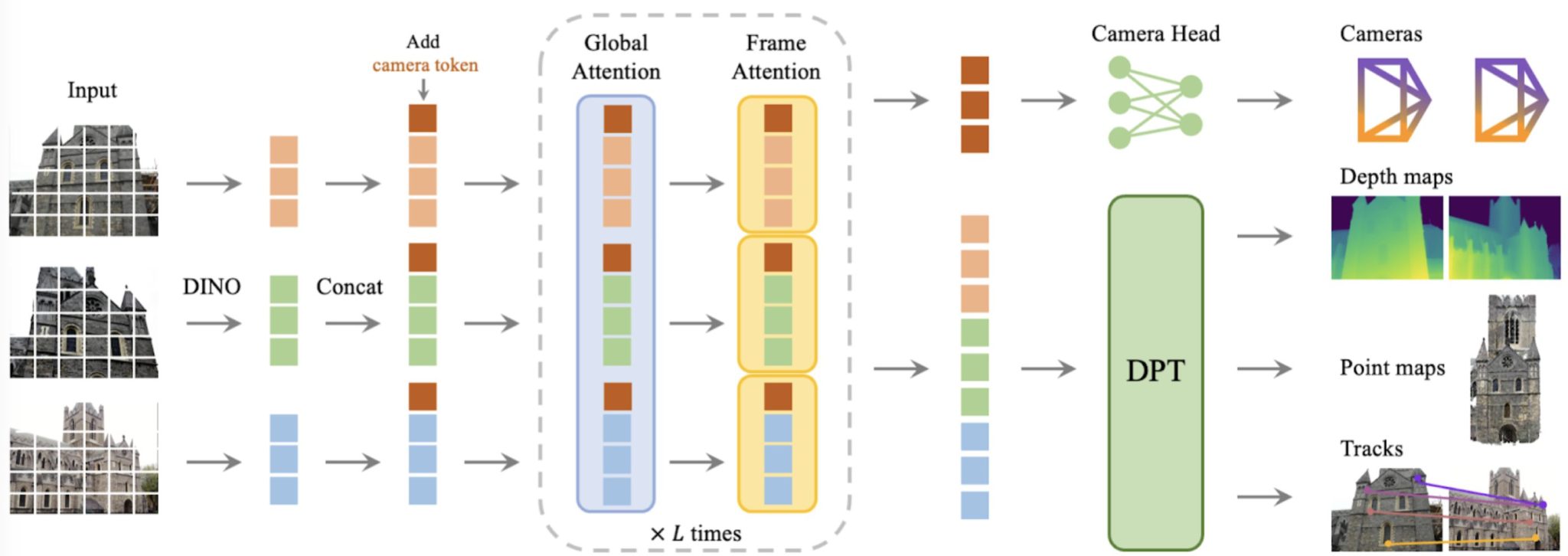
Recently, the task of 3D reconstruction has been revolutionized with the advent of VGGT (https://vgg-t.github.io/), a 3D foundation model that predicts scene geometry and camera parameters with only a transformer-based feed-forward network.
However, transformers are known to be expensive to use, especially when the input consists of hundreds of images. This project aims to dig into the use of transformers in the VGGT model, understanding the mechanism and potentially devising better algorithms to make the model faster and more accurate.
In the reference, we provide another paper that showcases an example of studying and improving transformers.
Prerequisites
- Proficiency in Python programming language
- Familiarity with deep learning and PyTorch
- Knowledge about the basics of 3D computer vision
Contact
Interested students can send an email to [email protected]. Please also include your CV and transcript.
References
[1]. VGGT: Visual Geometry Grounded Transformer. https://arxiv.org/pdf/2503.11651, CVPR 2025
[2]. QuadTree Attention for Vision Transformers. https://arxiv.org/pdf/2201.02767, ICLR 2022