Running analytics over large datasets has become an important aspect of many businesses. Traditionally data analytics have been performed by using data warehouses which store data in a fixed format with predefined schemas. In order to perform analytics in data warehouses, the input data needs to be transformed using time-consuming Extract-Process-Load (ETL) pipeline before it is ready for running queries. The data schema may also change over time which may not be easy to accommodate in data warehouses since data warehouses have a rigid schema.
Data lakes provide a platform to run queries and perform data analytics over large amounts of data in its original format. This removes the overhead of using expensive ETL processes as well as allows the data schema and the format to be flexible. The SmartDataLake Project (https://smartdatalake.eu/) aims to design, develop and evaluate novel approaches and techniques for extreme-scale analytics over Big Data Lakes, facilitating the journey from raw data to actionable insights.
Data Management for SmartDataLake
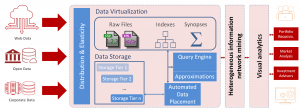
In the context of the SmartDataLake project, we address issues with data querying and data storage.
Virtualized and Adaptive Data Access
Data lakes work on data in their native format. In SmartDataLake, we have developed a query engine that provides a data virtualization layer which hides the complexity of the underlying data formats from the user. The query optimizer and execution engine automatically figure out the underlying data format to efficiently access and run queries across heterogeneous data formats.
Approximate Query Processing
Running analytical queries on large datasets is expensive both in terms of time and resources. For several applications, for example scientific exploration, an accurate result to the query is not required. Faster approximate results, with error guarantees, are more desirable. The SmartDataLake system will use data sampling along with different types of data synopses to answer approximate queries over raw data.
Automated and Adaptive Data Storage Tiering
Modern storage devices provide different levels of cost vs. performance trade-offs. In SmartDataLake, we are working on automatically placing data in the storage hierarchy so as to optimize the data access. Data access requirements may also change over time. Our storage engine will adaptively move data across different storage devices.
Distribution and Elasticity
The SmartDataLake project will allow for executing queries at scale by leveraging elasticity and distribution aware query planning. Resource allocation for query execution will take into account load balancing and resource utilization.
![]()
This project uses Proteus DBMS (proteusdb.com).
Project Website: https://smartdatalake.eu
Project Partners:
Funding:
