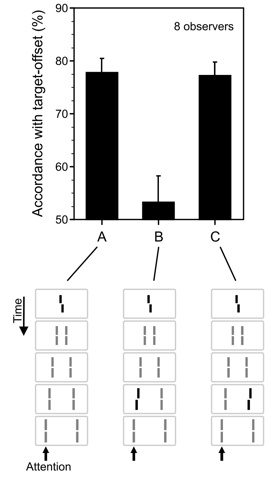
Figure 2: Sequential metacontrast paradigm. (A) The central vernier was randomly offset to the left or right followed by a sequence of non-offset, flanking lines (stream). Observers were asked to attend to one stream of lines, for example, the leftward stream (indicated by the arrow, not shown in actual display). The task was to discriminate the offset direction perceived in the stream. Responses were assessed with respect to their accordance with the target-offset. Although the central vernier was rendered invisible by sequential metacontrast, observers could discriminate the target-offsets very well at the flanking lines. (B) Performance strongly changes by inserting an anti-offset to the penultimate line in the attended motion stream indicating a combination of the two offsets. (C) Performance, compared to panel A, is almost not affected by an anti-offset presented in the non-attended motion stream. In the schematics, offset elements are highlighted in black (in the experimental display, all elements had the same luminance). From: Otto et al., 2006.
Together, the Ternus–Pikler and sequential metacontrast paradigms provide a controlled way to dissociate retinotopic from non-retinotopic computations and to quantify how features are attributed to moving objects rather than fixed retinal locations. Recent work extends this framework toward mechanistic accounts of what is integrated versus what is stored across reference frames, and how unconscious retinotopic signals can still shape conscious non-retinotopic percepts. For a broader discussion of how these mechanisms relate to consciousness, see the Consciousness section.
Publications
Reviews- Öğmen H, Herzog MH (2021). Information integration and information storage in retinotopic and non-retinotopic sensory memory. Vision, 5(4):61, p1-16.
- Herzog MH, Hermens F, Öğmen H (2014). Invisibility and interpretation. Frontiers in Psychology, 5:975, p1-9.
- Herzog MH, Otto TU, Öğmen H (2012). The Fate of Visible Features of Invisible Elements. Frontiers in Psychology, 3(119).
- Öğmen H, Otto TU, Herzog MH (2014). Microstructure of motion correspondence. In: S. Gepshtein and L. Maloney (Eds). The Oxford Handbook of Computational Perceptual Organization.
- Herzog MH, Otto TU (2009). Feature Inheritance. In: T. Bayne, A. Cleeremans, P. Wilken (Eds.). The Oxford Companion to Consciousness. Oxford University Press.
Ternus-Pikler display
- Peñaloza B, Herzog MH, Öğmen H (2020). Non-retinotopic adaptive center-surround modulation in motion processing. Vision Research, 174, p10–21.
- Lauffs MM, Choung O-H, Öğmen H, Herzog MH, Kerzel D (2019). Reference-frames in vision: Contributions of attentional tracking to nonretinotopic perception in the Ternus-Pikler display. Journal of Vision, 19(12):7, p1-15.
- Lauffs MM, Choung O-H, Öğmen H, Herzog MH (2018). Unconscious retinotopic motion processing affects non-retinotopic motion perception. Consciousness and Cognition, 62, p135-147.
- Lauffs MM, Öğmen H, Herzog MH (2017). Unpredictability does not hamper non-retinotopic motion perception. Journal of Vision, 17(9):6, p1-10.
- Thunell E, Van Der Zwaag W, Öğmen H, Plomp G, Herzog MH (2016). Retinotopic encoding of the Ternus-Pikler display reflected in the early visual areas. Journal of Vision, 16(3):26, p1-11.
- Thunell E, Plomp G, Öğmen H, Herzog MH (2016). EEG Correlates of Relative Motion Encoding. Brain Topography, 29(2), p273-282.
- Noory B, Herzog MH, Öğmen H (2015). Retinotopy of visual masking and non-retinotopic perception during masking. Attention, Perception & Psychophysics, 77(4), p1263-1284.
- Noory B, Herzog MH, Öğmen H (2015). Spatial properties of non-retinotopic reference frames in human vision. Vision Research, 113, p44-54.
- Agaoglu MN, Herzog MH, Öğmen H (2015). The effective reference frame in perceptual judgments of motion direction. Vision Research, 107, p101-112.
- Agaoglu MN, Herzog MH, Öğmen H (2015). Field-like interactions between motion-based reference frames. Attention Perception & Psychophysics, 77(6), p2082-2097.
- Herzog MH, Otto TU, Boi M, Öğmen H (2012). When Gestalt processing meets low-level feature integration. Gestalt Theory, 34 3-4, p315-328.
- Aydın M, Herzog MH, Öğmen H (2011). Attention modulates spatio-temporal grouping. Vision Research, 51(4), p435-446.
- Aydın M, Herzog MH, Öğmen H (2011). Barrier effects in non-retinotopic feature attribution. Vision Research, 51(16), p1861-1871.
- Boi M, Öğmen H, Herzog MH (2011). Motion and tilt aftereffects occur largely in retinal, not in object, coordinates in the Ternus-Pikler display. Journal of Vision, 11(3):7, p1-11.
- Boi M, Vergeer M, Öğmen H, Herzog MH (2011). Nonretinotopic Exogenous Attention. Current Biology, 21(20), p1732-1737.
- Boi M, Öğmen H, Krummenacher J, Otto TU, Herzog MH (2009). A (fascinating) litmus test for human retino- vs. non-retinotopic processing. Journal of Vision, 9(13):5, p1-11.
- Scharnowski F, Hermens F, Kammer T, Öğmen H, Herzog MH (2007). Feature fusion reveals slow and fast visual memories. Journal of Cognitive Neuroscience, 19(4), p632-41.
- Öğmen H, Otto TU, Herzog MH (2006). Perceptual grouping induces non-retinotopic feature attribution in human vision. Vision Research, 46(19), p3234-42.
Modelling
- Clarke AM, Öğmen H, Herzog MH (2016). A computational model for reference-frame synthesis with applications to motion perception. Vision Research, 126, p242-253.
- Öğmen H, Herzog MH (2016). A New Conceptualization of Human Visual Sensory-Memory. Frontiers in Psychology, 7:830, p1-15. [⇒ pdf]
- Agaoglu MN, Clarke AM, Herzog MH, Öğmen H (2016). Motion-based nearest vector metric for reference frame selection in the perception of motion. Journal of Vision, 16(7):14, p1-16.
- Clarke AM, Repnow M, Öğmen H, Herzog MH (2013).
Does spatio-temporal filtering account for nonretinotopic motion perception? Comment on Pooresmaeili, Cicchini, Morrone, and Burr (2012). Journal of Vision, 13(10):19, p1-14.
(reply by Pooresmaeili et al.: Spatiotemporal filtering and motion illusions) - Öğmen H, Herzog MH (2010). The geometry of visual perception: Retinotopic and nonretinotopic representations in the human visual system. Proceedings of The IEEE, 98(3), p479-492.
Sequential metacontrast
- Vogelsang L, Menétrey MQ, Drissi-Daoudi L, Herzog MH (2024). Investigating the relationship between subjective perception and unconscious feature integration. Journal of Vision, 24(12), p1.
- Vogelsang L, Drissi-Daoudi L, Herzog MH (2023). Processing load, and not stimulus evidence, determines the duration of unconscious visual feature integration. Communications Psychology, 1(1):8, p1-17.
- Drissi-Daoudi L, Öğmen H, Herzog MH (2021). Features integrate along a motion trajectory when object integrity is preserved. Journal of Vision, 21(12):4, p1–15.
- Drissi-Daoudi L, Öğmen H, Herzog MH, Cicchini GM (2020). Object identity determines trans-saccadic integration. Journal of Vision, 20(7):33, p1-13.
- Otto TU, Öğmen H, Herzog MH (2010). Attention and non-retinotopic feature integration. Journal of Vision, 10(12):8, p1-13.
- Otto TU, Öğmen H, Herzog MH (2010). Perceptual learning in a nonretinotopic frame of reference. Psychological Science, 21(8), p1058-1063.
- Plomp G, Mercier MR, Otto TU, Blanke O, Herzog MH (2009). Non-retinotopic feature integration decreases response-locked brain activity as revealed by electrical neuroimaging. NeuroImage, 48(2), p405-14. [⇒ pdf]
- Otto TU, Öğmen H, Herzog MH (2009). Feature integration across space, time, and orientation. Journal of Experimental Psychology. Human Perception and Performance, 35(6), p1670-86.
- Otto TU, Öğmen H, Herzog MH (2008). Assessing the microstructure of motion correspondences with non-retinotopic feature attribution. Journal of Vision, 8(7):16, p1-15.
- Otto TU, Öğmen H, Herzog MH (2006). The flight path of the phoenix–the visible trace of invisible elements in human vision. Journal of Vision, 6(10), p1079-86.
Anorthoscopic perception
- Ağaoğlu MN, Herzog MH, Öğmen H (2012). Non-retinotopic feature processing in the absence of retinotopic spatial layout and the construction of perceptual space from motion. Vision Research, 71, p10-17.
- Aydin M, Herzog MH, Öğmen H (2009). Shape distortions and Gestalt grouping in anorthoscopic perception. Journal of Vision, 9(3):8, p1-8.
- Aydin M, Herzog MH, Öğmen H (2008). Perceived speed differences explain apparent compression in slit viewing. Vision Research, 48(15), p1603-12.