Human pose forecasting is inherently multimodal since multiple futures exist for an observed pose sequence. However, evaluating multimodality is challenging since the task is ill-posed. Therefore, we first propose an alternative paradigm to make the task well-posed. Next, while state-of-the-art methods predict multimodality, this requires oversampling a large volume of predictions. This raises key questions:
(1) Can we capture multimodality by efficiently sampling a smaller number of predictions?
(2) Subsequently, which of the predicted futures is more likely for an observed pose sequence?
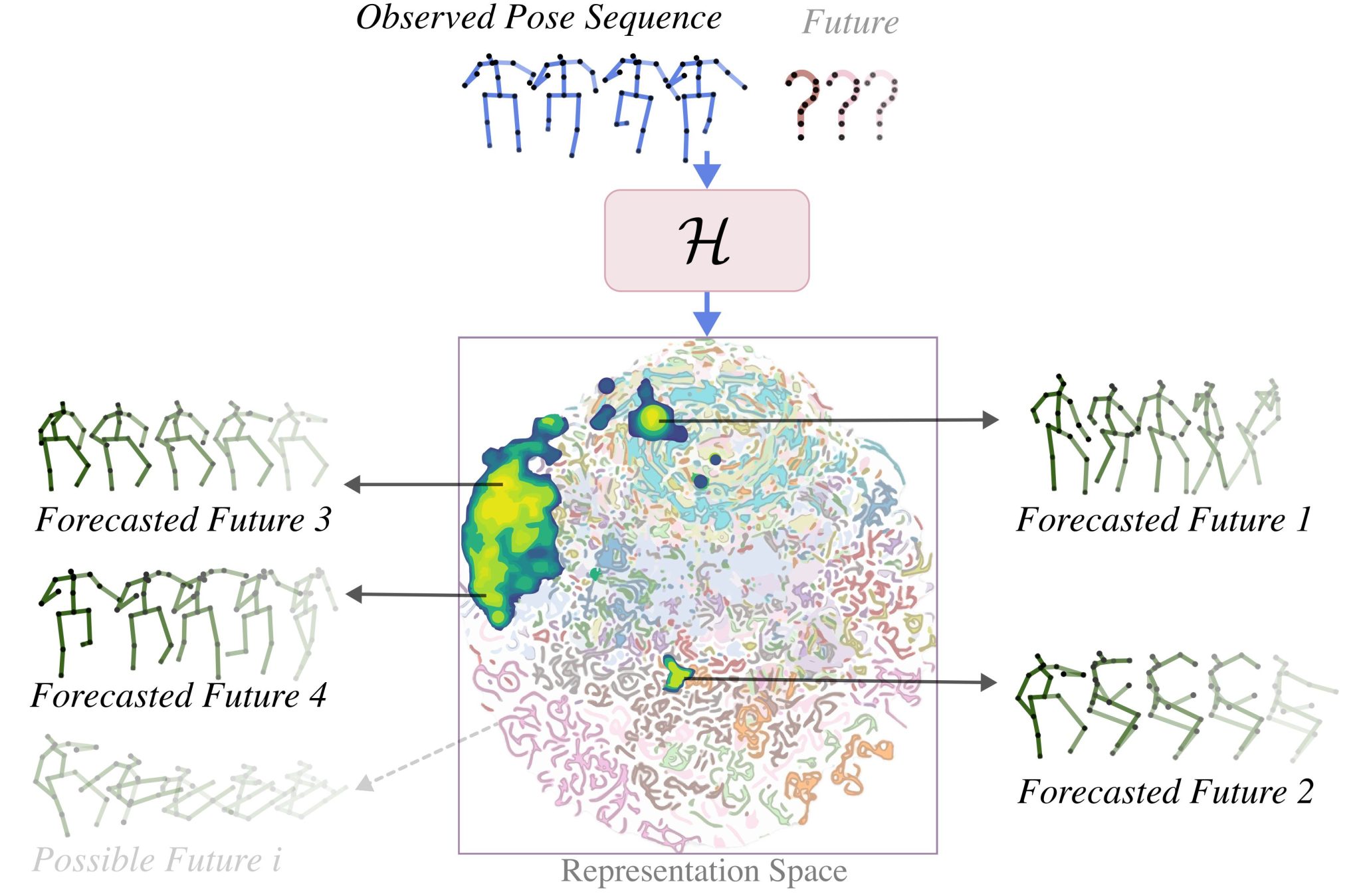
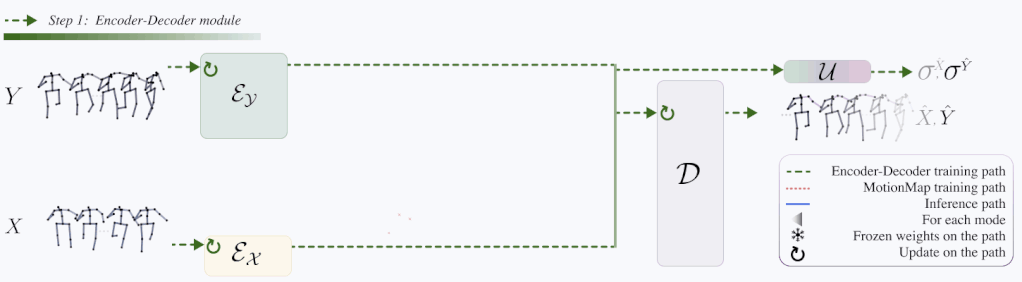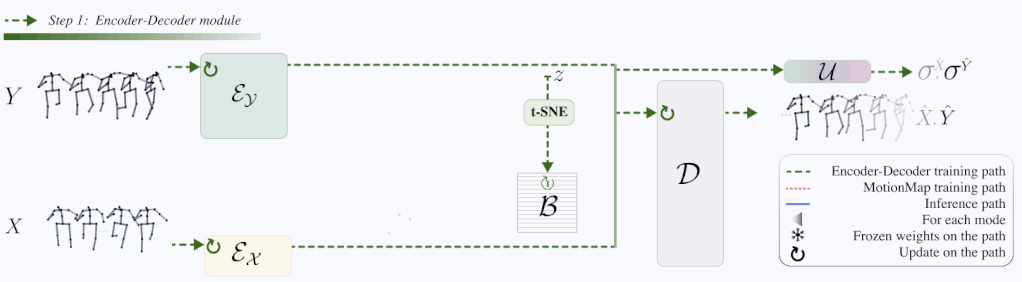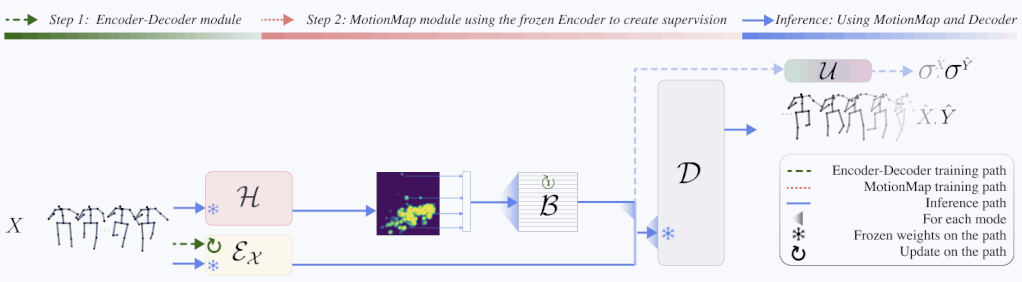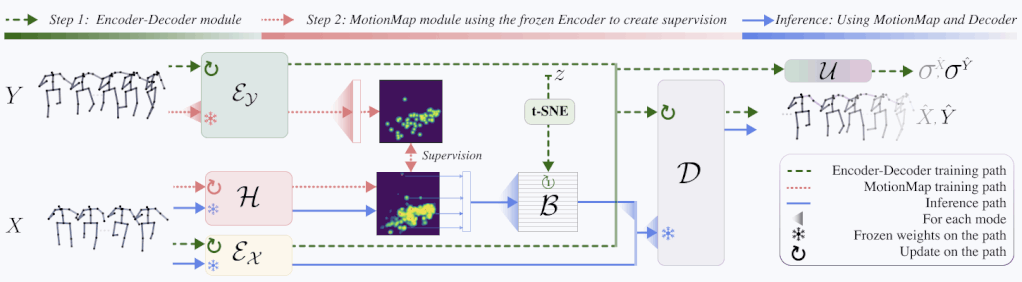
We address these questions with MotionMap, a simple yet effective heatmap based representation for multimodality. We extend heatmaps to represent a spatial distribution over the space of all possible motions, where different local maxima correspond to different forecasts for a given observation. MotionMap can capture a variable number of modes per observation and provide confidence measures for different modes. Further, MotionMap allows us to introduce the
notion of uncertainty and controllability over the forecasted pose sequence. Finally, MotionMap captures rare modes that are non-trivial to evaluate yet critical for safety. We support our claims through multiple qualitative and quantitative experiments using popular 3D human pose datasets: Human3.6M and AMASS, highlighting the strengths and limitations of our proposed method.
Architecture
Results
controllability
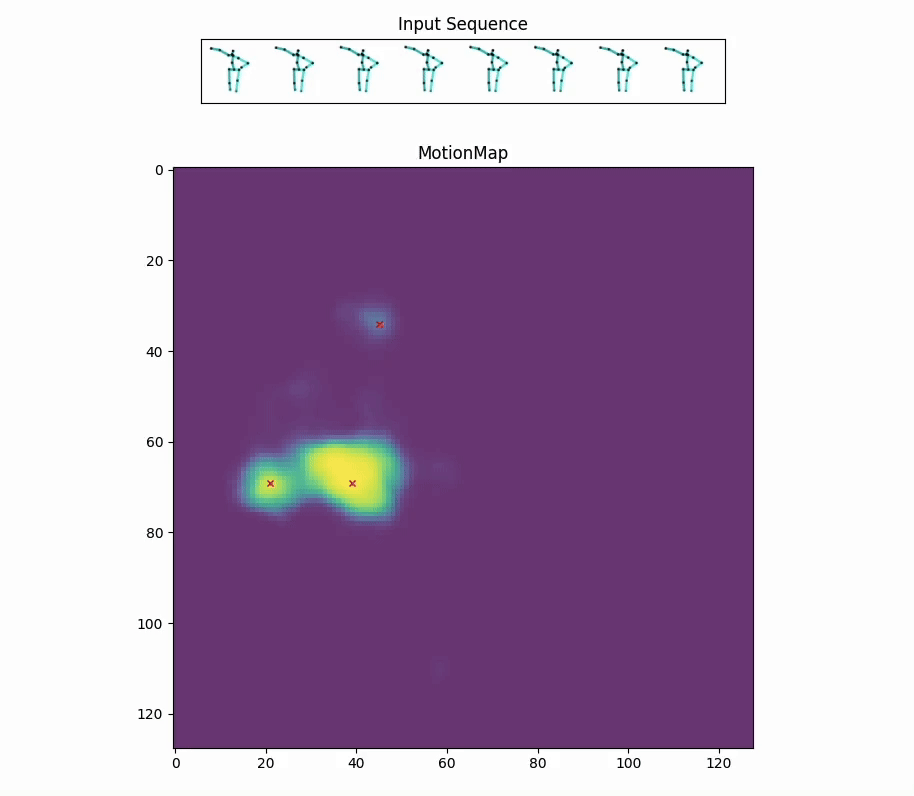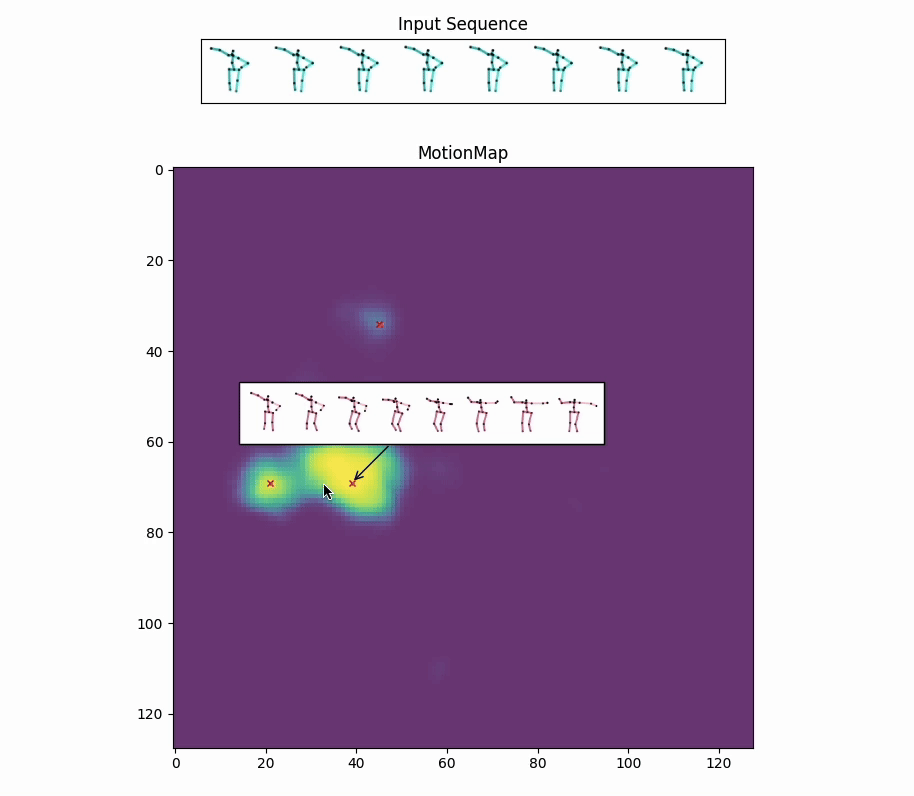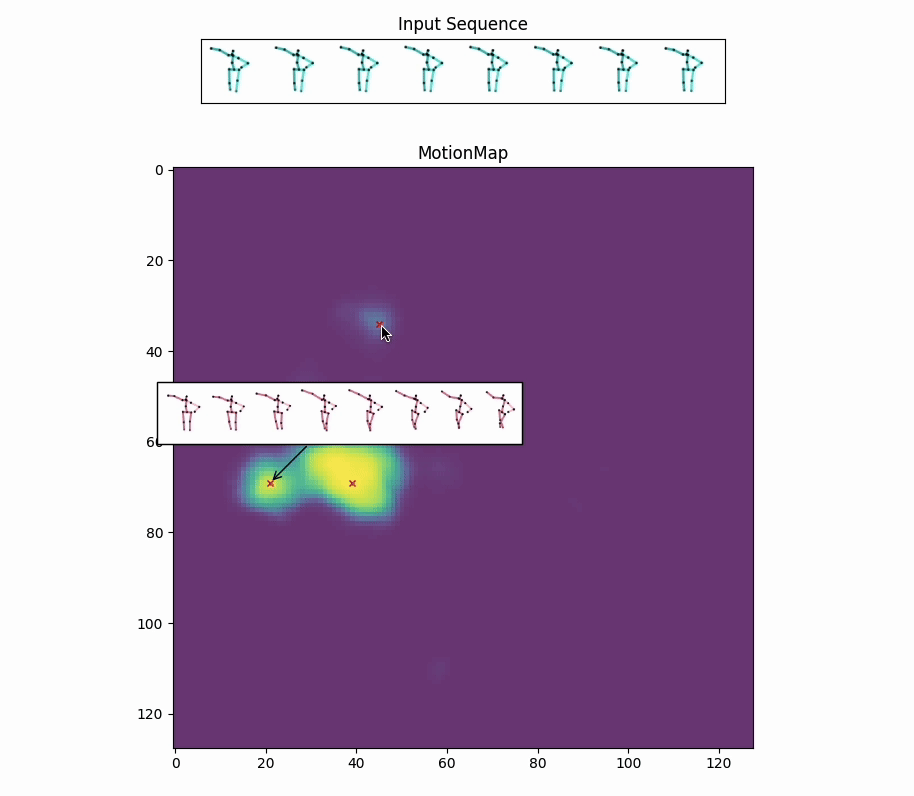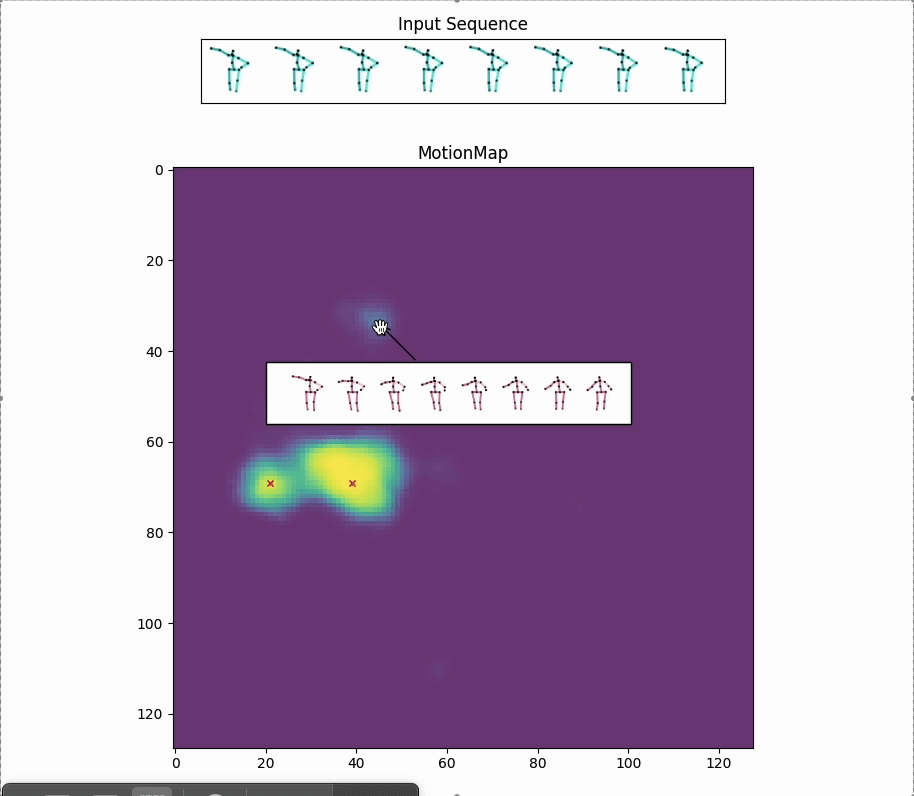
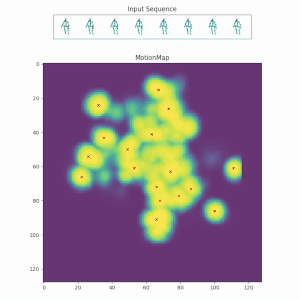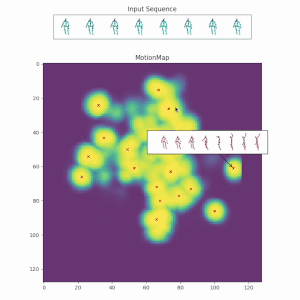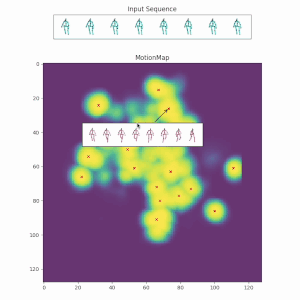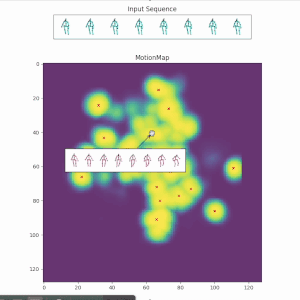
Red crosses mark the modes selected by the model. We can view the decoded future poses corresponding to the given input pose sequence by selection.
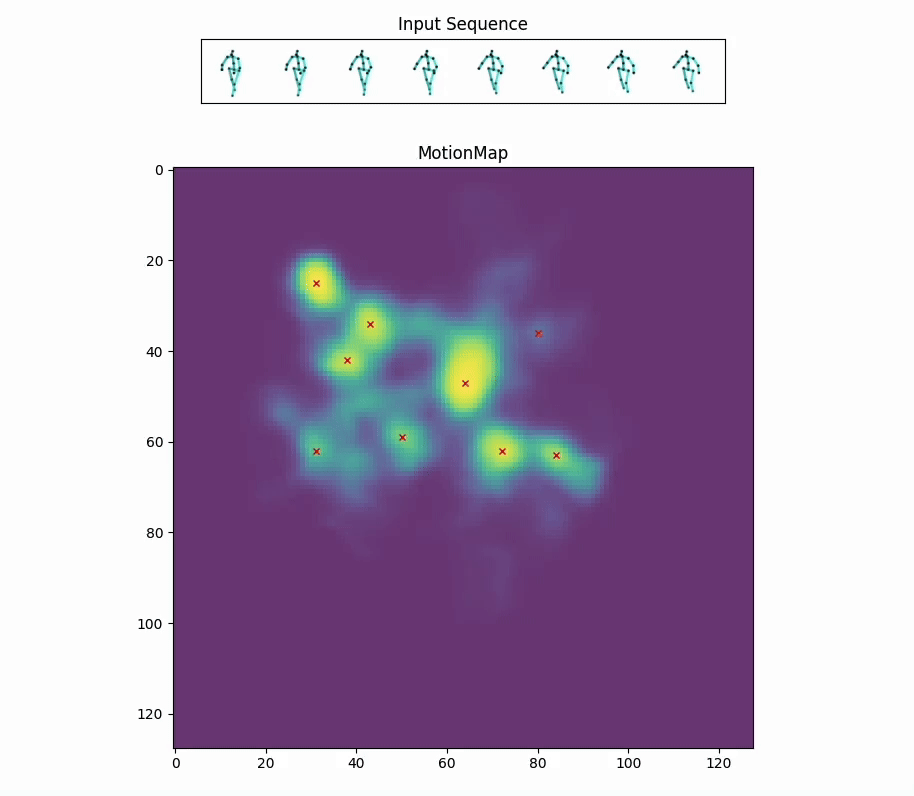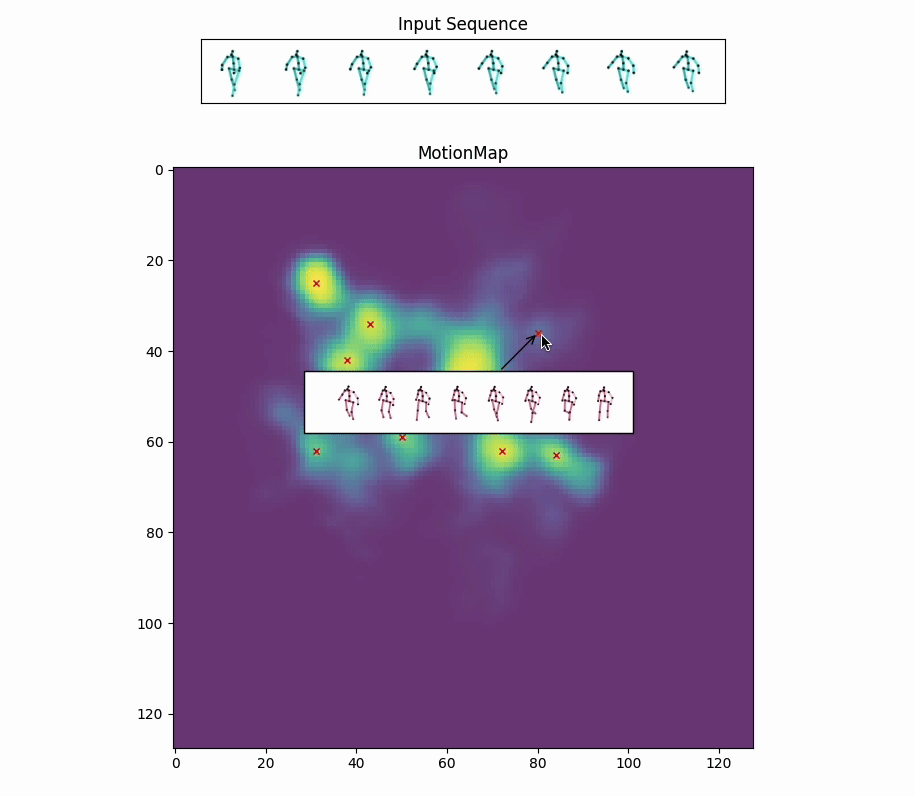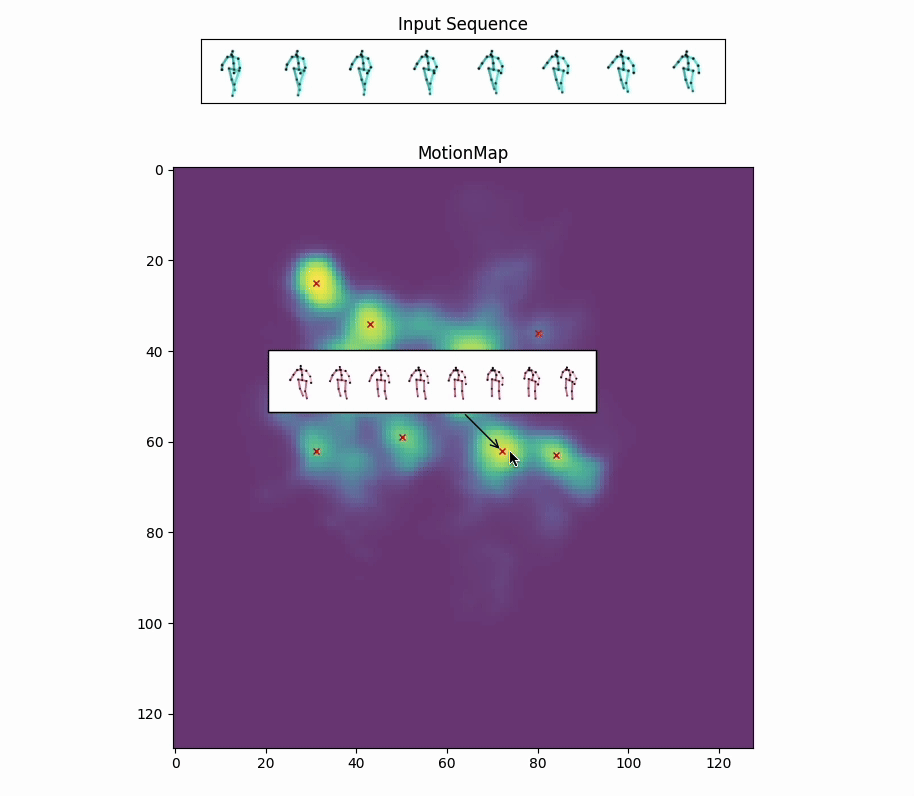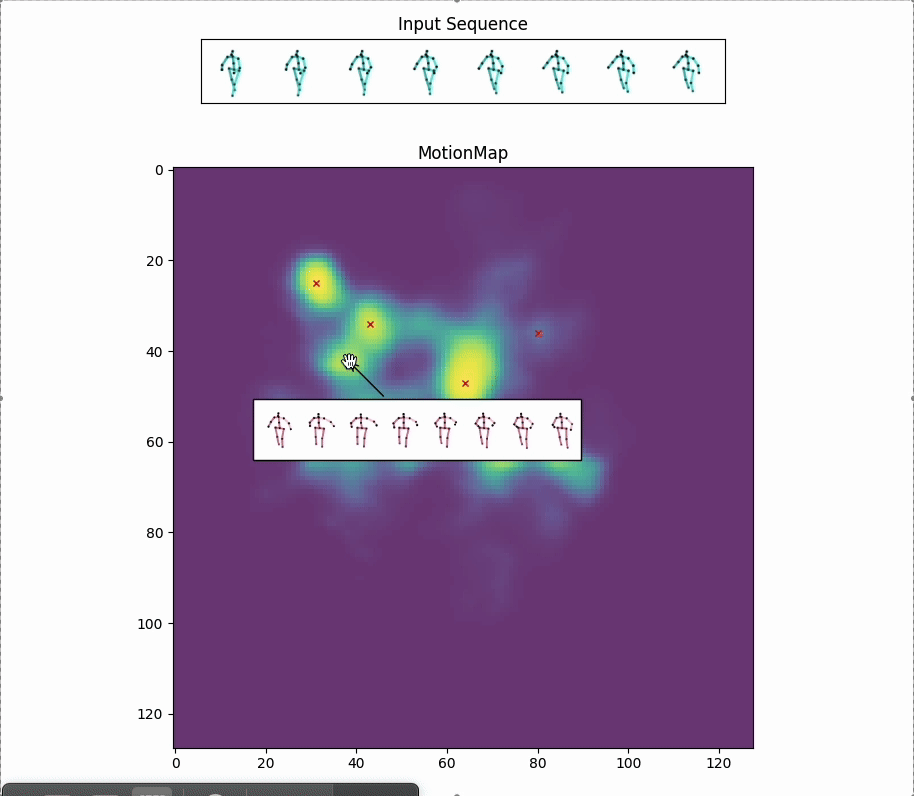
Red crosses mark the modes selected by the model. We can view the decoded future poses corresponding to the given input pose sequence by selection.

Along with the red crosses that mark the modes selected by the model,
the selection of a less likely future could be controlled by: (a) More similar modes around a selected mode. (b) Based on the distribution of the data. For instance, this could involve generating futures close to actions such as sitting down. Because these modes are usually considered less likely, they might sometimes lead to unnatural motions, especially when a smooth transition is not easy within the given future timeframe.
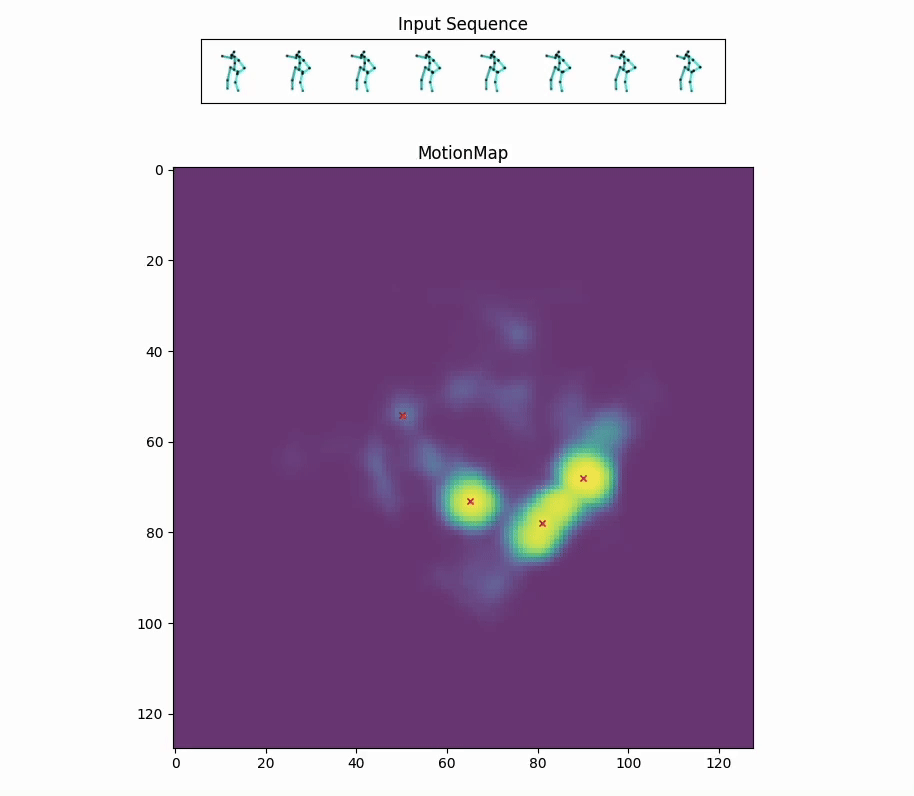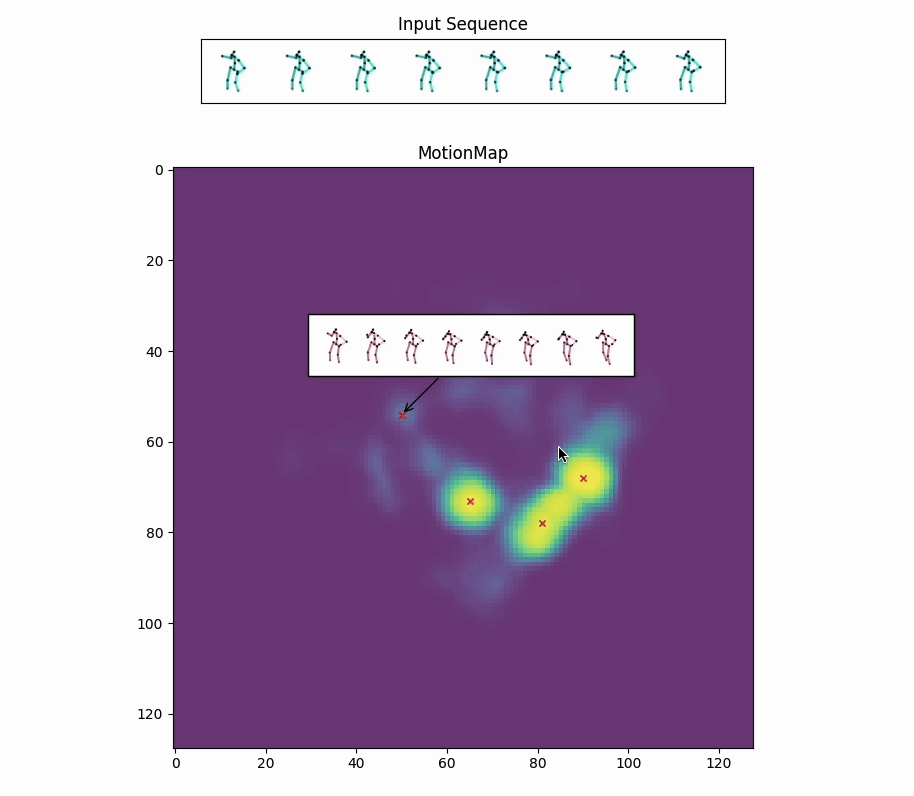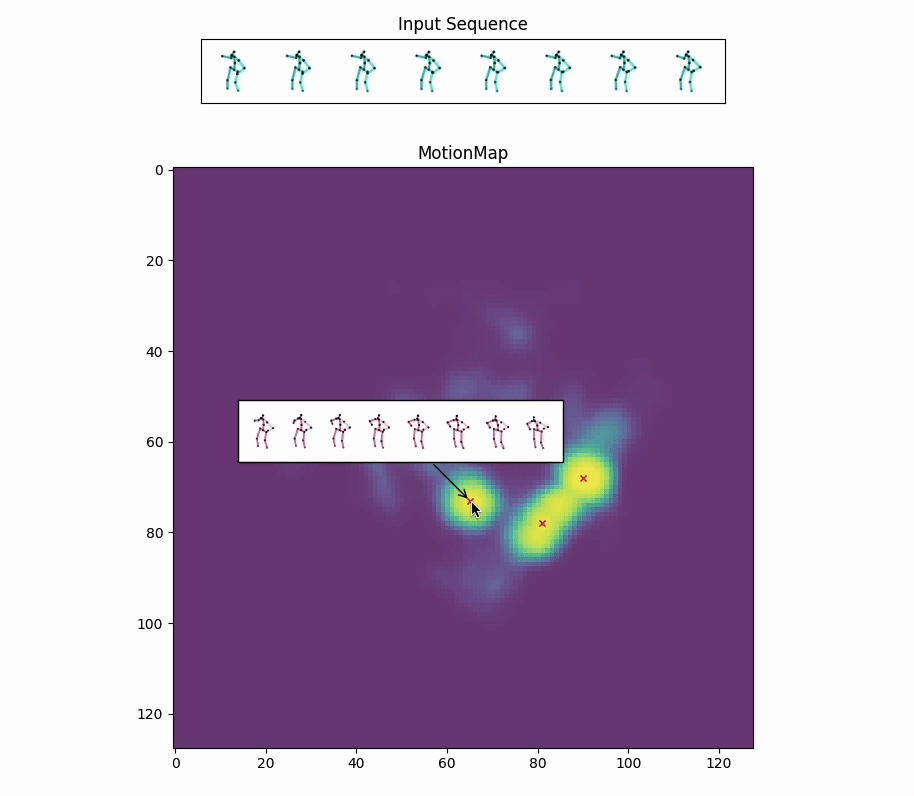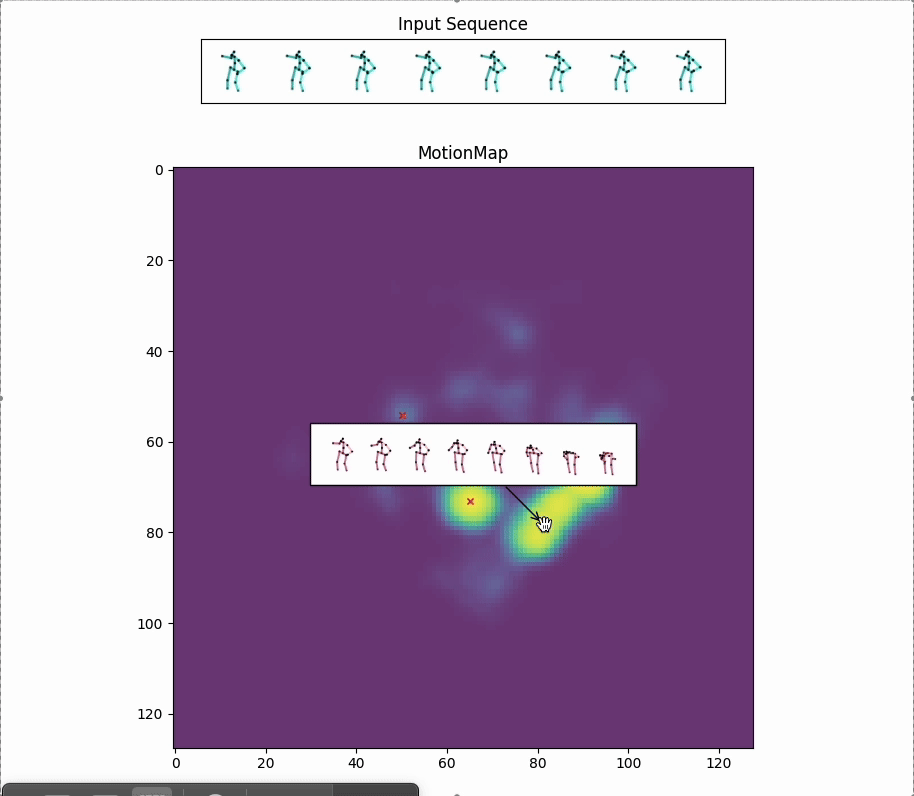
Red crosses mark the modes selected by the model. We can view the decoded future poses corresponding to the given input pose sequence by selection.

Red crosses mark the modes selected by the model. We can view the decoded future poses corresponding to the given input pose sequence by selection.




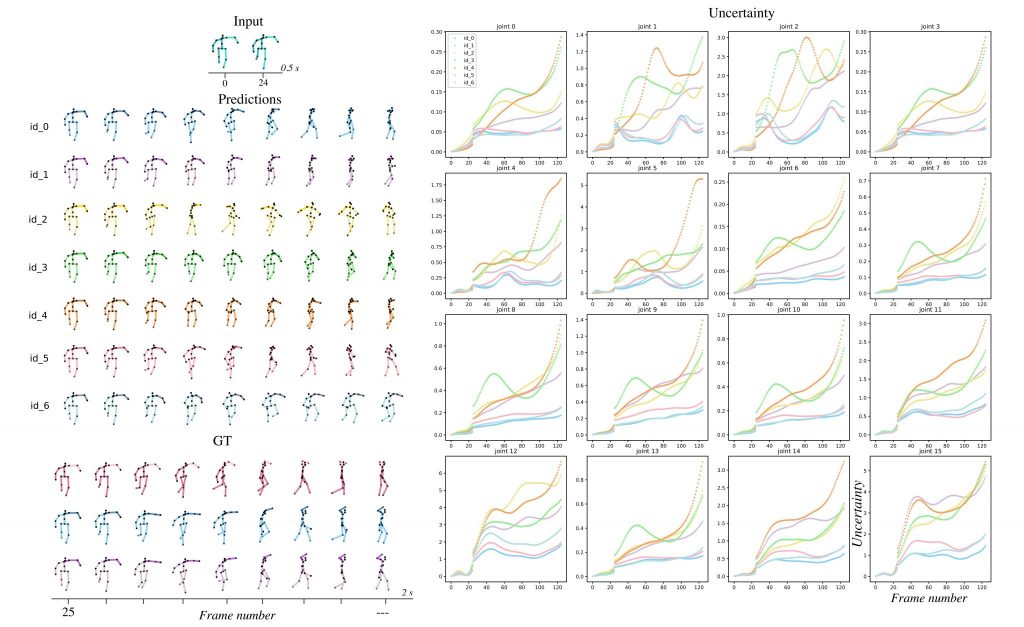
Uncertainty
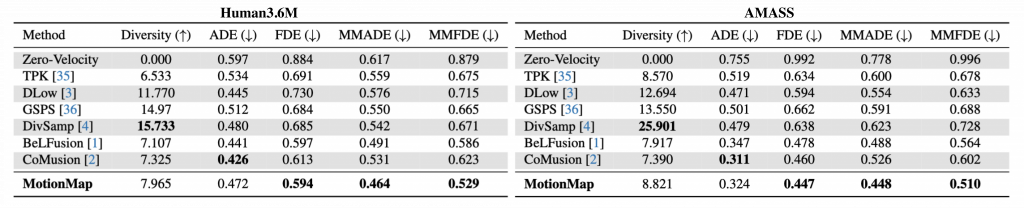
Quantitative