Current projects:
Training with Linear Minimization Oracles at Any Scale
Swiss National Science Foundation (2000-1-240094)
In the current landscape of deep learning, optimization methods like SGD and Adam remain foundational—but they operate under a significant limitation: they treat neural networks as black boxes, ignoring the rich structure of architectures designed with specific tasks in mind. This research project seeks to change that paradigm by introducing a unified, geometry-aware approach to optimization—one that deeply integrates architectural properties into the optimization process itself. At the heart of the project is a new class of optimization algorithms built on norm-constrained conditional gradient methods, such as stochastic Frank-Wolfe variants. These methods treat learning as a constrained optimization problem, where constraints are carefully chosen based on the geometry of the network (e.g., spectral or operator norms). This shift not only leads to more stable and efficient training but also lays the foundation for automatic generalization and hyperparameter transfer across different models and scales. One of the most innovative aspects of the plan is the SCION framework (Stochastic Conditional Gradient with Operator Norms), which leverages architectural insights—such as weight matrix norms and initialization strategies—to ensure that optimization dynamics align with the network’s design. Through this lens, widely-used optimizers like Adam can be reinterpreted and generalized into non-Euclidean settings, enabling better performance and adaptivity, especially in modern architectures like Transformers and state-space models. The research is structured around three synergistic work packages: WP1 develops the theoretical backbone: new optimization algorithms that combine the strengths of steepest descent and conditional gradient methods. These methods incorporate layer-specific constraints and adaptive stepsizes, making them not only stable but also inherently scalable. As data continues to grow exponentially, the project addresses the urgent need for more computationally efficient training methods. By aligning optimization with architecture and training dynamics, the proposed methods have the potential to cut training costs dramatically—reducing not only runtime but also environmental impact. This research represents a bold step forward: it moves beyond treating neural networks as opaque optimization targets, instead recognizing them as structured, interpretable systems. Through this deeper integration of optimization and architecture, the project promises to deliver not only faster and more robust models but also a more principled foundation for the future of machine learning.
Deep Optimisation
Swiss National Science Foundation (200021_205011)
Thanks to neural networks (NNs), faster computation, and massive datasets, machine learning (ML) is under increasing pressure to provide automated solutions to even harder real-world tasks with beyond human performance with ever faster response times due to potentially huge technological and societal benefits. Unsurprisingly, the NN learning formulations present a fundamental challenge to the back-end learning algorithms despite their scalability, in particular due to the existence traps in the non-convex optimization landscape, such as saddle points, that can prevent algorithms to obtain “good” solutions.
Our recent research has demonstrated that the non-convex optimization dogma is false by showing that scalable stochastic optimization algorithms can avoid traps and rapidly obtain locally optimal solutions. Coupled with the progress in representation learning, such as over-parameterized neural networks, such local solutions can be globally optimal. Unfortunately, we have also proved that the central min- max optimization problems in ML, such as generative adversarial networks (GANs) and distributionally robust ML, contain spurious attractors that do not include any stationary points of the original learning formulation. Indeed, algorithms are subject to a grander challenge, including unavoidable convergence failures, which explain the stagnation in their progress despite the impressive earlier demonstrations.
As a result, the proposed Deep Optimization Project (DOPE) will confront this grand challenge in ML by building unified optimization and representation foundations in how we capture functions via non-linear representations, how we set-up our learning objectives that govern our fundamental goals, and how we optimize these goals to obtain numerical solutions in scalable fashion. We contend that optimization problems, such as non-convex non-concave min-max, cannot be studied in isolation from the context they are formulated. By exploiting the properties of the representations, we can invoke structures to obtain favorable convergence or actively discover which types of external oracles are necessary to guarantee convergence to “good” solutions.
Past Projects:
Theory and Methods for Accurate and Scalable Learning Machines
Swiss National Science Foundation (407540-167319/1)
Large-Scale Sparse Bayesian Modeling, Inference, and Design
Team: Volkan Cevher [PI], Andreas Krause @ ETHZ [co-PI], Jarvis Haupt @ UMN [co-PI]
Scalable and Accurate Quantum Tomography
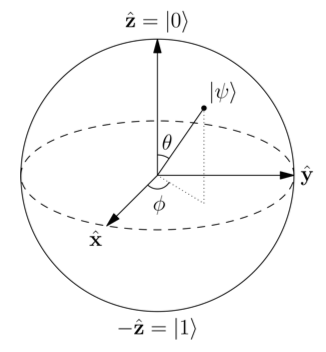
Swiss National Science Foundation (200021-146750)
Dates: 2013-2016 [PhD student: Yen-Huan Li]
Theory and methods for compressive sensing with graphical models [GM-CS]
Swiss National Science Foundation (200021-132620)
Dates: 2011-2013 [PhD student: Anastasios Kyrillidis]
Compressive sensing (CS) is an emerging alternative to Shannon/Nyquist sampling paradigm for simultaneous sensing and compression of signals having a sparse representation. By sparse representation, we mean the signal can be well approximated by a few nonzero coefficients in some basis. According to CS, the number of compressive measurements for stable recovery is proportional to the signal sparsity, rather than to its Fourier bandwidth. For this reason, CS permits revolutionary new sensing designs and algorithms for dimensionality reduction.
This project exploits probabilistic graphical models in CS as realistic signal models that can capture underlying, application dependent order of sparse coefficients, and as sampling matrices with information preserving properties that can be implemented in practical systems.