Prof. Florence Graezer Bideau a encadré des projets de semestre d’étudiant·e·s dont les sujets sont liés aux principaux axes de recherche du groupe Patrimoine, Anthropologie et Techniques.
Une sélection des derniers travaux figure ci-dessous :
Florence Graezer Bideau supervised students’ semester projects, focusing on the main research areas of the Heritage, Anthropology and Technologies research group.
A selection of the last projects is listed below:
Résumé des interviews Montreux Jazz Memories
Mathieu Mognol

Ce projet de bachelor s’est concentré sur l’exploitation de plus de 800 interviews du Montreux Jazz Festival, collectées dans le cadre du programme Montreux Jazz Memories. Les données, issues de transcriptions automatiques, présentaient de nombreuses erreurs et un manque d’organisation. L’objectif était double :
Développer un processus automatisé de nettoyage et de correction des transcriptions (détection de la langue, vérification via dictionnaires et listes de noms propres, corrections phonétiques et par distance de Levenshtein) afin d’obtenir un texte fiable.
Concevoir un outil de résumé automatique utilisant des modèles d’IA, notamment GPT-3, pour produire des synthèses concises (<1000 caractères) et extraire des mots-clés pertinents.
Le résultat final inclut une application Python (MJM_App) permettant la recherche par mots-clés, la consultation des résumés et la génération de nouvelles synthèses. Ce travail facilite l’accès aux informations clés pour les chercheurs, contribue à la préservation du patrimoine culturel du festival et constitue un modèle reproductible pour la gestion de grands corpus qualitatifs.
This bachelor’s project focused on processing over 800 interviews from the Montreux Jazz Festival, collected within the Montreux Jazz Memories program. The dataset, originating from automatic transcriptions, contained numerous errors and lacked organization. The project had two main goals:
Develop an automated pipeline for cleaning and correcting transcripts (language detection, dictionary and proper noun list checks, phonetic corrections, and Levenshtein distance adjustments) to produce reliable text.
Design an AI-based summarization tool, using models such as GPT-3, to generate concise summaries (<1000 characters) and extract relevant keywords.
The final outcome includes a Python application (MJM_App) enabling keyword-based search, summary browsing, and on-demand generation of new summaries. This tool significantly improves access to key information for researchers, supports the preservation of the festival’s cultural heritage, and serves as a replicable framework for managing large qualitative datasets.
Hop on the train! – Interactive platform to explore the collection of Montreux Jazz Memories interviews and synthesize interconnected stories
Daniele Belfiore
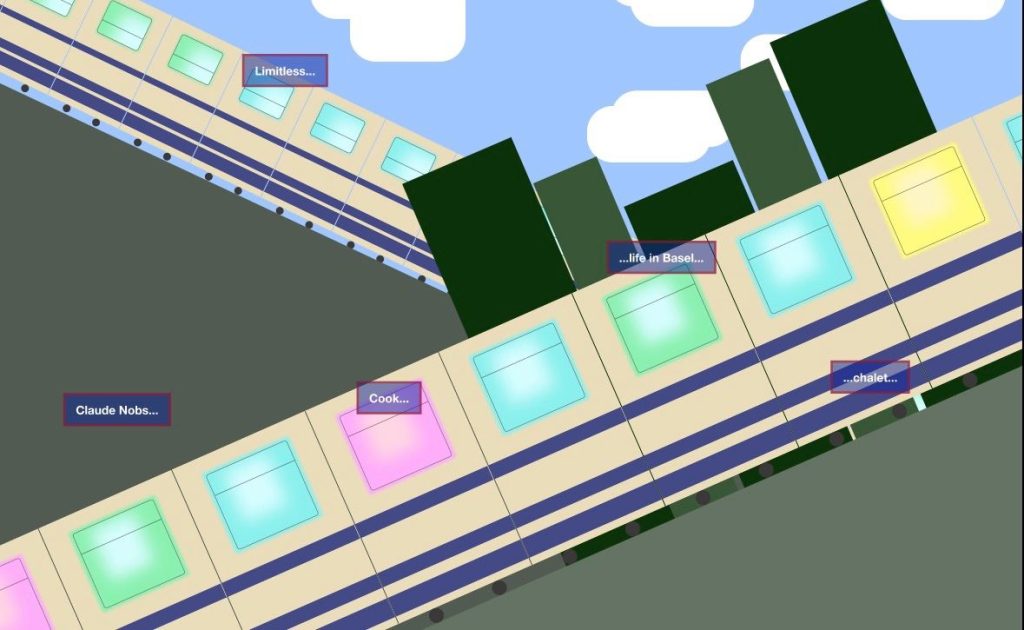
“Hop on the train!” est un projet de semestre du master en Digital Humanities, conçu pour explorer la collection d’interviews des Montreux Jazz Memories d’une manière interactive, en connectant les différentes interviews pour synthétiser des nouvelles histoires. Un système d’intelligence artificielle a utilisé les Large Language Models pour traiter plus de 400 transcriptions – en nettoyant les textes et en les classant par 6 thématiques différentes – puis a synthétisé six récits originaux (un pour chaque sujet) qui révèlent de nouveaux points de vue des personnes ayant vécu le festival. Le prototype se déploie sous la forme d’une exhibition interactive qui démontre un voyage en train : chaque thème devient une ligne, chaque wagon représente un·e interviewé·e, et chaque trajet livre un récit généré de manière inédite. Dans ce report, on voit toutes les expérimentations qui ont permis de réaliser la pipeline pour les textes et les inspirations pour le design finale.
“Hop on the train!” is a semester project from the Digital Humanities master, conceived to explore the interviews archive of the Montreux Jazz Memories project in an interactive fashion, by interconnecting all the different interviews to synthesise new stories. An AI pipeline leverages Large Language Model to process over 400 transcriptions – to clean the texts and classify them into 6 different themes – and then synthesises 6 original stories (one per topic) to unveil new points of view from the people who experienced the festival. The prototype is deployed as an interactive exhibition which is based on a set of train journeys: each train line is a story, and each wagon represents an interviewee and their information. In this way, the full train ride tells a story that is data driven and that has never been read before. In this report, you’ll see the experiments that lead to the final AI pipeline to process the texts and all the inspiration and concepts that lead to the final design.