Scalable Locking
While hardware technology has undergone major advancements over the past decade, transaction processing systems have remained largely unchanged. The number of cores on a chip grows exponentially, following Moore’s Law, allowing for an ever-increasing number of transactions to execute in parallel. As the number of concurrently-executing transactions increases, contended critical sections become scalability burdens. In typical transaction processing systems the centralized lock manager is often the first contended component and scalability bottleneck. [9, 10]
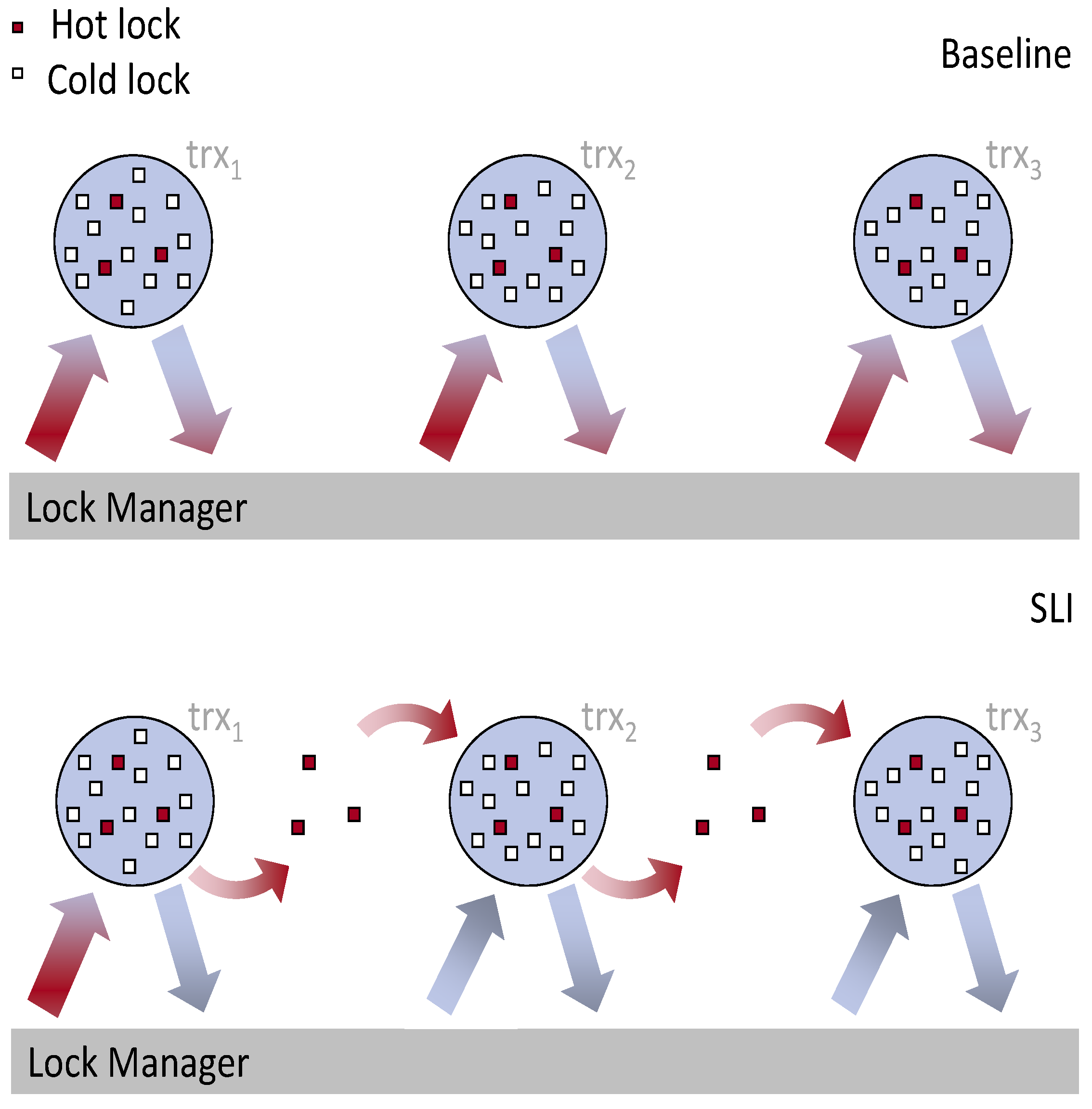
Speculative Lock Inheritance (SLI) [8]: This project highlights the negative scalability impact of database locking, an effect which is especially severe for short transactions running on highly concurrent multicore hardware. We propose and evaluate Speculative Lock Inheritance (SLI), a technique where hot database locks pass directly from transaction to transaction, bypassing the lock manager bottleneck. We implement SLI in the Shore-MT storage manager and show that lock inheritance fundamentally improves scalability by decoupling the number of simultaneous requests for popular locks from the number of threads in the system, eliminating contention within the lock manager even as core counts continue to increase. We achieve this effect with only minor changes to the lock manager and without changes to consistency or other application-visible effects.
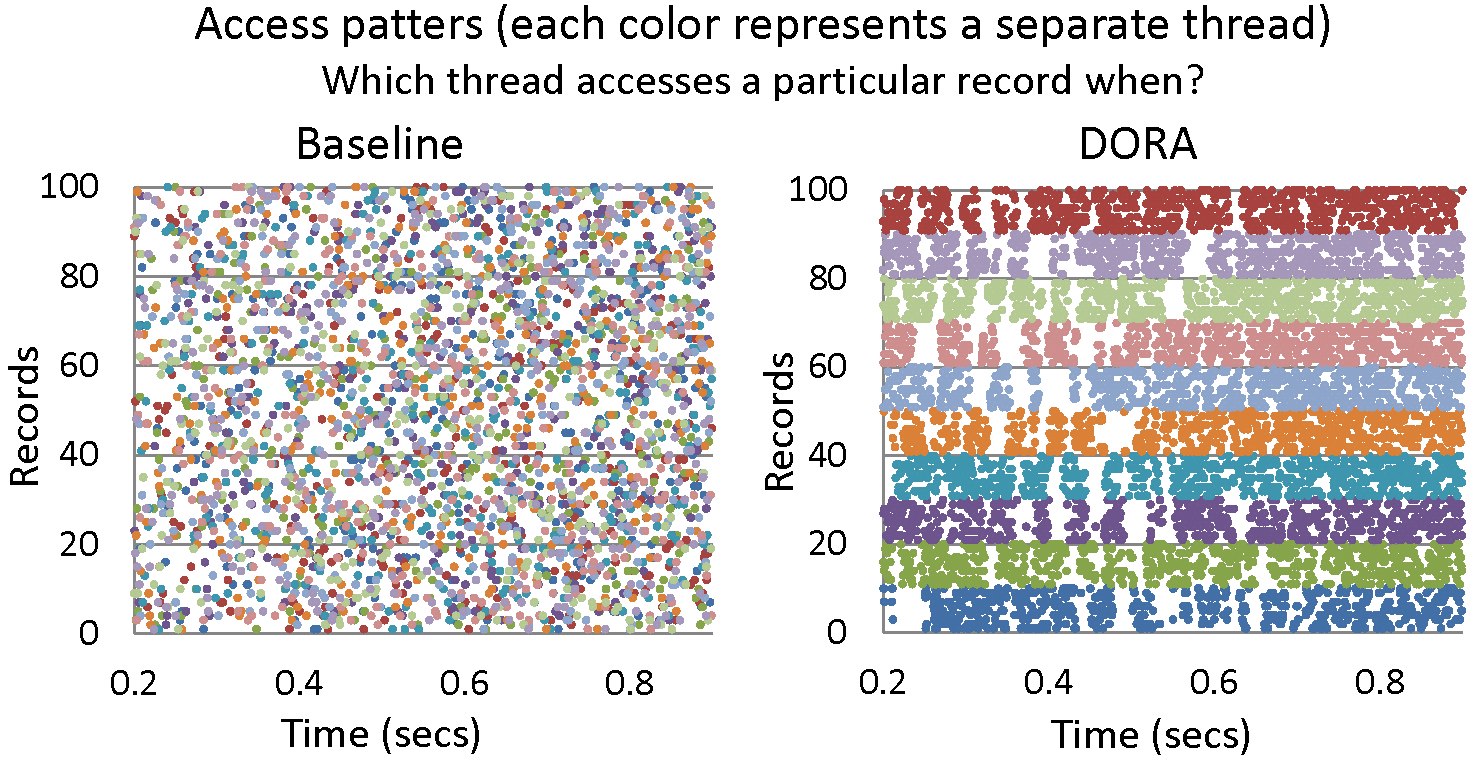
Data-Oriented Transaction Execution (DORA) [4, 6]: We identify the conventional thread-to-transaction assignment policy as the primary cause of contention. Then, we design DORA, a system that decomposes each transaction to smaller actions and assigns actions to threads based on which data each action is about to access. DORA’s design allows each thread to mostly access thread-local data structures, minimizing interaction with the contention-prone centralized lock manager. Built on top of a conventional storage engine, DORA maintains all the ACID properties. Evaluation of a prototype implementation of DORA on a multicore system demonstrates that DORA attains up to 4.8x higher throughput than a state-of-the-art storage engine when running a variety of synthetic and real-world OLTP workloads.
Scalable Logging
Write-ahead logging is a fundamental, omnipresent component in ARIES-style concurrency and recovery, and one of the most important yet-to-be addressed potential bottlenecks, especially in OLTP workloads making frequent small changes to data.
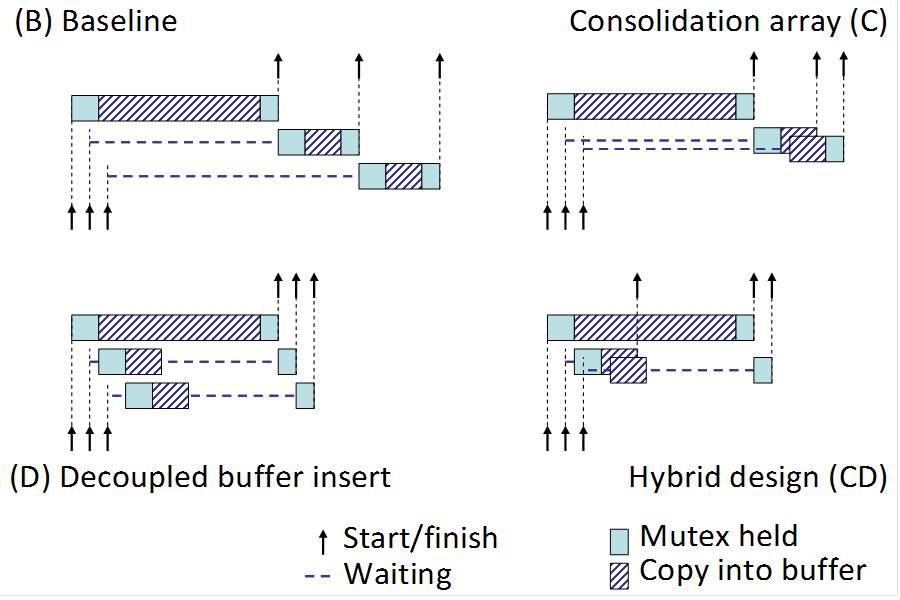
Aether [2, 5, 7]: We identify four logging-related impediments to database system scalability. Each issue challenges different level in the software architecture: (a) the high volume of small-sized I/O requests may saturate the disk, (b) transactions hold locks while waiting for the log flush, (c) extensive context switching overwhelms the OS scheduler with threads executing log I/Os, and (d) contention appears as transactions serialize accesses to in-memory log data structures. We demonstrate these problems and address them with techniques that, when combined, comprise a holistic, scalable approach to logging. Our solution achieves a 20%-69% speedup over a modern database system when running log-intensive workloads, such as the TPC-B and TATP benchmarks. Moreover, it achieves log insert throughput over 1.8GB/s for small log records on a single socket server, an order of magnitude higher than the traditional way of accessing the log using a single mutex.
Scalable Latching
Scaling the performance of shared-everything transaction processing systems to highly-parallel multicore hardware remains a challenge for database system designers. Recent proposals alleviate locking and logging bottlenecks in the system, leaving page latching as the next potential problem.
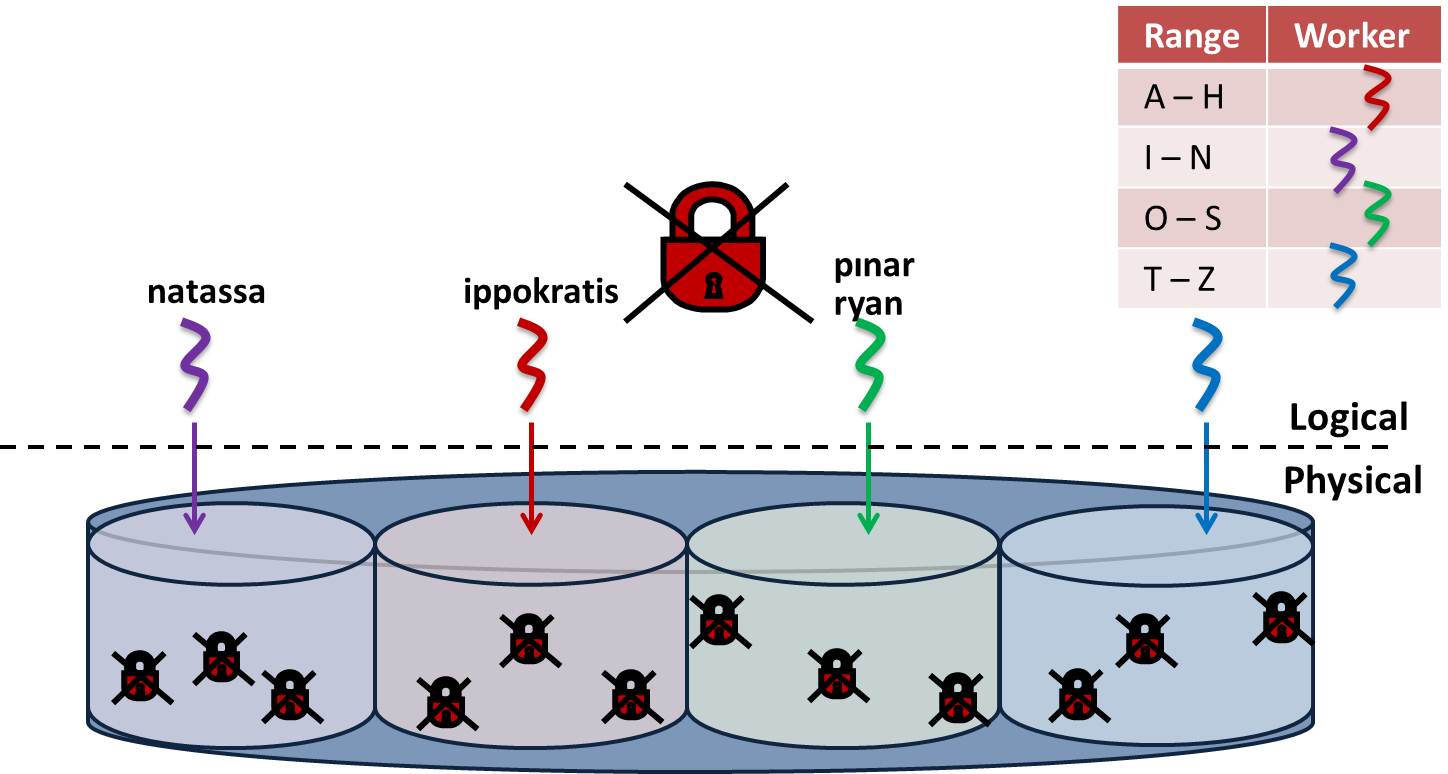
Physiological Paritioning (PLP) [1, 3]: To tackle the page latching problem, we propose physiological partitioning (PLP). The PLP design applies logical-only partitioning, maintaining the desired properties of shared-everything designs, and introduces a multi-rooted B+Tree index structure (MRBTree) which enables the partitioning of the accesses at the physical page level. Logical partitioning and MRBTrees together ensure that all accesses to a given index page come from a single thread and, hence, can be entirely latch-free; an extended design makes heap page accesses thread-private as well. Eliminating page latching allows us to simplify key code paths in the system such as B+Tree operations leading to more efficient and maintainable code. Profiling a prototype PLP system running on different multicore machines shows that it acquires 85% and 68% fewer contentious critical sections, respectively, than an optimized conventional design and one based on logical-only partitioning. PLP also improves performance up to 40% and 18%, respectively, over the existing systems.
References
- Tözün, P., Pandis, I., Johnson, F.R. and Ailamaki, A. (2012) Scalable and Dynamically Settled Shared-Everything OLTP with Physiological Partitioning. The VLDB Journal. [detailed record]
- Johnson, R., Pandis, I., Stoica, R., Athanassoulis, M. and Ailamaki, A. (2011) Scalability of write-ahead logging on multicore and multisocket hardware. The VLDB Journal, 20(6) pp. 1-25. [detailed record]
- Pandis, I., Tözün, P., Johnson, F.R. and Ailamaki, A. (2011) PLP: Page Latch-free Shared-everything OLTP. Proceedings of the VLDB Endowment, 4(11). [detailed record]
- Pandis, I., Tözün, P., Branco, M., Karampinas, D., Porobic, D., Johnson, R. and Ailamaki, A. (2011) A Data-oriented Transaction Execution Engine and Supporting Tools. Proceedings of ACM SIGMOD International Conference on Management of Data. [detailed record]
- Johnson, R., Pandis, I., Stoica, R., Athanassoulis, M. and Ailamaki, A. (2010) Aether: A scalable approach to logging. Proceedings of the 36th International Conference on Very Large Data Bases, 3(1). [detailed record]
- Pandis, I., Johnson, R., Hardavellas, N. and Ailamaki, A. (2010) Data-Oriented Transaction Execution. Proceedings of the VLDB Endowment, 3(1). [detailed record]
- Athanassoulis, M., Johnson, R., Ailamaki, A. and Stoica, R. (2009) Improving OLTP concurrency through Early Lock Release. Technical Report, 2009. [detailed record]
- Johnson, R., Pandis, I. and Ailamaki, A. (2009) Improving OLTP scalability using speculative lock inheritance. Proceedings of the VLDB Endowment, 2(1) pp. 479-489. [detailed record]
- Johnson, R., Pandis, I., Hardavellas, N., Ailamaki, A. and Falsafi, B. (2009) Shore-MT: a scalable storage manager for the multicore era. Proceedings of the 12th International Conference on Extending Database Technology, 360 pp. 24-35. [detailed record]
- Johnson, R., Pandis, I. and Ailamaki, A. (2008) Critical Sections: Re-Emerging Scalability Concerns for Database Storage Engines. 4th Workshop on Data Management on New Hardware, DaMoN 2008, Vancouver, BC, Canada, June 13, 2008, pp. 35-40. [detailed record]