This section contains links to EPFL’s guidelines for conducting research that involves personal data. These guidelines are designed to help you manage personal data correctly in your research projects, protect the privacy of your data subjects and ensure you meet high data protection and research standards.
Both this website and the guidelines explain the applicable concepts and legal requirements at each stage of the data lifecycle, drawing on concrete examples from research. They also indicate who to contact at EPFL if you have a question.
At EPFL, we view personal data protection not as a set of rules to comply with but rather as a means and an opportunity to strengthen citizens’ trust in science.
An overview of personal data protection in research projects
Read the compact version of the Guidelines (PDF).
Download the complete version of the Guidelines.
Disclaimer : The information provided in the examples below does not and is not intended to constitute legal advice. Each example should be evaluated on a case-by-case issues (or legal issues more generally) you encounter.
A multi-centric project : roles and responsibilities 1
- EPFL, along with other research institutes in Switzerland and the rest of Europe, is taking part in a joint project involving health data. The project team has decided to set up a secure platform for hosting and sharing research data.
- They designated a project leader and drafted an agreement outlining the expected contribution of each research institute. EPFL will be responsible for developing the secure platform and running it on the School’s IT infrastructure, but will not provide any data.
- Once the platform is up and running, each research institute will enter the data it has collected using an agreed format and will be able to access data provided by the other institutes.
Does this project involve personal data?
Yes, it involves health data which are a category of personal data.
Definitions
- Personal data is all information relating to an identified or identifiable person.
- Data subjects are the natural persons whose data is processed.
- Sensitive personal data includes data on:
- Religious, ideological, political or trade union-related views or activities;
- Health, the intimate sphere or the racial origin;
- Social security measures;
- Administrative or criminal proceedings and sanctions
- Genetic data
- Biometric data.
Focus on Health Data
Health data are sensitive personal data and must be protected accordingly. A lack of adequate data protection can lead to significant legal, financial, reputational and research-related damage (e.g., civil or criminal proceedings).

What are the applicable laws?
The applicable laws here are the FADP (because EPFL is in Switzerland), the GDPR (because at least one other entity is in the EU and will probably process the personal data of EU residents), and the Swiss Federal Human Research Act (HRA) (because the research will involve health data).
Who is the Data Controller for this project ?
All the institutes are joint controllers
The data controller is the legal or natural person who, alone or with others, determines the purposes and the means of data processing.
In this case, the institutes should set up a data transfer agreement (i.e., data controller to data controller) as well as agreements on issues like how the research consortium will be governed, how intellectual property will be managed and how findings will be published.
What «instruments» can the researchers use to process personal data?
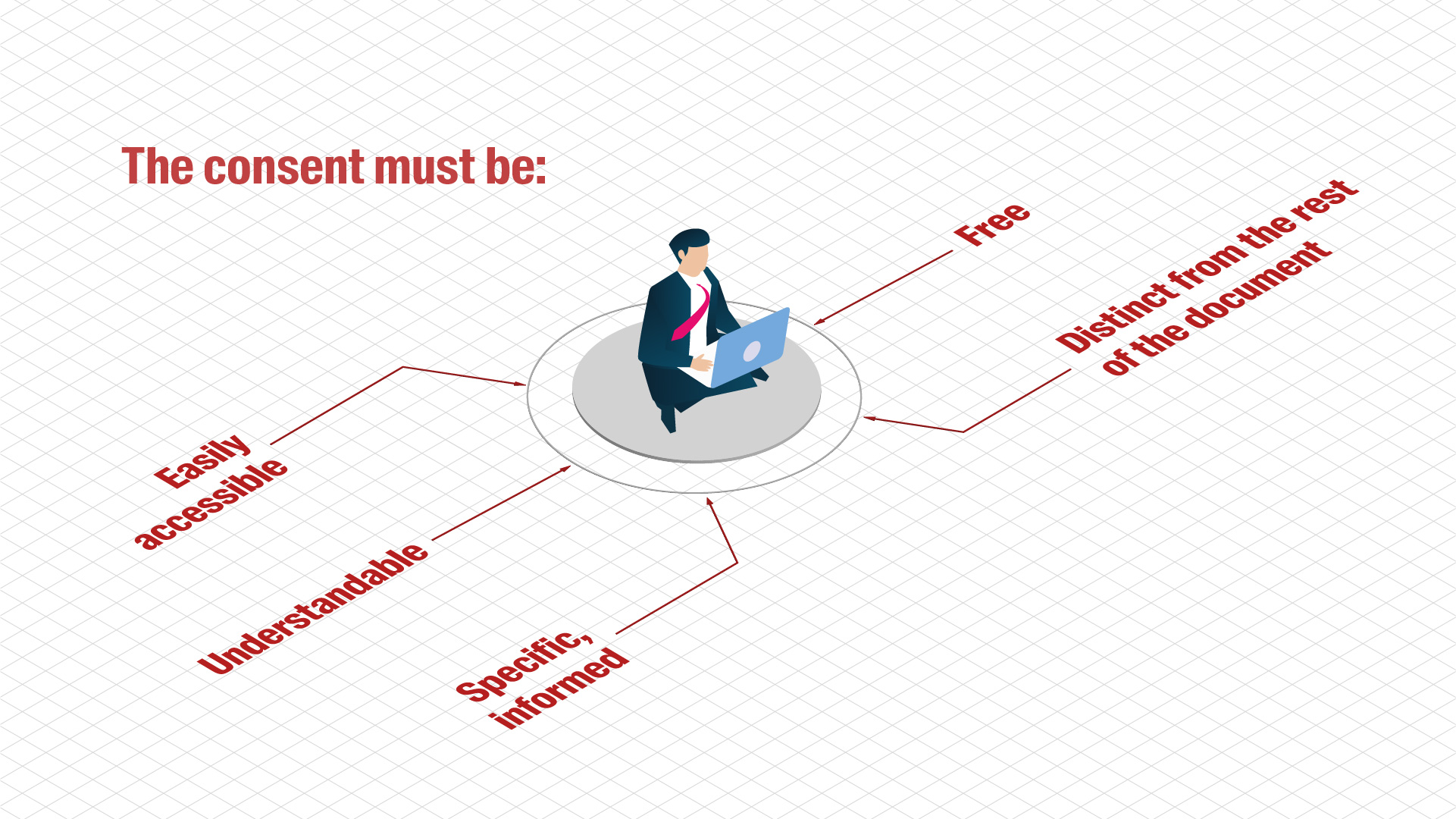
Data subjects must be asked for their consent before their personal data can be collected. Obtaining comprehensive, informed consent is a crucial requirement of research.
- The data controller must be able to prove that consent has been given.
- Data subjects have the right to withdraw their consent at any time.
- Consent is not required if the personal data processing is permitted by law or a signed contract (unless consent is required to comply with the HRA).
The Swiss Association of Research Ethics Committees (Swissethics) has developed consent templates for sensitive (including health-related) personal data. Participants in research projects have several rights with regard to their personal data, such as the right to access the data and the right to oppose the processing of the data.
If EPFL was not part of the research consortium, but was instead commissioned to only operate the platform, what would its data protection role be ?
In this case, EPFL would be a Data Processor
A data processor is an entity that carries out data processing on behalf of the data controller.
The data processor would need to enter into a specific agreement with the data controller, who would remain accountable for the data processing. The agreement should specify all the security measures that the data processor must take to protect personal data.
Be careful if you decide to use a data processor based outside Switzerland (e.g., hosting or support services, on a cloud server based in another country). EPFL employees, as employees of the Swiss federal government, must comply with official secrecy requirements (as described in Article 320 of the Swiss Criminal code).
Sensitive data, anonymization and storage in a US cloud 2
- EPFL has been mandated to develop a mobile application for detecting precancerous and cancerous cervical lesions in videos taken during visual examinations with acetic acid. In the first phase of development, engineers will create a data-collection program to capture the images needed to train the system’s artificial intelligence algorithms. Only pseudonymized data and images will be entered into the application. These data will then be uploaded to a cloud server where they will be remain anonymous.
- Because the mobile app will eventually be deployed on a large scale, the engineers need to outline a cloud data-security plan from the outset of the development work.
-
The project team includes EPFL, a Swiss hospital (principal investigator) and two foreign hospitals (where the data will be collected).
- To use the system, doctors will need to take a series of photos during a patient examination and run the photos through the system’s artificial intelligence algorithms on a smartphone or cloud server. The doctors can then use the mobile app to show the algorithm predictions to the patient.
- The app works in offline mode. Doctors can upload the collected and anonymized data to the cloud server (push) and retrieve previously uploaded data (pull).
- When doctors first log in, they will be asked to accept the terms of use.
What was the main data protection challenge in this project?
The personal data involved are sensitive (health data) and are planned to be stored on a public cloud based in the US. This is generally not permitted under Swiss data protection law; the researchers will have to anonymize the data.
Can we say that the project’s personal data were anonymized before they were transferred to the cloud-storage system?
Personal data must be anonymized before they can be stored on a public cloud. The most efficient and secure way to do this is to use a random unique identifier (UID).
The UID would be generated by the foreign hospitals and would ensure that the data are anonymized for transfer to the mobile app. No further personal data protection requirements would need to be met (anonymized data are not subject to Switzerland’s data protection law or official secrecy requirements).
However, the foreign hospitals are not able to meet the requirement for anonymized data. Due to practical and process-related reasons, the data can only be pseudonymized by the hospitals before they are transferred to the app. The EPFL engineers therefore designed a system where the data are run through a hash function before being transferred from the mobile app to the cloud.
In this case, can we say that the data transferred to the cloud have been anonymized? Theoretically, no. If a doctor were to reveal the hash function’s “recipe” to the US cloud service provider, the service provider might be able to identify the patients.
A data protection risk assessment was conducted prior to the development of the app and found that the residual risk is very low. The process proposed by the engineers was therefore deemed acceptable.
Who can access which data?
The information of the mapping table between the identifier registered (pseudonyms) in the application and the patient’s identity will be kept on the hospital’s own servers (independent of the US-based cloud server). The project administrators (EPFL) will never have access to this information.
EPFL will receive a list containing only the pseudonyms, which the project engineers can run back through the hash function in order to link the clinical information needed to train the algorithm with the corresponding images. In this way, the engineers will work only with pseudonymized data.
If a doctor wants to access or delete the data of a given patient, the doctor can hash the identifier (pseudonym) to access the corresponding data on the cloud server.
How does the hash function work?
The hash function is deterministic: it generates a unique irreversible identifier allowing to save this hash in EPFL database. More details about hash functions (Wikipedia)
What identifying information is stored on the cloud server?
Only patients’ hash ID is saved on the cloud server. If the doctor wants to access the information stored on a patient’s server, he or she can hash the ID that he or she has saved and, using the hash, access the corresponding data on the cloud server. The cloud server provider is never aware of the patient’s ID or of any patient’s real identity.
What is the EPFL role in this project?
From the data protection point of view, the EPFL acts as a data processor.
Who is responsible for collecting patients’ consent?
The foreign hospital is the organization that must obtain patients’ consent for the intended uses. The Swiss hospital is the data controller and is therefore responsible for developing and managing the consent form.
- ↑ Example adapted from Jusletter 30.08.2021, Jotterand/Erard
- ↑ thanks to Prof. Thiran, M. Cattin, G. Chevassus
More on privacy in research
In Practice

Privacy in lab/unit administration
You will find various examples that you may face, as well as good practices to adopt.