The problem of vision. We open our eyes and seem to effortlessly perceive the world with all of its objects. Vision is easy for healthy humans but not effortless for the human brain. A third of the neocortex, including 40 highly specialized areas, is devoted to the analysis of vision (Felleman et al. 1991; van Essen et al. 1992). What makes vision so complicated is that the retinal representation of a visual scene reflects only the luminance values of the scene. It does not tell which elements make up objects. For example in figure 1, the word “object” is easy to spot. However, the human brain needs first to segment the single letters from the background and then must combine the non-adjacent letters into a word.
The Gestaltists were the first to systematically study how elements make up wholes and proposed a number of rules for how elements group together (Korte, 1923). However, it quickly turned out that the perception of an object cannot be explained by the perception of its parts. The relationship between parts and their wholes turned out to be too enigmatic. The project “Gestalt theory” failed for this and other reasons.
After World War II, a new research direction emerged, which is, explicitly or implicitly, at the very heart of most of modern vision research. At the core of these models is a hierarchical, feedforward processing step, which proceeds from the analysis of basic features to more and more complex ones (Riesenhuber and Poggio, 1999; Serre et al. 2007). Neurons at the retina detect changes in luminance but cannot, for example, discriminate the orientation of a line. Receptive fields are small and concentric. These neurons project to the primary visual cortex (V1) such that V1 neurons become edge and line detectors (Figure 1; Hubel and Wiesel 1962, 1968). It is thought that this basic encoding principle continues throughout the visual system and can be viewed as a Lego toy building block hierarchy: basic building blocks of perception, such as lines and edges, are the basis for the analysis of complex shapes such as objects and faces. For example, a hypothetical square-detecting neuron is “created” by projections from neurons coding for the square´s constituent horizontal and vertical lines (Figure 1).
However, this approach cannot explain even the purportedly first steps of visual processing as we have shown with many examples.
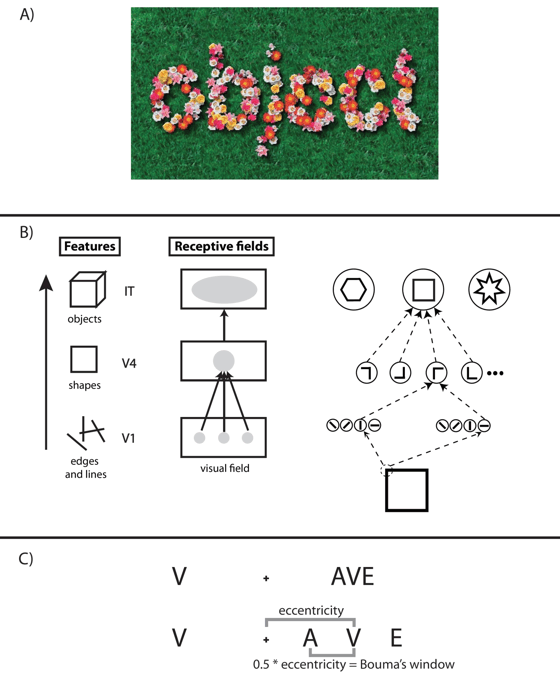
Figure 1: (A) It is easy to recognize the word “object” even though is it made up of different flowers, which are complex objects themselves. (B) Neurons in V1 are sensitive to simple features, such as edges and lines. In higher visual areas, neurons are sensitive to more and more complex features, such as shapes (V4) and objects (IT). Receptive field sizes increase from lower to higher visual areas. Hierarchical, feedforward models of object recognition formalize these neurophysiological findings (e.g., Riesenhuber and Poggio, 1999). Stimulus processing starts with the analysis of very simple features and proceeds to more and more complex visual representations. A hypothetical “square” neuron receives input from neurons tuned to angles, which in turn receive inputs from line detectors. Along the hierarchy, processing at each level is fully determined by processing at the previous level. (C). Crowding. When fixating the central cross, it is easy to recognize the letter V on the left but difficult on the right because of the flanking letters. Crowding is usually thought to occur only for flankers presented within a window of half the eccentricity of target presentation (Bouma’s law; Bouma, 1970). When flankers are placed outside Bouma’s window, letter recognition is not compromised. From Herzog & Manassi, 2015.
References
- Bouma H (1970). Interaction effects in parafoveal letter recognition. Nature 226 (1970): 177-178.
- Felleman DJ, Van Essen DC (1991). Distributed hierarchical processing in the primate cerebral cortex. Cerebral cortex 1.1 (1991): 1-47.
- Herzog MH, Manassi M (2015). Uncorking the bottleneck of crowding: a fresh look at object recognition. Current Opinion in Behavioral Sciences, 1, 86-93.
- Hubel DH, Wiesel TN (1962). Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. The Journal of physiology 160.1: 106.
- Hubel DH, Wiesel TN (1968). Receptive fields and functional architecture of monkey striate cortex. The Journal of physiology 195.1: 215-243.
- Korte W (1923). Über die Gestaltauffassung im indirekten Sehen (On the apprehension of Gestalt in indirect vision). Zeitschrift für Psychologie, 93, 17-82.
- Levi DM (2008). Crowding – An essential bottleneck for object recognition: A mini-review. Vision research, 48(5), 635-654.
- Riesenhuber M, Poggio T (1999). Hierarchical models of object recognition in cortex. Nat Neurosci 2(10526343): 1019-1025.
- Serre T, Aude O, Poggio T (2007). A feedforward architecture accounts for rapid categorization. Proceedings of the National Academy of Sciences 104.15 (2007): 6424-6429.
- Whitney D, Levi DM (2011). Visual crowding: a fundamental limit on conscious perception and object recognition. Trends in cognitive sciences, 15(4), 160-168.
- Van Essen DC, Anderson CH, Felleman DJ (1992). Information processing in the primate visual system: an integrated systems perspective. Science 255.5043: 419-423.