| IN COLLABORATION WITH MESTRELAB RESEARCH |
Digital laboratories with high degree of automation require specific interfaces in order to capture experimental data and metadata in a structured form. Researchers should be able to contextualize as much as possible their requests and orchestrate their hardware according to their desired plan. Such interfaces do not exist as these tasks were at best done by populating ELN which are not suited for efficient database creation and limits greatly the exploitation of data using machine learning algorithms. To correct this, we develop a Human Computer Interface (HCI) designed to convert chemist inputs into scheduler and database language.
|
IN COLLABORATION WITH SWISS DATA SCIENCE CENTER |
In our purpose of generating high quality experimental datasets, it is required to contextualize and chain every process and analysis to the sequence of samples produced during an experiment. For this purpose, we are developing a format that will aggregate in an open and human readable format all the information that can be collected during compounds generation and analysis. One of the main challenge is associated with the ability to extract experimental relevant information from proprietary files of equipment suppliers and to structure it according to FAIR rules database generation.
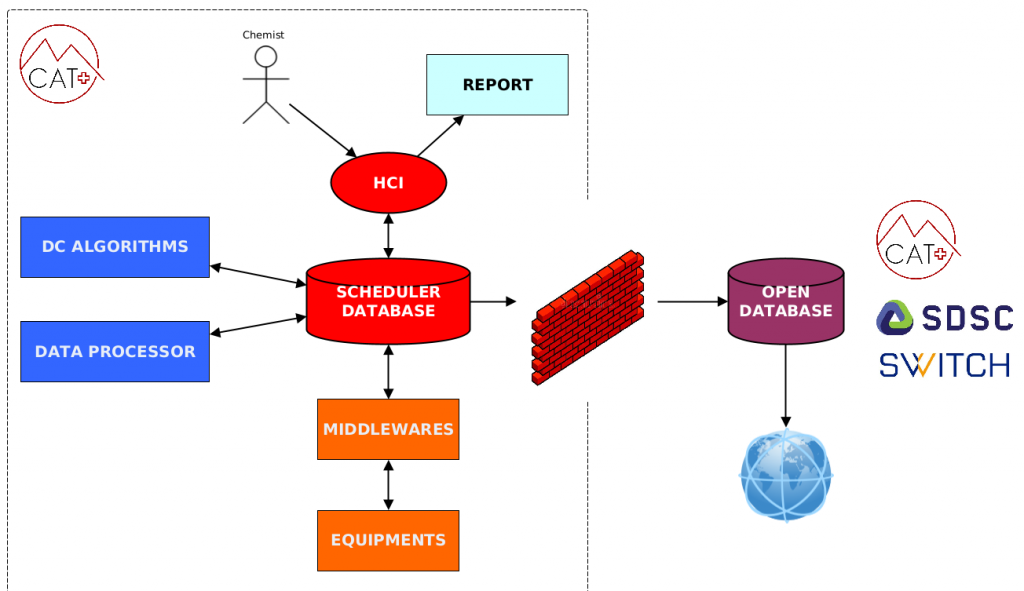
Autonomous digital labs require the synchronized orchestration of very different type of hardware and software. In order to pilot this complex architecture, we designed a simple yet efficient combination of control layers that could be generalized and applied to other labs having different configurations. Our architecture is based on a multilayer vision going bottom-up from the laboratory equipments to a series of middlewares grouping the equipments by brands then to a centralized scheduler intimately associated with our database. The scheduler database is filled by the chemist through the HCI. Another important element is the Data Processor that is connected to the scheduler and needed to process the raw data extracted from proprietary formats files to populate the Mat-file.
In order to automatize the complete analytical platform, two strategies were developed.
The first one is for high throughput screening of reaction output by offline 2D-RPLCMS-RPSFCMS . In order to gather information about enantioselectivity of reactions, the collected peaks from LC will be automatically transferred to chiral SFC analysis after concentration and solvent switch using SPE technology.
The second one is the full automated characterization of unknown detected LC peaks. In order to optimize the process, after being analyzed by high throughput LC-Ms, samples containing the highest concentration and the best quality of desired peak will be automatically selected and sent for isolation and characterization through (link) our Omnifire platform.