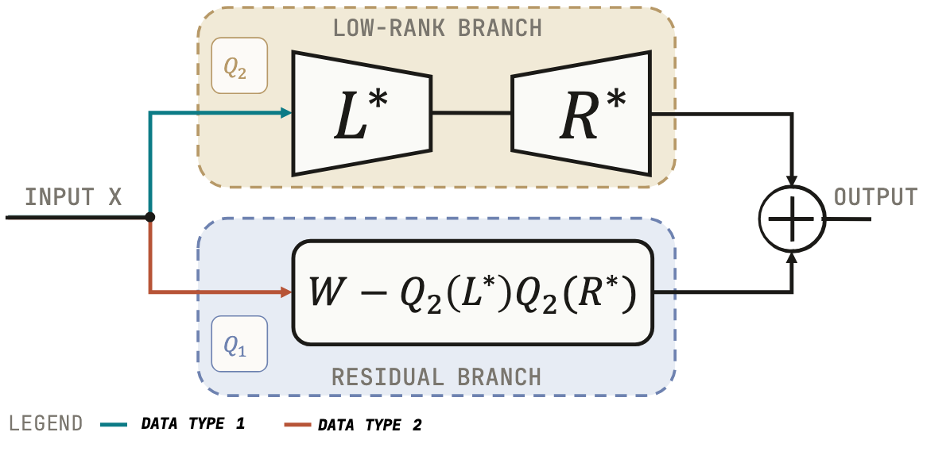
Large diffusion transformers are everywhere, and they are expensive. Running them on constrained hardware means quantizing them, and aggressive low-bit quantization tends to wreck generative quality because the iterative denoising process amplifies every small perturbation. Our work, LoRAQ (Low-Rank Approximated Quantization), tackles this by splitting each linear layer into a quantized part and a small low-rank branch that absorbs the quantization error. The result is a fully sub-16-bit pipeline that beats the state of the art at equal memory cost, with an open-source library behind it.
The current method makes one deliberate, almost stubborn choice that keeps it cheap and accessible. That choice works, and it is also exactly where the most interesting question still hides. There is room to push the low-rank branch further, to rethink what we are really optimizing for, and to ask whether the objective we use today is the right one at all. Your contribution would have a concrete baseline to beat and a credible path to publication. You would get to know a codebase, run experiments that settle a genuine open question, and shape the direction of the follow-up work.
If you like systems that are mathematically clean but judged by whether the images look good, and you want a project where strong engineering and a sharp research question are the same task, come talk to me. The interesting part is the conversation we have not had yet.
Concretely, you would:
- Learn the codebase from the inside. We built a framework for modular emulated quantization on DiT transformer blocks with multi-GPU calibration. You start by running it, reading it, and breaking it, until you are the person best placed to say what should change next.
- Build LoRAQ v2. Stress the limits of v1, sharpen the method, and extend the framework.
- Optional, depending on your appetite. A second paper built on the same codebase from a different angle on calibration. We would iterate on it together to make it more robust and ready for publication.