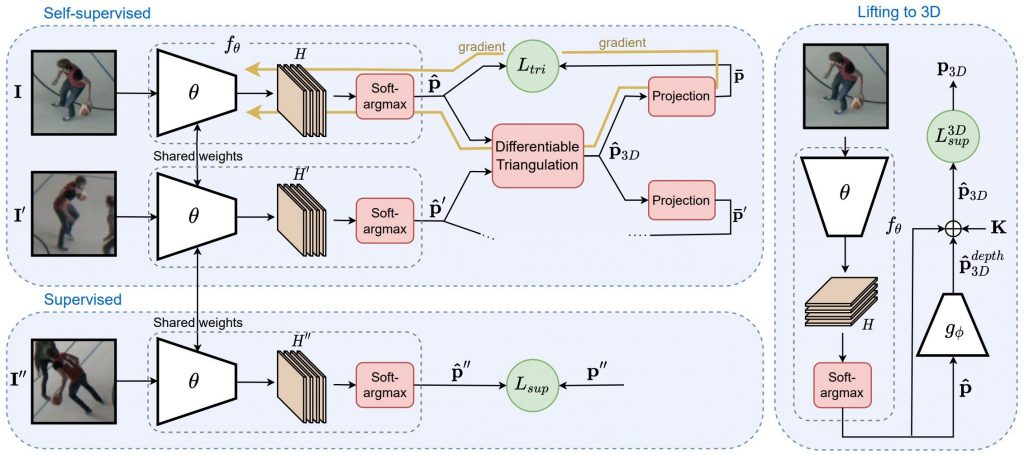
Supervised approaches to 3D pose estimation from single images are remarkably effective when labeled data is abundant. Therefore, much of the recent attention has shifted towards semi and (or) weakly supervised learning. Generating an effective form of supervision with little annotations still poses major challenges in crowded scenes. However, since it is easy to observe a scene from multiple cameras, we propose to impose multi-view geometrical constraints by means of a differentiable triangulation and to use it as form of self-supervision during training when no labels are available. We therefore train a 2D pose estimator in such a way that its predictions correspond to the re-projection of the triangulated 3D one and train an auxiliary network on them to produce the final 3D poses. We complement the triangulation with a weighting mechanism that nullify the impact of noisy predictions caused by self- occlusion or occlusion from other subjects [1].
Next steps
- Enforce consistency across time for the triangulated 3D pose using Graph Convolution Neural Networks (GCNNs) [2].
- Explicitly model “spatial/temporal occlusion” using [3].
- If time permits, enforcing time consistency of the predicted 2D pose for each viewpoint will be an added bonus.
References
[1] Roy, S. K., Citraro, L., Honari, S., & Fua, P. (2022). “On Triangulation as a Form of Self-Supervision for 3D Human Pose Estimation“. arXiv preprint arXiv:2203.15865.
[2] Zhang, Ziwei, Peng Cui, and Wenwu Zhu. “Deep learning on graphs: A survey.” IEEE Transactions on Knowledge and Data Engineering (2020).
[3] Durasov, Nikita, Timur Bagautdinov, Pierre Baque, and Pascal Fua. “Masksembles for uncertainty estimation.” CVPR 2021.
Prerequisites
- The candidate should have Python programming experience.
- Previous experience with deep learning and PyTorch, is recommended.
- Knowledge of the working of GCNNs is a plus.