Recently, the task of 3D reconstruction has been revolutionized by the advent of 3D foundation models that predict scene geometry and camera parameters using only a transformer-based feed-forward network.
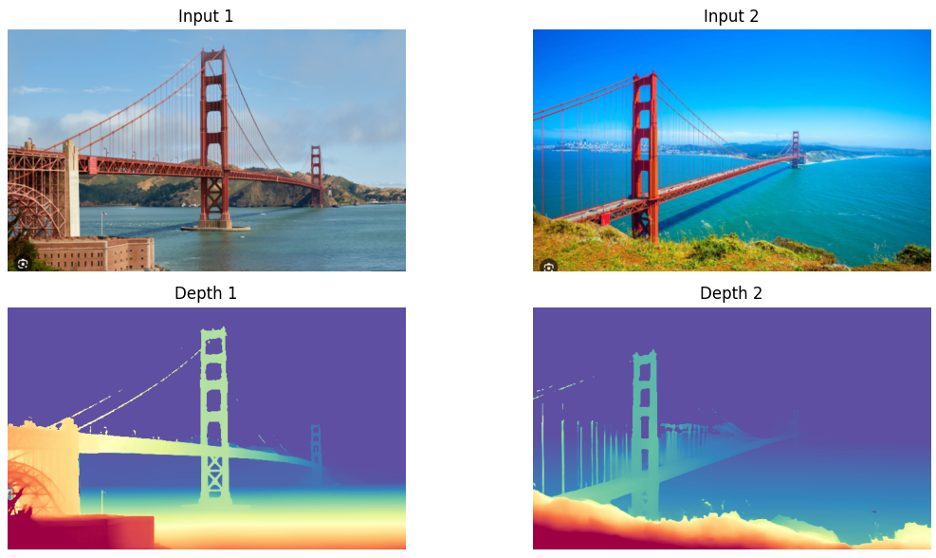
However, transformers are known to be less effective on thin structures, primarily because of the rough patchification. We provide an example using the state-of-the-art model DepthAnything3 (https://depth-anything-3.github.io/) as follows:
Objectives
In this project, we will investigate how to improve the model’s performance on thin structures.
Prerequisites
- Proficiency in Python programming language
- Familiarity with deep learning and PyTorch
- Knowledge about the basics of 3D computer vision
Contact
-
Interested students can email [email protected]. Please also include your CV and transcript.
References
[1]. VGGT: Visual Geometry Grounded Transformer. https://arxiv.org/pdf/2503.11651, CVPR 2025
[2]. Depth Anything 3: Recovering the Visual Space from Any Views. https://arxiv.org/abs/2511.10647, ICLR 2026