Vision starts at the retina and continues in more than 40 visual areas. Object recognition is usually assumed to proceed from the analysis of simple features, such as edges and lines in the early visual areas, to more and more complex features in higher visual areas, such as IT.
There are three important characteristics of hierarchical, feedforward processing. First, processing proceeds from basic (lines, edges) to complex (objects, faces) features. Second, processing at each level is fully determined by processing at the previous level. Third, receptive fields increase along the visual hierarchy because objects are more extended than their constituting elements.
There are four crucial implications of these characteristics. First, object recognition always becomes difficult when objects are embedded in clutter because object-irrelevant elements mingle with object-relevant elements. Second, features “lost” at the early stages of processing are irretrievably lost. Third, only nearby elements interfere with each other. Fourth, only low-level features “interact” with each other, such as interactions between lines of the same color and orientation.
In a variety of classic visual paradigms, we found that none of these predictions holds true.
The example of crowding. We presented a vernier stimulus, which comprises two vertical lines offset in the horizontal direction. Human observers had to indicate the offset direction. Performance strongly deteriorated when the vernier is surrounded by the outline of a square. This is a classic crowding effect and well in line with predictions of most models of crowding and object recognition in general because irrelevant information interferes with target processing. Next, we presented further squares on both sides of the square containing the vernier (Figure 1). Classic models propose that performance should deteriorate even further since more distracting information is added. However, performance was almost as good as when the vernier was presented alone. When we turned the flanking squares by 90 degrees creating diamonds, performance was at its worst. We proposed that the repetitive, good Gestalt of the square array creates a high-level structure, which is treated differently from the vernier, which for this reason is clearly perceived and, hence, performance is good. Computationally, the squares must be computed from their constituting lines, grouped as one array, and only then they can interact with the low-level vernier. We showed similar crowding results with other types of stimuli (Key Publications: Malania et al., 2007; Manassi et al., 2012, 2013; Herzog et al., 2015a,b; Manassi et al., 2016; Pachai et al., 2016).
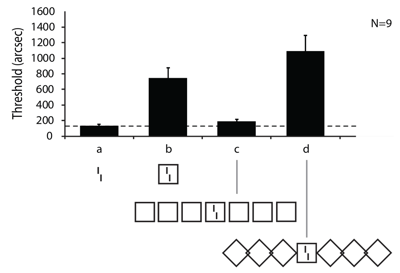
Figure 1: Observers were asked to discriminate whether the vernier was offset to the left or right. We determined the offset size for which 75% correct responses occurred (left bar and dashed line). When the vernier was embedded in the outline of a square, thresholds increased (a-b). When adding three flanking squares on each side, thresholds strongly decreased and crowding disappeared (b-c). When rotating the flanking squares by 90° (d), thresholds increased. Modified from Manassi et al. (2013).
Thus, using crowding as an example, we have shown clear counterevidence to predictions of the classic models of object recognition. A) Adding uninformative elements to a target does not necessarily, as proposed by classic models, deteriorate performance. Bigger can be better. B) Low-level information is not irretrievably “lost”: neither on a low-level nor on any other stage. C) Performance of a target depends on all elements in the visual field and is not restricted to nearby elements. D) Performance depends on the overall configuration of the stimulus, i.e., high-level processing determines low-level processing. For the same reasons, processing cannot be feedforward (Herzog et al., 2016; Jaekel et al., 2016).
Neurophysiology. Where in the human brain does crowding occur? Using high density 192 channel EEG, we could show that high-level areas rather than low-level areas were involved, which argues again against interferences in low-level visual areas (Chicherov et al., 2014).
The examples of visual masking and surround suppression. We obtained very similar results in visual masking and surround suppression and found, as with crowding, only little evidence for the classic vision framework. To the contrary, also in these paradigms, processing is determined by global, Gestalt processing (Key Publications: Herzog & Fahle, 2002; Saarela & Herzog, 2009).
CNNs. We showed that classic feedforward architectures, including CNNs, cannot explain the above (un)crowding results. Models including a recurrent grouping stage however did a good job (Key Publications, Crowding: Francis et al., 2017; Doerig et al., 2019, 2020; Bornet et al., 2019; Masking: Hermens et al., 2008; see also Ghose et al., 2012).
Publications – Crowding
Review- Schwetlick L, Herzog MH (2025). Visual Crowding. JAnnual Review of Vision Science, doi:10.1146/annurev-vision-110423-024409.
- Herzog MH, Sayim B (2022). Crowding: Recent advances and perspectives. Journal of Vision, 22(12):15, p1-4.
- Herzog MH (2022). The irreducibility of vision: Gestalt, crowding and the fundamentals of vision. Vision, 6(2):35, p1-17.
- Herzog MH, Sayim B, Chicherov V, Manassi M (2015). Crowding, grouping, and object recognition: A matter of appearance. Journal of Vision, 15(6):5, p1-18. [⇒ pdf]
- Herzog MH, Manassi M (2015). Uncorking the bottleneck of crowding: a fresh look at object recognition. Current Opinion in Behavioral Sciences, 1, p86-93.
Peripheral vision
- Morea M, Herzog MA, Francis G, Manassi M (2025). Dynamics of vision: Grouping takes longer than crowding. Journal of Vision, 25(12), p16.
- Schwetlick L, Manassi M, Herzog MH, Francis G (2025). Does surface completion fail to support uncrowding? Journal of Vision, 25(3), p1.
- Ozkirli A, Pascucci D, Herzog MH (2025). Failure to replicate a superiority effect in crowding. Nature Communications, 16, p1637.
- Choung OH, Rashal E, Kunchulia M, Herzog MH (2023). Specific Gestalt principles cannot explain (un)crowding. Frontiers in Computer Science, 5:1154957, p1-12.
- Tiurina NA, Markov YA, Choung OH, Herzog MH, Pascucci D (2022). Unlocking crowding by ensemble statistics. Current Biology, 32(22), p4975-4981.
- Choung OH, Bornet A, Doerig A, Herzog MH (2021). Dissecting (un)crowding. Journal of Vision, 21(10):10, p1-20.
- Pachai MV, Doerig AC, Herzog MH (2016). How best to unify crowding? Current Biology, 26(9), R352-R353.
- Manassi M, Lonchampt S, Clarke A, Herzog MH (2016). What crowding can tell us about object representations. Journal of Vision, 16(3):35, p1-13.
- Herzog MH, Thunell E, Öğmen H (2016). Putting low-level vision into global context: Why vision cannot be reduced to basic circuits. Vision Research, 126, p9-18.
- Jaekel F, Singh M, Wichmann FA, Herzog MH (2016). An overview of quantitative approaches in Gestalt perception. Vision Research, 126, p3-8.
- Manassi M, Hermens F, Francis G, Herzog MH (2015). Release of crowding by pattern completion. Journal of Vision, 15(8), p16.
- Manassi M, Sayim B, Herzog MH (2013). When crowding of crowding leads to uncrowding. Journal of Vision, 13(13), p1-10. [⇒ pdf]
- Manassi M, Sayim B, Herzog MH (2012). Grouping, pooling, and when bigger is better in visual crowding. Journal of Vision, 12(10), p1-14.
- Saarela TP, Westheimer G, Herzog MH (2010). The effect of spacing regularity on visual crowding. Journal of Vision, 10(10):17, p1-7.
- Saarela TP, Sayim B, Westheimer G, Herzog MH (2009). Global stimulus configuration modulates crowding. Journal of Vision, 9(2):5, p1-11.
Foveal vision
- Sayim B, Westheimer G, Herzog MH (2011). Quantifying target conspicuity in contextual modulation by visual search. Journal of Vision, 11(1):6, p1-11.
- Sayim B, Westheimer G, Herzog MH (2010). Gestalt Factors Modulate Basic Spatial Vision. Psychological Science, 21(5), p641-644.
- Sayim B, Westheimer G, Herzog MH (2008). Contrast polarity, chromaticity, and stereoscopic depth modulate contextual interactions in vernier acuity. Journal of Vision, 8(8):12, p1-9.
- Malania M, Herzog MH, Westheimer G (2007). Grouping of contextual elements that affect vernier thresholds. Journal of Vision, 7(2):1, p1-7.
Neurophysiology
- Jastrzębowska MA, Chicherov V, Draganski B, Herzog MH (2021). Unraveling brain interactions in vision: the example of crowding. Neuroimage, 240:118390, p1-12.
- Chicherov V, Herzog MH (2015). Targets but not flankers are suppressed in crowding as revealed by EEG frequency tagging. Neuroimage, 119, p325-331.
- Chicherov V, Plomp G, Herzog MH (2014). Neural correlates of visual crowding. Neuroimage, 93 Part 1, p23-31.
Modelling
- Bornet A, Doerig A, Herzog MH, Francis G, Van der Burg E (2021). Shrinking Bouma’s window: How to model crowding in dense displays. PLoS Computational Biology, 17(7), e1009187.
- Bornet A, Choung OH, Doerig A, Whitney D, Herzog MH, Manassi M (2021). Global and high-level effects in crowding cannot be predicted by either high-dimensional pooling or target cueing. Journal of Vision, 21(12):10, p1-25.
- Doerig A, Schmittwilken L, Sayim B, Manassi M, Herzog MH (2020). Capsule networks as recurrent models of grouping and segmentation. PLoS Computational Biology, 16(7):e1008017, p1-19.
- Bornet A, Kaiser J, Kroner A, Falotico E, Ambrosano A, Cantero K, Herzog MH, Francis G (2019). Running large-scale simulations on the Neurorobotics Platform to understand vision-the case of visual crowding. Frontiers in Neurorobotics, 13:33, p1-14.
- Doerig A, Bornet A, Rosenholtz R, Francis G, Clarke AM, Herzog MH (2019). Beyond Bouma’s window: How to explain global aspects of crowding? PLoS Computational Biology, 15(5):e1006580, p1-28.
- Francis G, Manassi M, Herzog MH (2017). Neural Dynamics of Grouping and Segmentation Explain Properties of Visual Crowding. Psychological Review, 124(4), p483-504.
Convolutional Neural Networks (CNNs)
- Lonnqvist B, Bornet A, Doerig A, Herzog MH (2021). A comparative biology approach to DNN modeling of vision: A focus on differences, not similarities. Journal of Vision, 21(10):17, p1-10.
- Doerig A, Bornet A, Choung OH, Herzog MH (2020). Crowding reveals fundamental differences in local vs. global processing in humans and machines. Vision Research, 167, p39-45.
Publications – Overlay masking / Surround suppression
- Saarela TP, Herzog MH (2009). Size tuning and contextual modulation of backward contrast masking. Journal of Vision, 9(11):21, p1-12.
- Saarela TP, Herzog MH (2008). Time-course and surround modulation of contrast masking in human vision. Journal of Vision, 8(3):23, p1-10.
Publications – Masking
Meta-contrast masking- Dombrowe I, Hermens F, Francis G, Herzog MH (2009). The roles of mask luminance and perceptual grouping in visual backward masking. Journal of Vision, 9(11):22, p1-11.
- Duangudom V, Francis G, Herzog MH (2007). What is the strength of a mask in visual metacontrast masking? Journal of Vision, 7(1):7, p1-10.
Masking in general
- Rüter J, Francis G, Frehe P, Herzog MH (2011). Testing dynamical models of vision. Vision Research, 51(3), p343-351.
- Breitmeyer BG, Herzog MH, Öğmen H (2008). Motion, not masking, provides the medium for feature attribution. Psychological Science, 19(8), p823-829.
- Francis G, Herzog MH (2004). Testing quantitative models of backward masking. Psychonomic Bulletin & Review, 11(1), p104-12.
Pattern masking & Shine-through effect
- Ghose T, Hermens F, Herzog MH (2012). How the global layout of the mask influences masking strength. Journal of Vision, 12(13):9, p1-15.
- Hermens F, Scharnowski F, Herzog MH (2010). Automatic grouping of regular structures. Journal of Vision, 10(8):5, p1-16.
- Hermens F, Herzog MH, Francis G (2009). Combining simultaneous with temporal masking. Journal of Experimental Psychology: Human Perception and Performance, 35(4), p977-88.
- Herzog MH, Schmonsees U, Boesenberg JM, Mertins T, Fahle M (2008). Grouping in the shine-through effect. Perception & Psychophysics, 70(5), p887-95.
- Hermens F, Herzog MH (2007). The effects of the global structure of the mask in visual backward masking. Vision Research, 47(13), p1790-7.
- Herzog MH (2007). Spatial processing and visual backward masking. Advances in Cognitive Psychology, 3 1-2, p85-92.
- Herzog MH, Dependahl S, Schmonsees U, Fahle M (2004). Valences in contextual vision. Vision Research, 44(27), p3131-43.
Modeling of masking
- Hermens F, Luksys G, Gerstner W, Herzog MH, Ernst U (2008). Modeling spatial and temporal aspects of visual backward masking. Psychological Review, 115(1), p83-100.
Dyslexia, Development & Visual Backward Masking
- Pilz KS, Kunchulia M, Parkosadze K, Herzog MH (2016). Spatial and temporal aspects of visual backward masking in children and young adolescents. Attention Perception & Psychophysics, 78(4), p1137-1144.
- Doron A, Manassi M, Herzog MH, Ahissar M (2015). Intact crowding and temporal masking in dyslexia. Journal of Vision, 15(14):13, p1-17.